[Routine] 7 주차 시작!
![[Routine] 7 주차 시작!](/assets/img/daily/routine/2023/2023-03-05/2023-03-05-myroutine-7th.png)
“2023년 2월 27일 부터 3월 05일 까지의 나의 루틴.”
#목차
2023-02-27

- 오늘도 어김없이 영한 님의 인강을 들으면서 출근하였다.
- 스프링의 핵심원리 기초편이라 아는 부분이 많아서 따로 코드를 작성하지 않으려 한다.
- 내가 모르는 부분이 있을때 코드로 작성하려고 한다.
컬렉션 자료구조(Set)
Set Collection
List컬렉션은 저장 순서를 유지하지만,Set컬렉션은 저장 순서가 유지되지 않는다.- 또한 객체를 중복해서 저장할 수 없고, 하나의
null만 저장할 수 있다. Set컬렉션은 수학의 집합에 비유될 수 있다. 집합은 순서와 상관없고 중복이 허용되지 않기 때문이다.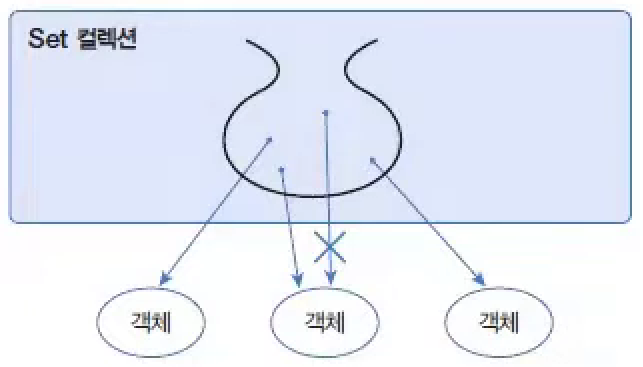
| 기능 | 메서드 | 설명 |
|---|---|---|
| 객체 추가 | boolean add(E e) | 주어진 객체를 성공적으로 저장하면 true를 리턴하고 중복 객체면 false를 리턴 |
| 객체 검색 | boolean contains(Object o) | 주어진 객체가 저장되어 있는지 여부 |
isEmpty() | 컬렉션이 비어있는지 조사 | |
Iterator<E> iterator() | 저장된 객체를 한 번씩 가져오는 반복자 리턴 | |
int size() | 저장된 모든 객체를 삭제 | |
| 객체 삭제 | void clear() | 저장된 모든 객체를 삭제 |
boolean remove(Object o) | 주어진 객체를 삭제 |
HashSet
Set컬렉션 중에서 가장 많이 사용되는 것이HashSet이다.HashSet은 동일한 객체는 중복 저장하지 않는다. 여기서 동일한 객체란 동등 객체를 말한다.HashSet은 다른 객체라도hashCode()메서드의 리턴값이 같고,equals()메서드가true를 리턴하면 동일한 객체라고 판단하고 중복 저장하지 않는다.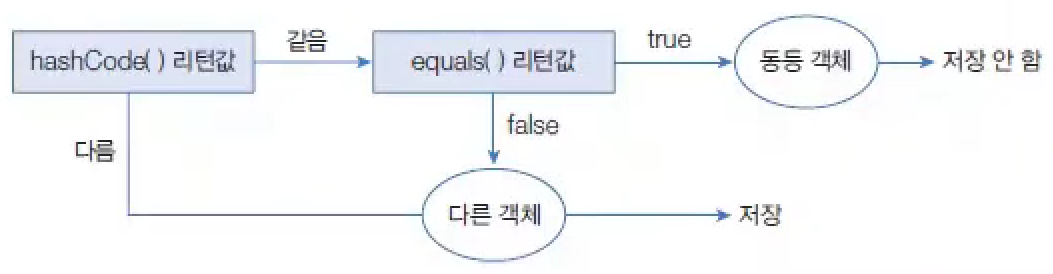
public class Set {
Set<E> set = new HashSet<E>(); // E에 지정된 타입의 객체만 저장
Set<E> set = new HashSet<>(); // E에 지정된 타입의 객체만 저장
Set set = new HashSet(); // 모든 타입의 객체를 저장
}
Set컬렉션은 인덱스로 객체를 검색해서 가져오는 메서드가 없다. 대신 객체를 한 개씩 반복해서 가져와야 하는데, 여기에는 두 가지 방법이 있다.
//file: "for 문을 이용한 방법.java"
public class SetUsingFor {
public static void main(String[] args) {
Set<E> set = new HashSet<E>();
for (E e : set) {
System.out.println("for Set : " + e);
}
}
}
Set컬렉션의iterator()메서드로 반복자(iterator)를 얻어 객체를 하나씩 가져오는 것. 타입 파라미터E는Set컬렉션에 저장되어 있는 객체의 타입이다.
//file: "set.iterator()를 사용하는 방법.java"
public class SetIterator {
Set<E> set = new HashSet<E>();
Iterator<E> iterator = set.iterator();
}
iterator는Set컬렉션의 객체를 가져오거나 제거하기 위해 다음 메서드를 제공.
| 리턴 타입 | 메서드 명 | 설명 |
|---|---|---|
boolean | hasNest() | 가져올 객체가 있으면 true를 리턴하고 없으면 false를 리턴한다. |
E | next() | 컬렉션에서 하나의 객체를 가져온다 |
void | remove() | next()로 가져온 객체를 Set 컬렉션에서 제거한다. |
- 사용방법
public class UsingHashNext {
public static void main(String[] args) {
while (iterator.hasNext()) {
E e = iterator.next();
}
}
}
Continue with HashSet Commit
Map Collection
Map컬렉션은 키key와 값value으로 구성된 엔트리Entry개게를 저장한다. 여기서 키와 값은 모두 객체이다. 키는 중복 저장할 수 없지만 값은 중복 저장할 수 있다.- 기존에 저장된 키와 동일한 키로 값을 저장하면 기존의 값은 없어지고 새로운 값으로 대치된다.
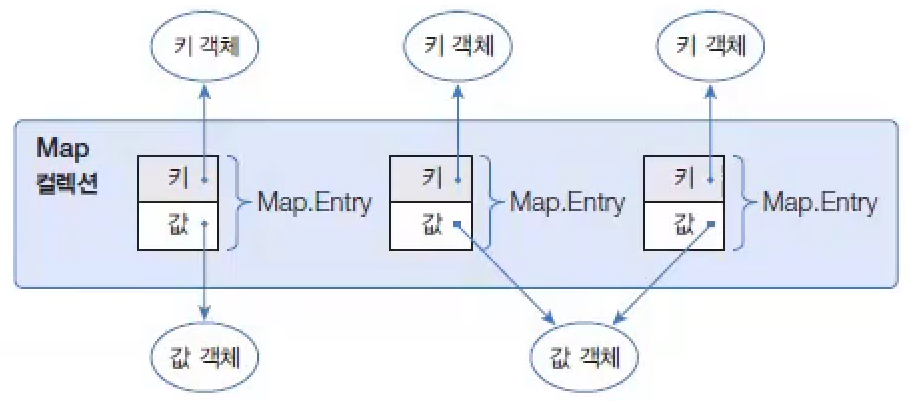
| 기능 | 메서드 | 설명 |
|---|---|---|
| 객체 추가 | V put(K key, V value) | 주어진 키와 값을 추가, 저장이 되면 값을 리턴 |
| 객체 검색 | boolean containsKey(Object key) | 주어진 키가 있는지 여부 |
boolean containsValue(Object key) | 주어진 값가 있는지 여부 | |
Set<Map.Entry<K, V>> entrySet() | 키와 값의 쌍으로 구성된 모든 Map.Entry 객체를 Set에 담아서 리턴 | |
V get(Object key) | 주어진 키의 값을 리턴 | |
boolean isEmpty() | 컬렉션이 비어있는지 여부 | |
Set<k> keySet() | 저장된 키의 총 수를 리턴 | |
int size() | 저장된 키의 총 수를 리턴 | |
Collection<V> values() | 저장된 모든 값 Collection에 담아서 리턴 | |
| 객체 삭제 | void clear() | 모든 Map.Entry(키와 값)를 삭제 |
V remove(Object key) | 주어진 키와 일치하는 Map.Entry 삭제, 삭제가 되면 값을 리턴 |
HashMap
HashMap은key로 사용할 객체가hashCode()메서드의 리턴값이 같고equalse()메서드가true를 리턴할 경우, 동일 키로 보고 중복 저장을 허용하지 않는다.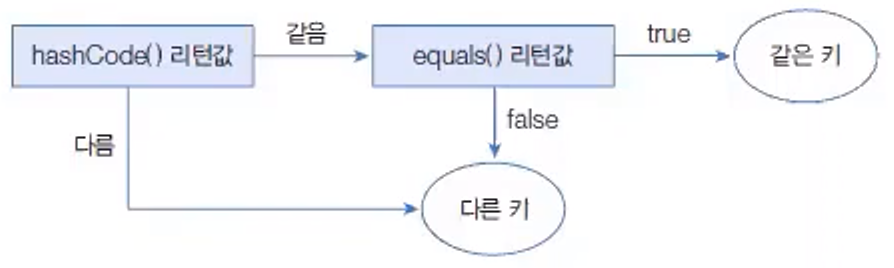
public class HashMap {
Map<String, Integer> map = new HashMap<String, Integer>(); // Key는 String 타입만, Value 값은 Integer만 가능
Map<String, Integer> map = new HashMap<>();
}
Continue with HashMap Commit
Hashtable
Hashtable은HashMap과 동일한 내부 구조를 가지고 있다. 차이점은Hashtable은 동기화된(synchronized) 메서드로 구성되어 있기 때문에 멀티 스레드가 동시에Hashtable의 메서드들을 실행할 수 없다는 것이다.- 따라서 멀티 스레드 환경에서도 안전하게 객체를 추가, 삭제할 수 있다.
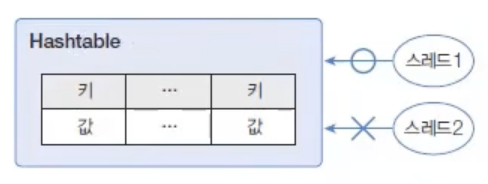
public class Hashtable {
Map<String, Integer> map = new HashMap<String, Integer>();
Map<String, Integer> map = new HashMap<>();
Map map = new HashMap(); // <- 해당 경우는 거의 없다.
}
Continue with Hashtable Commit
2023-02-28

- 늦잠을 자버렸다…😅
- 어김없이 영한 님의 인강과 함께 출근을 하였다.
- 오늘
HashSet다시 복습을 하는데for문과iterator에서의 차이점을 새로 알게 되었다. - 간략하게 말하자면
for문은 몇 번 반목할지 이미 알고 있는 상태. 즉, 반복문 실행 중 반복할 횟수의 대상을 제거하면Exception이 발생하게 된다. 이때for문이 아닌iterator을 사용해야 한다.
// file: "IteratorRemoveErrorExample.java"
public class IteratorRemoveError {
public static void main(String[] args) {
Set<String> whileSet = new HashSet<String>();
whileSet.add("Java");
whileSet.add("Spring");
whileSet.add("JDBC");
whileSet.add("JPA");
// 에러 예제 for 문
for (String element : whileSet) {
System.out.println("객체를 하나씩 가져와서 처리 element : " + element);
// 에러 예제
if (element.equals("Java")) {
whileSet.remove(element);
// exception 발생
// Exception in thread "main" java.util.ConcurrentModificationException
// at java.base/java.util.HashMap$HashIterator.nextNode(HashMap.java:1597)
// at java.base/java.util.HashMap$KeyIterator.next(HashMap.java:1620)
// at ch15.collection_framwork.HashSetExample.main(HashSetExample.java:73)
}
}
}
}
- 위 문제 발생을 아래와 같이 해결 할 수 있다.
public class IteratorRemoveTroubleshooting {
public static void main(String[] args) {
// file: "IteratorRemoveTroubleshootingExample.java"
Set<String> whileSet = new HashSet<String>();
whileSet.add("Java");
whileSet.add("Spring");
whileSet.add("JDBC");
whileSet.add("JPA");
// 문제 해결 예제
Iterator<String> iterator = whileSet.iterator();
while (iterator.hasNext()) {
String element = iterator.next();
System.out.println("while() element : " + element);
if (element.equals("Spring")) {
iterator.remove();
}
}
}
}
컬렉션 자료구조(Set)
Map Collection
Properties
Properties는Hashtable의 자식 클래스이기 때문에Hashtable의 특징을 그대로 가지고 있다.Properties키와 값을String타입으로 제한한 컬렉션이다.Properties는 주로 확장자가.properties인 프로퍼티 파일을 읽을 때 사용한다.- 프로퍼티 파일은 다음과 같이 키와 값이
=기호로 연결되어 있는 텍스트 파일이다. - 일반 텍스트 파일과 다르게
ISO 8859-1문자셋으로 저장되며, 한글이리 경우에는\u+유니코드로 표현되어 저장된다.
# file: "database.properties"
driver=oracle.jdbc.OracleDriver
url=jdbc:oracle:thin:@localhost:1521:orcl
username=java
paswsord=java
admin=\uD64D\uAE38\uB3D9
public class Properties {
public static void main(String[] args) {
Properties properties = new Properties();
properties.load(XXX.class.getResourceAsStream("database.properties"));
}
}
Continue with Properties Commit
검색 기능을 강화시킨 컬렉션을
- 컬렉션 프레임워크는 검색 기능을 강화시킨
TreeSet과TreeMap을 제공한다. 이름에서 알 수 있듯이TreeSet은Set컬렉션이고,TreeMap은Map컬렉션이다.
TreeSet
TreeSet은 이진 트리binary tree를 기반으로 한Set컬렉션이다. 이진 트리는 여러 개의 노드node가 트리 형태로 연결된 구로조, 루트 노드root node라고 불리는 하나의 노드에서 시작해 각 노드에 최대 2개의 노드를 연결할 수 있는 구조를 가지고 있다.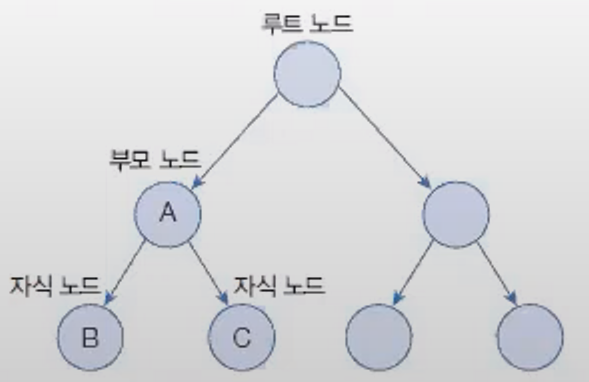
TreeSet에 객체를 저장하면 다음과 같이 자동으로 정렬된다. 부모 노드의 객체와 비교해서 낮은 것은 왼쪽 자식 노드에, 높은 것은 오른쪽 자식 노드에 저장한다.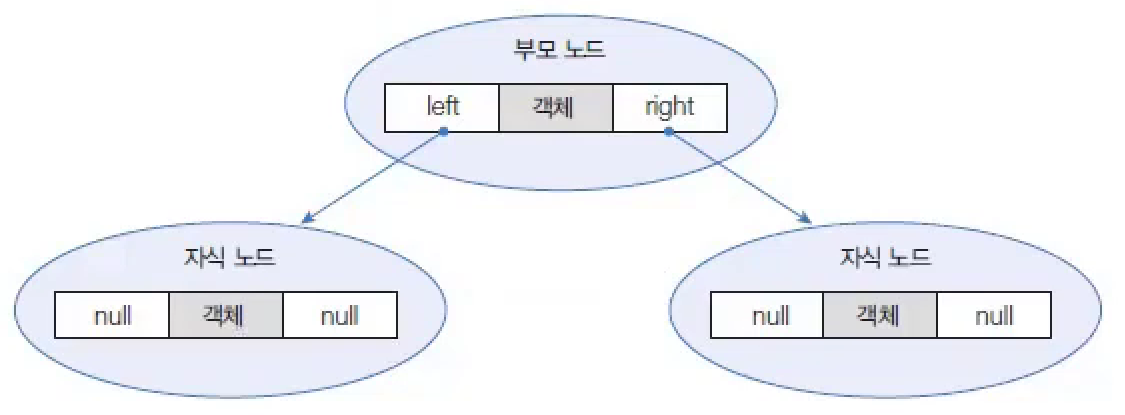
public class TreeSet {
TreeSet<E> treeSet = new TreeSet<E>();
TreeSet<E> treeSet = new TreeSet<>();
}
| <div style="width:150px">리턴 타입</div> | <div style="width:200px">메서드</div> | 설명 |
|---|---|---|
E | first() | 제일 낮은 객체를 리턴 |
E | last() | 제일 높은 객체를 리턴 |
E | lower(E e) | 주어진 객체보다 바로 아래 객체를 리턴 |
E | higher(E e) | 주어진 객체보다 바로 위 객체를 리턴 |
E | floor(E e) | 주어진 객체와 동등한 객체가 있으면 리턴, 만약 없다면 주어진 객체의 바로 아래의 객체를 리턴 |
E | ceiling(E e) | 주어진 객체와 동등한 객체가 있으면 리턴, 만약 없다면 주어진 객체의 바로 위의 객체를 리턴 |
E | pollFirst() | 제일 낮은 객체를 꺼내오고 컬렉션에서 제거함 |
E | pollLast() | 제일 높은 객체를 꺼내오고 컬렉션에서 제거함 |
Iterator<E> | descendingIterator() | 내림차순으로 정렬된 Iterator를 리턴 |
NavigableSet<E> | descendingSet() | 내림차순으로 정렬된 NavigableSet을 리턴 |
NavigableSet<E> | headSet(E toElement,boolean inclusive} | 주어진 객체보다 낮은 객체들을 NavigableSet으로 리턴, 주어진 객체 포함 여부는 두 번째 매개값에 따라 달라짐 |
NavigableSet<E> | tailSet(E toElement,boolean inclusive} | 주어진 객체보다 높은 객체들을 NavigableSet으로 리턴, 주어진 객체 포함 여부는 두 번째 매개값에 따라 달라짐 |
NavigableSet<E> | tailSet(E toElement,boolean inclusiveE toElement,boolean toInclusive} | 시작과 끝으로 주어진 객체 사이의 객체들을 NavigableSet으로 리턴, 시작과 끝 객체의 포함 여부는 두 번째,네 번째 매개값에 따라 달라짐 |
Continue with TreeSet Commit
TreeMap
TreeMap은 이진 트리를 기반으로 한Map컬렉션이다.TreeSet과의 차이점은 키와 값이 저장된Entry를 저장한다는 점이다.TreeMap에 엔트리를 저장하면 키를 기준으로 자동 정렬되는데, 부모 키 값과 비교해서 낮은 것은 왼쪽, 높은 것은 오른쪽 자식 노드에Entry객체를 저장한다.
public class TreeMap {
TreeMap<K, V> treeMap = new TreeMap<K, V>();
TreeMap<K, V> treeMap = new TreeMap<>();
}
| <div style="width:170px">리턴 타입</div> | <div style="width:200px">메서드</div> | 설명 |
|---|---|---|
Map.Entry | firstEntry() | 제일 낮은 Map.Entry를 리턴 |
Map.Entry | lastEntry() | 제일 높은 Map.Entry를 리턴 |
Map.Entry | lowerEntry(K key) | 주어진 키보다 바로 아래 Map.Entry를 리턴 |
Map.Entry | higherEntry(K key) | 주어진 키보다 바로 위 Map.Entry를 리턴 |
Map.Entry | floorEntry(K key) | 주어진 키와 동등한 키가 있으면 해당 Map.Entry를 리턴, 없다면 주어진 키 바로 아래의 Map.Entry를 리턴 |
Map.Entry | ceilingEntry(K key) | 주어진 키와 동등한 객체가 있으면 해당 Map.Entry를 리턴, 없다면 주어진 키의 바로 위의 Map.Entry를 리턴 |
Map.Entry | pollFirst() | 제일 낮은 Map.Entry를 꺼내오고 컬렉션에서 제거함 |
Map.Entry | pollLast() | 제일 높은 Map.Entry를 꺼내오고 컬렉션에서 제거함 |
NavigableSet<E> | descendingKeySet() | 내림차순으로 정렬된 키의 NavigableSet을 리턴 |
NavigableMap<K, V> | descendingMap() | 내림차순으로 정렬된 Map.Entry의 NavigableMap을 리턴 |
NavigableMap<K, V> | headMap(K toKey,boolean inclusive) | 주어진 키보다 낮은 Map.Entry들을 NavigableMap으로 리턴, 주어진 키의 Map.Entry 포함 여부는 두 번째 매개값에 따라 달라짐 |
NavigableMap<K, V> | tailMap(K toKey,boolean inclusive) | 주어진 객체보다 높은 Map.Entry들을 NavigableSet으로 리턴, 주어진 객체 포함 여부는 두 번째 매개값에 따라 달라짐 |
NavigableMap<K, V> | subMap(K toKey,boolean inclusive,K toKey,boolean toInclusive) | 시작과 끝으로 주어진 키 사이의 Map.Entry들을 NavigableMap컬렉션으로 반환, 시작과 끝 키의 Map.Entry 포함 여부는 두 번째,네 번째 매개값에 따라 달라짐 |
Continue with TreeMap Commit
2023-03-01
- 9시 30분까지 늦잠을 잤다…😁
컬렉션 자료구조(Set)
검색 기능을 강화시킨 컬렉션
Comparable 과 Comparator
TreeSet에 저장되는 객체와TreeMap에 저장되는 키 객체는 저장과 동시에 오름차순으로 정렬되는데, 어떤 객체든 정렬될 수 있는 것은 아니고 객체가Comparable인터페이스를 구현하고 있어야 가능하다.Integer,Double,String타입은 모두Comparable을 구현하고 있기 때문에 상관 없지만, 사용자 저으이 객체를 저장할 때에는 반드시Comparable을 구현하고 있어야 한다.
| 리턴타입 | 메서드 | 설명 |
|---|---|---|
int | compareTo(T o) | 주어진 객체와 같으면 0을 리턴 주어진 객체보다 적으면 음수를 리턴 주어진 객체보다 크면 양수를 리턴 |
Continue with Comparable Commit
- 비교 기능이 있는
Comparable구현 객체를TreeSet에 저장하거나TreeMap의 키로 저장하는 것이 원칙이지만, 비교 기능이 없는Comparable비구현 객체를 저장하고 싶다면 방법은 없진 않다. TreeSet과TreeMap을 생성할 때 비교자Comparator를 다음과 같이 제공하면 된다.
public class ComparatorImpl {
// new ComparatorImpl() ==> 비교자
TreeSet<E> treeSet = new TreeSet<E>(new ComparatorImpl());
TreeMap<K, V> treeMap = new TreeMap<K, V>(new ComparatorImpl());
}
- 비교자는
Comparator인터페이스를 구현한 객체를 말하는데,Comparator인터페이스에는compare()메서드가 정의도어 있다.
| 리턴 타입 | 메서드 | 설명 |
|---|---|---|
int | compareTo(T o1, T 02) | o1과 o2가 동등하다면 0을 리턴o1이 o2보다 앞에 오게 하려면 음수를 리턴o1이 o2보다 뒤에 오게 하려면 양수를 리턴 |
Continue with Comparator Commit
LIFO 와 FIFO 컬렉션
- 후입선출(
LIFO,Last In Out)은 나중에 넣은 객체가 먼저 빠져나가고, 선입선출(FIFO,First IN First Out)은 먼저 넣은 객체가 먼저 빠져나가는 구조를 말한다. 컬렉션 프레임워크는
LIFO자료구조를 제공하는 스택Stack클래스와 FIFO 자료구조를 제공하는 큐Queue인터페이스를 제공하고 있다.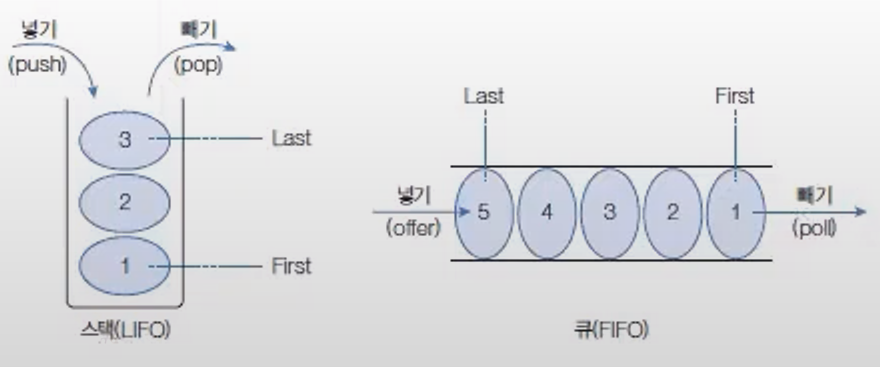
- 스택을 응용한 대표적인 예가
JVM스택 메모리이다. - 스택 메모리에 저장된 변수는 나중에 저장된 것부터 제거된다.
- 큐를 응용한 대표적인 예가 스레드 풀(ExecutorService)의 작업 큐이다.
Stack
Stack클래스는LIFO자료구조를 구현한 클래스이다.
import java.util.Stack;
public class StackExample {
Stack<E> stack = new Stack<E>();
Stack<E> stack = new Stack<>();
}
| 리턴 타입 | 메서드 | 설명 |
|---|---|---|
E | push(E item) | 주어진 객체를 스택에 넣는다. |
E | pop() | 스택의 맨 위 객체를 빼낸다. |
Continue with Stack Commit
Queue
Queue인터페이스는FIFO자료구조에서 사용되는 메서드를 정의하고 있다.
| 리턴 타입 | 메서드 | 설명 |
|---|---|---|
boolean | offer(E e) | 주어진 객체를 큐에 넣는다. |
E | poll() | 큐에서 객체를 빼낸다. |
public class Queue {
Queue<E> queue = new LinkedList<E>();
Queue<E> queue = new LinkedList<>();
}
Continue with Queue Commit
동기화된 컬렉션
- 컬렉션 프레임워크의 대부분의 클래스들은 싱글 스레드 환경에서 사용할 수 있도록 설계되었다.
- 그렇기 때문에 여러 스레드가 동시에 컬렉션에 접근한다면 의도하지 않게 요소가 변경될 수 있는 불안전한 상태가 된다.
Vector와Hashtable은 동기화된(synchronized) 메서드로 구성되어 있기 때문에 멀티 스레드 환경에서 안전하게 요소를 처리할 수 있지만,ArrayList,HashSet,HashMap은 동기화된 메서드로 구성되어 있지 않아 멀티 스레드 환경에서 안전하지 않다.- 이 경우 멀티 스레드 환경에서 사용하고 싶을 때가 있을 것이다. 이런 경우를 대비해서 컬렉션 프레임워크는 비동기화된 메서드를 동기화된 메서드로 래핑하는
Collection의synchronizedXXX()메서드를 제공한다.
| 리턴 타입 | 메서드(매개변수) | 설명 |
|---|---|---|
List<T> | synchronizedList(List<T> list) | List를 통기화된 List로 리턴 |
Map<K, V> | synchronizedMap(Map<K, V> m) | Map를 통기화된 Map로 리턴 |
Set<T> | synchronizedSet(Set<T> s) | Set를 통기화된 Set로 리턴 |
ArrayList를Collections.synchronizedList()메서드를 사용해서 동기화된List로 변환된다.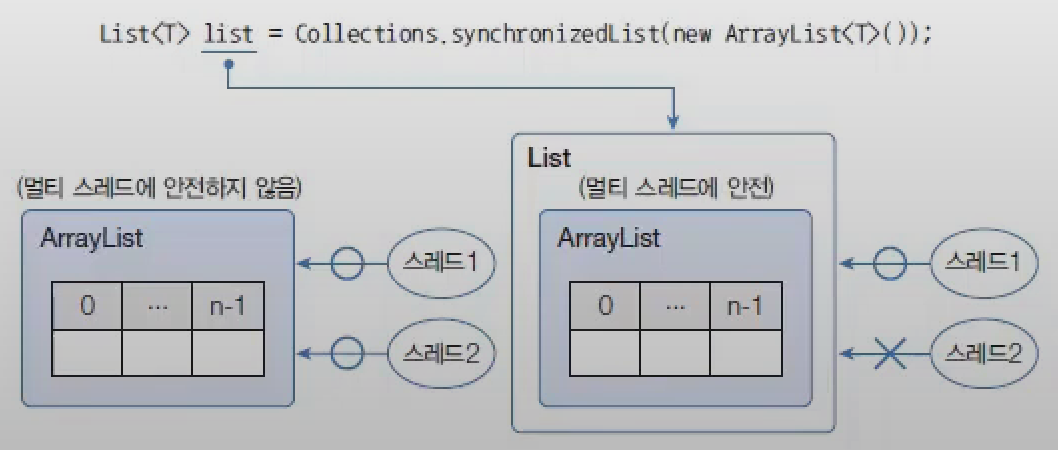
HashSet를Collections.synchronizedSet()메서드를 사용해서 동기화된Set로 변환된다.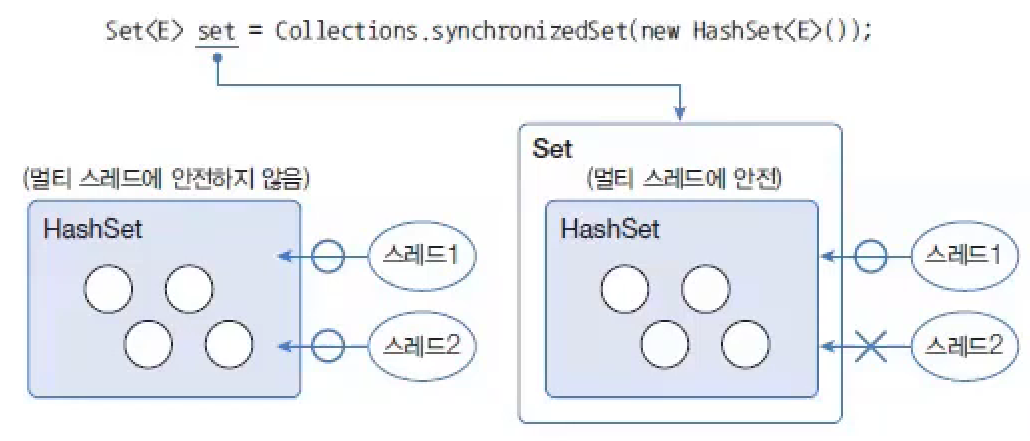
HashSet를Collections.synchronizedMap()메서드를 사용해서 동기화된Map로 변환된다.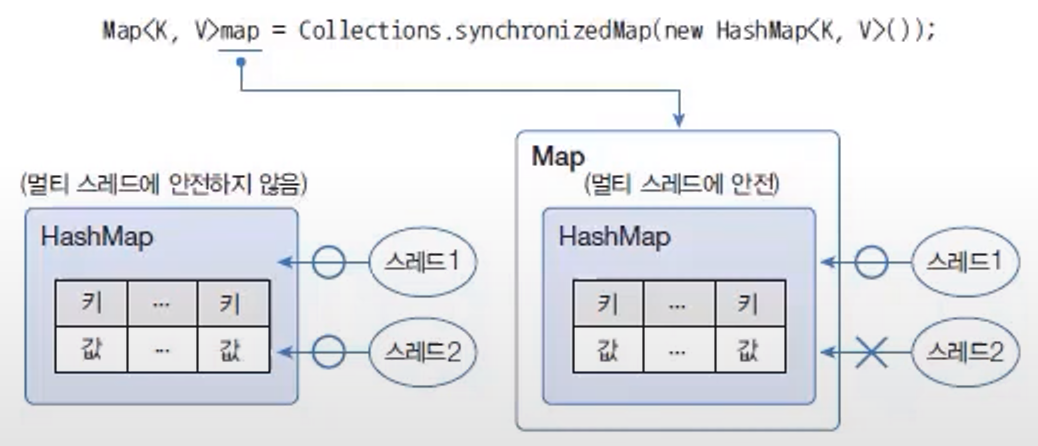
public class SynchronizedMap {
Map<Integer, String> map = Collections.synchronizedMap(new HashMap<>()); // 출력 : 일정한 값
Map<Integer, String> map = new HashMap<>(); // 출력 : 일정하지 않은 값
}
HashMap은 두 스레드가 동시에put()메서드를 호출할 수 있기 때문에 경합이 발생하고 결국 하나만 저장되기 때문이다.- 하지만 동기화된
Map은 한 번에 하나의 스레드만put()메서드를 호출할 수 있기 때문에 경합이 발생하지 않는다.
Continue with SynchronizedMap Commit
수정할 수 없는 컬렉션
- 수정할 수 없는(
unmodifiable) 컬렉션이란 요소를 추가, 삭제할 수 없는 컬렉션을 말한다. - 첫 번째 방법으로는
List,Set,Map인터페이스의 정적 메서드인of()로 생성할 수 있다.public class Of { List<E> immutableList = List.of(E... elements); Set<E> immutableSet = Set.of(E... elements); Map<K, V> immutableMap = Map.of(K k1, V v1, K k2, V v2, ...); } - 두 번째 방법은
List,Set,Map인터페이스의 정적 메서드인copyOf()을 이용해 기존 컬렉션을 복사하여 수정할 수 없는 컬렉현을 만든는 것이다.public class CopyOf { List<E> immutableList = List.copyOf(Collection<E> coll); Set<E> immutableSet = Set.copyOf(Collection<E> coll); Map<K, V> immutableMap = Map.copyOf(Map<K, V> map); } - 세 번째 방법은 배열로부터 수정할 수 없는
List컬렉션을 만들 수 있다.public class AsList { String[] arr = {"A", "B", "C"}; List<String> immutableList = Arrays.asList(arr); }
Continue with Unmodifiable Commit
2023-03-02 스터디

- 오늘도 어김없이 영한 님의 인강을 듣고 출근했다.
- 지금 영한 님의 새로운 인강이 출시되어 월급 받으면 바로 결제할 예정이다.
- 지금 얼리버드 할인 적용이 되어 30% 저렴하게 구매할 수 있다. 오늘도 열공 열일하자…🤩
람다식이란?
- 함수형 프로그래밍
function programming이란 함수를 정의하고 이 함수를 데이터 처리부로 보내 데이터를 처리하는 기법을 말한다.- 함수 vs 메서드
- 함수 : 객체와 상관없이 실행가능한 코드 블럭, 주로
javascript의function() { ... }을 말한다. - 메서드 : 반드시 객체 안에 존재해야 한다. 즉, 객체 기능을 정의한다. 메서드는
class,object로 감싸져있어야 한다.
- 함수 : 객체와 상관없이 실행가능한 코드 블럭, 주로
- 함수 vs 메서드
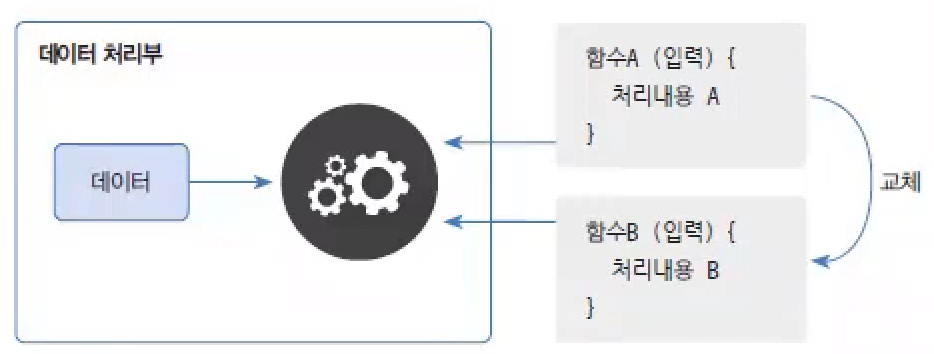
- 데이터 처리부는 제공된 함수의 입력값으로 데이터를 넣고 함수에 정의된 처리 내용을 실행한다.
- 동일한 데이터라도
함수A를 제공해서 처리하는 결과와함수B를 제공해서 처리하는 결과는 다를 수 있다. 이것이 함수형 프로그래밍의 특징으로, 데이터 처리의 다형성데이터 처리의 다형성이라고도 볼 수 있다. - 람다식
Lambda Expressions은 데이터 처리부에 제공되는 함수 역할을 하는 매개변수를 가진 중괄호 블록이다.람다식: (매개변수, ...) -> { 처리내용 } - 자바는 람다식을 익명 구현 객체로 변환한다.
public class AnonymousTest { public void action(Calculable calculable) { int x = 10; int y = 4; Calculable.calculable(x, y); // 데이터를 제공하고 추상 메서드를 호출 } }
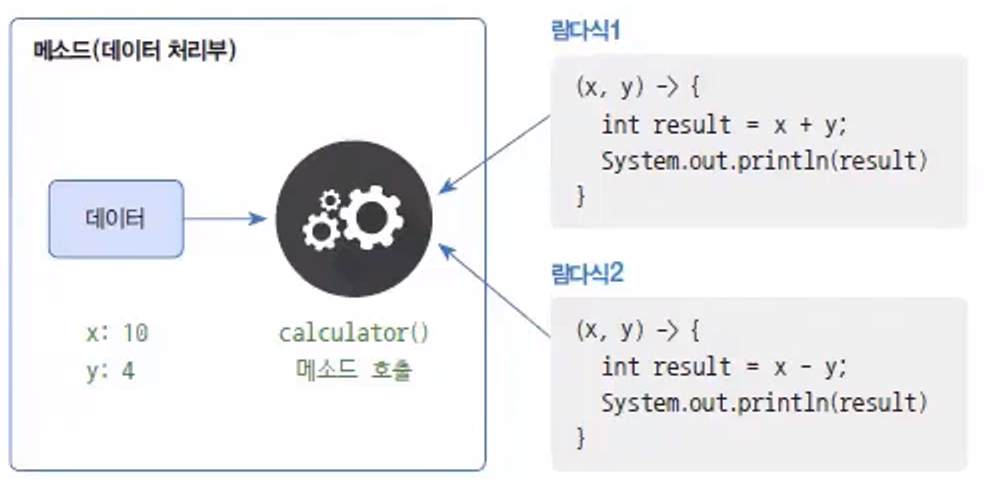
- 람다식은 두 개 이상의 추상 메서드를 가진 인터페이스는 람다식으로 표현할 수 없다.
- 인터페이스가 단 하나의 추상 메서드를 가질 때, 이를 함수형 인터페이스
functional interface라고 한다.
| 인터페이스 | 람다식 |
|---|---|
public interface Runnable {void run();} | () -> { ... } |
@FunctionalInterfacepublic interface Calculable {void calculate(int x, int y);} | (x, y) -> { ... } |
- 인터페이스가 함수형 인터페이스임을 보장하기 위해서는
@FunctionalInterface어노테이션을 붙이면 된다. @FunctionalInterface를 붙이는 것은 선택사항이지만, 컴파일 과정에서 추상 메서드가 하나인지 검사하기 때문에 정확한 함수형 인터페이스를 작성할 수 있게 도와준다.
Continue with Basic Lambda Expressions Commit
스터디 발표
자바스크립트 내장객체
Number 객체
toString(): 숫자형 데이터를 문자형 데이터로 반환toExponential(): 숫자를 지수형으로 반환 (지수 = 과학이나 공학에서 아주 큰 숫자를 표기하는 기법 )toFixed(): 소수점 몇 번째 자리까지 보여줄지 결정하는 함수. 반올림 값 반환toPrecision(): 정수와 소수를 포함해서 몇 번째 자리까지 보여줄지 결정하는 함수. 반올림 값 반환parseInt(): 정수로 반환. 문자열의 시작이 숫자형 이어야지 반환.parseFloat(): 부동소수점으로 반환.Array 객체
toString(): 배열 안의 모든 문자를 쉼표(,)를 이용해 결합해서 하나의 문자열로 반환join(): 배열 안의 모든 문자를 파라미터로 지정한 문자를 이용해서 모두 결합해서 하나의 문자열로 반환pop(): 배열에서 마지막 데이터를 제거하고, 마지막 데이터 반환push():shift(): 배열에서 첫 번째 요소를 제거하고, 첫 번째 요소를 반환unshift(): 배열의 맨 앞에 요소를 추가하고, 배열의 길이를 반환.select박스의 첫 번째 문장 ->선택하세요splice(): 새로운 요소를 특정 위치에 추가. 기존 요소 삭제 가능concat(): 2개 이상의 배열을 하나의 배열로 반환
왕돼지티라노의 기록 - JPA 영속성 관리2
^.^ - HTTP
- 오늘은 회사에서
vue로 마이너그래이션 작업하던 중 검색 조건에서의 컴포넌트화 진행하던 중초기화버튼을 누르면 해당 컴포넌트가 초기화되는 작업을 진행하는 데 애를 먹었다. - 결국 완벽하게 완성되진 않았지만 기능적으론 동작하게 되었다. 개발자 도구를 보니
warning문구가 나오는 것을 확인 하구 내일 출근해서 처리할 예정이다. 그것 때문에 30분 정도 늦게 마치고 퇴근하였다. - 퇴근 후 다음 주 발표 있을 자료를 준비를…🤩
2023-03-03

- 어제 늦게 자서 오늘 좀 늦잠을 잤다…😋
- 오늘도 역시 영한 님의 인강을 듣고 출근하였고 이것이 자바다를 얼른 다 읽고 영한 님의 스프링 강의를 제대로 공부해야겠다는 생각이 들었다.
- 오늘 오전 공부는 워니님의 인강을 들었다.
- 새롭게 알게 된 내용이 내 이력서를 업데이트하면서 나의 부족한 점을 찾아내고 나의 현재 상태를 잘 파악할 수 있다는 점이다.
- 그럼으로써 나의 이력서는 다듬어지고 나의 부족한 점을 찾아 메울 수 있다는 것인데, 이런 생각을 왜 늦게 했을까? 하는 아쉬움이 남았다.
- 그래서 오늘부터 일정 시간을 나의 이력서 작성하는 것에 시간을 사용하려 한다.
2023-03-04
- 오늘은 9시에 일어나 준비를 하고 10시 10분쯤 머리를 하러 갔다. 애즈펌을 했는데 나름 만족한다.😙
- 그리고 여자친구를 만나서 광화문에 가서 이탈리아 식당에서 맛있는 밥을 먹고 내가 제일 좋아하는 광화문 교보문고에 갔다.
- 새 학기라 아이들 손을 잡고 오신 부모님들이 많았다. 그리고 핫트랙스에서 필기도구를 20% 할인하고 있어서 사람들이 더 많았다.
- 한 2시간 정도 있었는데
I라인에 기술서가 있는 곳에서 시간을 다 보냈다. - 너무 보고 싶은 책들이 많아 어떤 책을 사야 할지 고민을 하던 중
Clean Code로 유명한 로버트 C. 마틴 저자의 클린 소프트웨어을 선택했다. - 선택한 이유는 애자일에 대해 생소한 부분도 있었고 테스트 주도 개발, SOLID, 사례를 통한 패턴이어서 너무 끌렸다.
- 그리고 동욱(향로) 님의 스프링 부트와 AWS로 혼자 구현하는 웹 서비스와 구글 엔지니어는 이렇게 일한다를 인터넷으로 주문하였다.
- 인터넷이 좀 더 저렴하기도 하고 책 상태가 좋지 않아 인터넷으로 주문하였다.
- 역시 향로님의 책은
IntelliJ로 시작한다는 점과AWS를 활용과 더불어테스트에 대해 작성해 주셔서 너무 보고 싶던 책이었다. 문화,도구,프로세스,코드 리뷰,대규모 변경등을 간접적으로 느껴보고 싶어서 구매하였다.
2023-03-05
- 10시에 기상… 늦잠을 잤다…🤫
람다식이란?
매개변수가 없는 람다식
| 실행문이 두 개 이상 | 실행문이 하나일 경우 |
|---|---|
() -> {실행문;실행문;} | () -> 실행문 |
Continue with No-Parameters Lambda Expressions Commit
- 다음은 ch09.nested_declaration_and_anonymous_objects 에서 구현한 익명 구현 객체 예제를 람다식으로 대체한 예제로 바꾸어 보았다.
Continue with No-Parameters Anonymous-Objects Lambda Expressions Commit
매개변수가 있는 람다식
- 함수형 인터페이스의 추상 메서등에 매개변수가 있을 경우 람다식은 다음과 같이 작성할 수 있다.
- 매개변수를 선언할 때 타입은 생략할 수 있고, 구체적인 타입 대신에
var를 사용할 수 도 있다. 하지만 타입을 생략하고 작성하는 것이 일반적이다.
| 실행문이 두 개 이상인 경우 | ||
|---|---|---|
(타입 매개변수, ...) -> {실행문;실행문;} | (var 매개변수, ...) -> {실행문;실행문;} | (매개변수, ...) -> {실행문;실행문;} |
| 실행문이 한 개인 경우 | ||
|---|---|---|
(타입 매개변수, ...) -> 실행문 | (var 매개변수, ...) -> 실행문 | (매개변수, ...) -> 실행문 |
| 매개변수가 하나일 경우에는 괄호를 생략할 수 있다 | |
|---|---|
타입 매개변수 -> {실행문;실행문;} | 매개변수 -> 실행문 |
Continue with Parameters Lambda Expressions Commit
리턴값이 있는 람다식
| 리턴값이 있는 람다식 | |
|---|---|
(매개변수, ...) -> {실행문;return 값;} | (매개변수, ...) -> 값 |
Continue with Return Lambda Expressions Commit
메서드 참조
- 메서드 참조는 메서드를 참조해서 매개변수의 정보 및 리턴 타입을 알아내 람다식에서 불필요한 매개변수를 제거하는 것을 목적으로 한다.
(left, right) -> Math.max(left, right);
// 위 코드를 아래 코드로 함축하여 사용할 수 있다.
Math :: max;
정적 메서드와 인스턴스 메서드 참조
- 정적
static메서드를 참조할 경우에는 클래스 이름 뒤에::기호를 붙이고 정적 메서드 이름을 기술한다. - 인스턴스 메서드일 경유에는 먼저 객체를 생성한 다음 참조 변수 뒤에
::기호를 붙이고 인스턴스 메서드 이름을 기술한다.
// 정적 메서드
클래스 :: 메서드
// 인스턴스 메서드
참조변수 :: 메서드
Continue with Method Reference Lambda Expressions Commit
매개변수의 메서드 참조
- 람다식에서 제공되는
a매개변수의 메서드를 호출해서b매개변수를 매개값으로 사용하는 경우가 있다.
(a, b) -> { a.instanceMethod(b); }
a의 클래스 이름 뒤에::기호를 붙이고 메서드 이름을 기술한다.- 정적 메서드 참조와 동일하지만,
a의 인스턴스 메서드가 사용된다는 점에서 다르다.
클래스 :: instanceMethod
Continue with Method Reference of Parameters Lambda Expressions Commit
생성자 참조
- 생성자를 참조한다는 것은 객체를 생성하는 것을 의미한다.
- 람다식이 단순히 객체를 생성하고 리턴하도록 구성된다면 람다식을 생성자 ㅏㅁ조로 대치할 수 있다.
(a, b) -> { return new 클래스(a, b); }
- 이것을 생성자 참조로 표현한다면 아래와 같이 클래스 이름 뒤에
::기호를 붙이고new연산자를 기술하면 된다.
클래스 :: new
- 생성자가 오버로딩되어 여러 개가 있을 경우, 컴파일러는 함수형 인터페이스의 추상 메서드와 동일한 매개변수 ㅏ입과 개수를 가지고 있는 생성자를 찾아 실행한다.
- 만약 해당 생성자가 존재하지 않으면 컴파일 오류가 발생한다.
Continue with Constructor Reference Lambda Expressions Commit
스트림 요소 처리
스트림이란?
Java8부터는 컬렉션 및 배열의 요소를 반복 처리하기 위해 스트림stream을 사용할 수 있다.
public class Stream {
public static void main(String[] args) {
Stream<String> stream = list.stream();
stream.forEach( item -> System.out.println(item) );
}
}
Stream은Iterator와 비슷한 반복자이니지만, 차이점을 가지고 있다.- 내부 반복자이므로 처리 속도가 빠르고 병렬 처리에 효율적이다.
- 람다식으로 다양한 요소 처리를 정의할 수 있다.
- 중간 처리와 최종 처리 를 수행하도록 파이프 라인을 형성할 수 있다.
Continue with Basic Stream Commit
내부 반복자
for문과iterator는 컬렉션의 요소를 컬렉션 바깥쪽으로 반복해서 가져와 처리하는데, 이것을 외부 반복자라고 한다.Stream은 요소 처리 방법을 컬렉션 내부로 주입시켜서 요소를 반복 처리하는데, 이것을 내부 반복자라고 한다.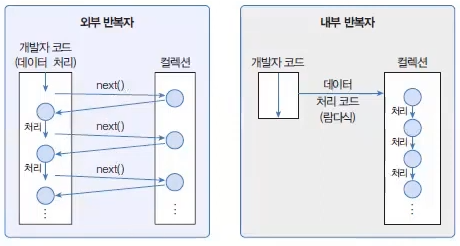
- 외부 반복자일 경우는 컬렉션의 요소를 외부로 가져오는 코드와 처리하는 코드를 모두 개발자 코드가 가지고 있어야 한다.
- 반면, 내부 반복자일 경우는 개발자 코드에서 제공한 데이터 처리 코드(람다식)를 가지고 컬렉션 내부에서 요소를 반복 처리한다.
- 내부 반복자는
멀티 코어 CPU를 최대한 활용하기 위해 요소들을 분배시켜 병렬작업을 할 수 있다. - 하나씩 처리하는 순차적 외부 반복자보다는 효율적으로 요소를 반복시킬 수 있는 장점이 있다.
- 반면, 처리 내용이 적은 경우는 각 스레드들을 만들어야 하기 때문에 오히려 속도가 저하 될 수 있다는 단점이 있다.
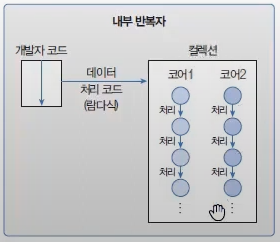
Continue with Parallel Stream Commit
중간 처리와 최종 처리
Stream은 하나 이상 연결되 수 있다. 컬렉션의 오리지널 스트림 뒤에 필터링 중간 스트림이 연결될 수 있고, 그 뒤에 매핑 중간 스트림이 연결될 수 있다. 이와 같이 스트림이 연결되어 있는 것을 스트림 파이프라인pipelines이라고 한다.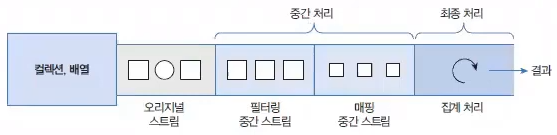
- 오리지널 스트림과 집계 처리 사이의 중간 스트림들은 최종 처리를 위해 요소를 걸러내거나(필터링), 변환시키너나(매핑), 정렬하는 작업을 수행한다.
- 최종 처리는 중간 처리에서 정제된 요소들을 반복하거나, 집계(카운팅, 총합, 평균) 작업을 수행한다.
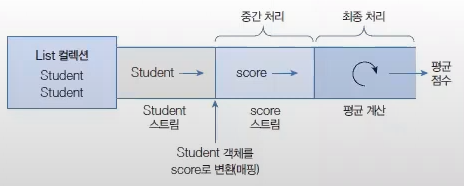
public class StreamSuduent {
// Student 스트림
Stream<String> studentStream = list.stream();
// score 스트림
// Student 객체를 getScore() 메서드의 리턴값으로 매핑
IntStream scoreStream = studentStream.mapToInt( student -> student.getScore() );
// 평균 계산
double avg = scoreStream.average().getAsDouble();
}
mapToInt()메서드는 객체를int값으로 매핑해서IntStream으로 변환시킨다.- 어떤 객체를 어떤
int값으로 매핑할 것인지는 람다식으로 제공해야 한다. student -> student.getScore()는Student객체를getScore()의 리턴값으로 매핑한다.InputStream은 최종 처리를 위해 다양한 메서드를 제공하는데,average()메서드는 요소들의 평균 값을 계산한다.
public class StramMapToInt {
double avg = list.stream()
// mapToInt() 메서드는 int 값으로 매핑해서 IntStream으로 변환
.mapToInt(student -> student.getScore()) // student -> student.getScore()는 Student 객체를 getScore()의 리턴값으로 매핑
.average() // 요소들의 평균 값을 계산
.getAsDouble();
}
Continue with Stream Pipelines Commit
- 오늘 하루는 일어나서 먹고 공부하고 먹고 공부하고 낮잠 자고 먹고 공부하고 한거 같다…😅
- 곰 같은 하루를 보낸듯하다.
Reference
Back to [Routine] 6 주차 시작!
Continue with [Routine] 8 주차 시작!

