저번 주 주말 내내 이것이 자바다 공부를 했는데 문득 드는 생각이 너무 정리하면서 공부하려고 해서 늦어지는거 같다는 생각이 들었다.
정말 중요하거나 블로그에 적어야할 거 같은 내용만 적고 무슨 챕터를 진행했는지만 블로그에 적으려 한다.
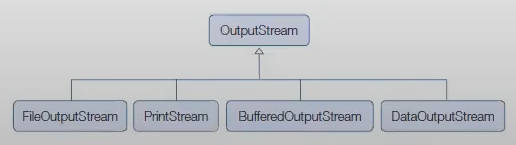
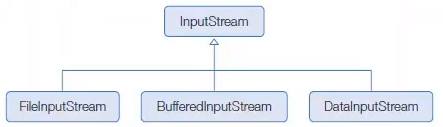
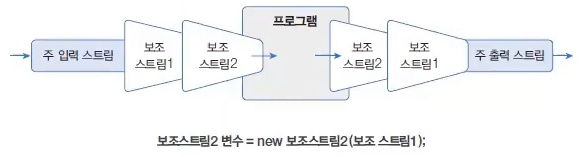
데이터 입출력
성능 향상 스트림
importjava.io.BufferedInputStream;importjava.io.BufferedOutputStream;importjava.io.BufferedReader;importjava.io.BufferedWriter;publicclassExample{BufferedInputStreambis=newBufferedInputStream(/* 바이트 입력 스트림 */);BufferedOutputStreambos=newBufferedOutputStream(/* 바이트 출력 스트림 */);BufferedReaderbr=newBufferedReader(/* 문자 입력 스트림 */);BufferedWriterbw=newBufferedWriter(/* 문자 출력 스트림 */);}
importjava.io.BufferedReader;importjava.io.FileReader;publicclassExample{BufferedReaderbr=newBufferedReader(newFileReader("file path"));while(true){Stringstr=br.readLine();// 파일에서 한 행씩 읽음if(str==null)break;// 더 이상 읽을 행이 없을 경우(파일 끝) while 문 종료}}
importjava.io.DataInputStream;importjava.io.DataOutputStream;publicclassExample{DataInputStreamdis=newDataInputStream(/* 바이트 입력 스트림 */);DataOutputStreamdos=newDataOutputStream(/* 바이트 출력 스트림 */);}
importjava.io.PrintStream;importjava.io.PrintWriter;publicclassExample{PrintStreamps=newPrintStream(/* 바이트 출력 스트림 */);PrintWriterpw=newPrintWriter(/* 문자 출력 스트림 */);}
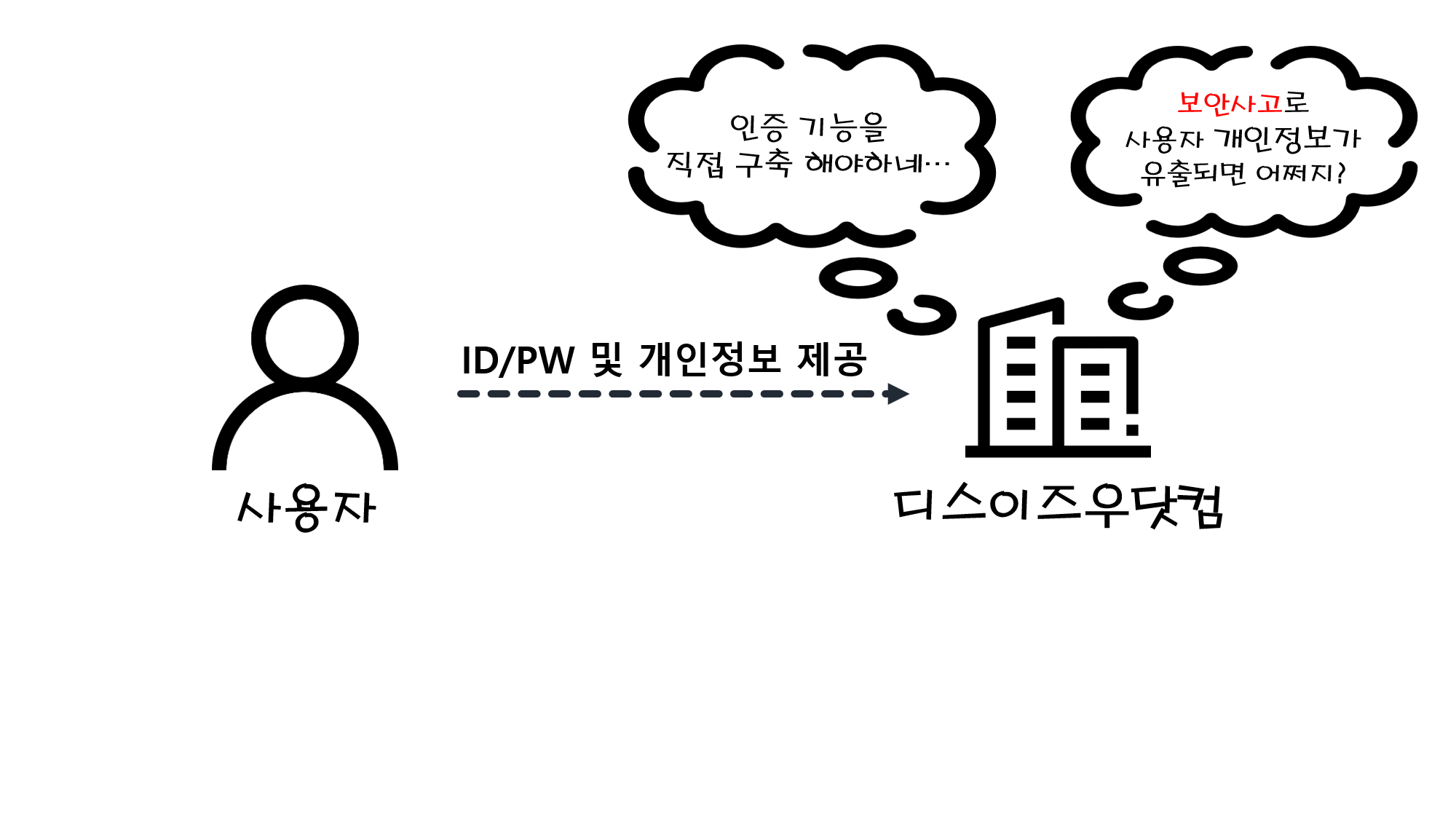
파일 또는 폴더의 정보를 얻기 위해 File 객체를 단독으로 사용할 수 있지만, 파일입출력 스트림을 생성할 때 경로 정보를 제공할 목적으로 사용되기도 한다.
importjava.io.File;importjava.io.FileInputStream;publicclassExample{// 첫 번째 방법FileInputStreamfis=newFileInputStream("filepath");// 두 번째 방법Filefile=newFile("filepath");FileInputStreamfileFis=newFileInputStream(file);}
Files 클래스
Files 클래스는 정적 메서드로 구성되어 있고, File 보다 좀 더 많은 기능을 제공한다.
publicclassExample{Pathpath=Path.get(Stringfirst,String...more);// 예)Pathpath=Path.get("C:/Temp/dir/file.txt");Pathpath=Path.get("C:/Temp/dir","file.txt");Pathpath=Path.get("C","Temp","dir","file.txt");// 절대 경로와 상대 경로Pathpath=Path.get("dir/file.txt");Pathpath=Path.get("./dir/file.txt");Pathpath=Path.get("../dir/file.txt");}
LANLocal Area Network은 가정, 회사, 건물, 특정 여역에 존재하는 컴퓨터를 연결하는 것이다.
WANWide Area Network은 LAN을 연결한 것으로, 쉽게 말해 인터넷Internet이다
서버와 클라이언트
서비스를 제공하는 프로그램을 일반적으로 서버Server라고 한다.
서비스를 요청하는 프로그램을 클라이언트Client라고 한다.
인터넷에 두 프로그램이 통신하기 위해서는 먼저 클라이언트가 서비스를 요청하고, 서버는 처리결과를 응답으로 제공해준다.
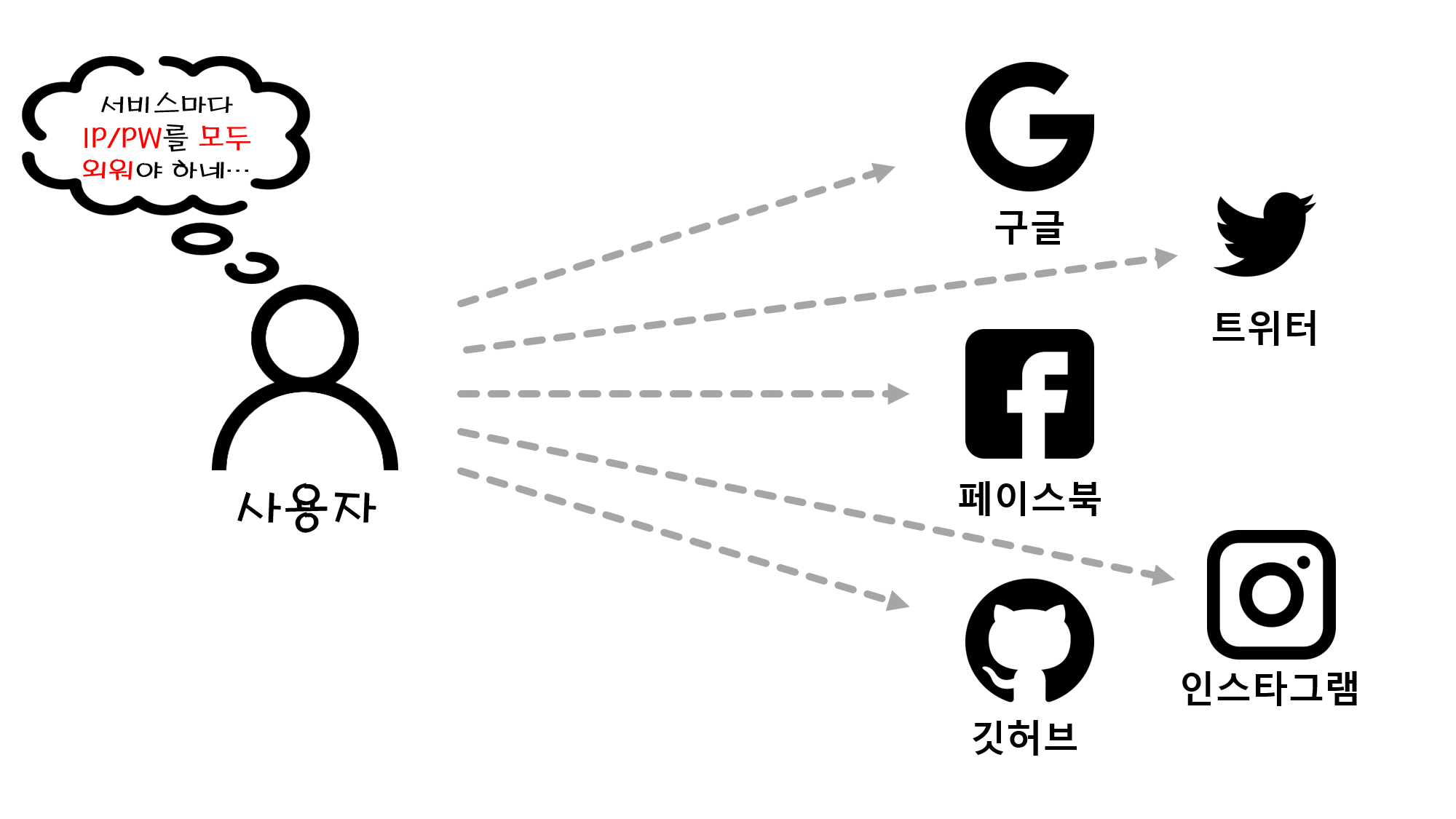
IP 주소
IPInternet Protocol는 컴퓨터의 고유한 주소이다.
Mac에서는 ifconfig, Window에서는 ipconfig를 터미널/CMD창에서 검색하게 되면 ip 정보를 볼 수 있다.
DNSDomain Name System는 도메인 이름으로, IP를 등록하는 저장소이고, 컴퓨터의 IP 주소를 검색한다.
대중에게 서비스를 제공하는 대부분의 컴퓨터는 다음과 같이 도메인 이름으로 IP를 미리 DNS에 미리 등록해 놓는다.
도메인 이름
IP주소
www.naver.com
222.122.195.5
웹 브라우전즌 웹 서버와 통신하는 클라이언트로, 상요자가 입력한 도메인 이름으로 DNS에서 IP 주소를 검색해 찾는 다음 웹 서버와 연결해서 웹 페이지를 받는다.
2023-03-15
오늘도 어김없이 영한 님과…🤩
네트워크 입출력
네트워크 기초
Port 번호
Port는 운영체제가 관리하는 서버 프로그램의 연결 번호이다.
서버는 시작할 때 특정 Port 번호에 바인딩 한다.
클라이언트도 서버에서 보낸 정보를 받기 위해서는 Port 번호가 필요한데, 서버와 같이 고정적인 Port 번호에 바인딩하는 것이 아니라 운영체제가 자동으로 부여하는 번호를 사용한다.
이 번호는 클라이언트가 서버로 요청할 때 함게 전송되어 서버가 클라이언트로 데이터를 보낼 때 사용된다.
IP 주소 얻기
Java는 IP 주소를 java.net 패키지의 InetAddress로 표현한다.
InetAddress를 이용하면 로컬 컴퓨터의 IP 주소를 얻을 수 있고, 도메인 이름으로 DNS에서 검색한 후 IP 주소를 가져올 수도 있다.
importjava.net.InetAddress;publicclassExample{// local 컴퓨터의 InetAddress를 얻고 싶을 때InetAddressis=InetAddress.getLocalHost();// 컴퓨터의 도메인 이름을 알고 있다면 두 개의 메서드를 사용하여 InetAddress 객체를 얻을 수 있다.InetAddressis=InetAddress.getByName(StringdomainName);// 단 하나의 IP 주소를 getInetAddress[]iaArr=InetAddress.getAllByName(StringdomainName);// 등록된 모든 IP 주소를 배열로 get// 위 메서드들로부터 얻은 InetAddress 객체에서 IP 주소를 얻고 싶을 때Stringip=InetAddress.getHostAddress();}
IP 주소로 프로그램들이 통신할 때는 약속된 데이터 전송 규약이 있다. 이것을 전송용 프로토콜Protocol이라고 부른다.
인터넷 에서 전송용 프로토콜은 TCPTransmission Control Protocol와 UDPUser Datagram Protocol가 있다.
TCP는 연결형 프로토콜로, 상대방이 연결된 상태에서 데이터를 주고 바는다.
TCP는 보낸 데이터가 순서대로 전달되며 손실이 발생하지 않는다.
TCP는 웹 브라우저가 웹 서버에 연결할 때 사용되며 이메일 전송, 파일 전송, DB 연동에도 사용된다.
Java는 TCP 네트워킹을 위해 java.net 패키지에서 ServerSocket과 Socket 클래스를 제공하고 있다.
ServerSocket은 클라이언트의 연결을 수학하는 서버 쪽 클래스이고, Socket은 클라이언트에서 연결 요청할 때와 클라이언트와 서버 양쪽에서 데이터를 주고 받을 대 사용되는 클래스이다.
TCP 서버
importjava.net.InetSocketAddress;importjava.net.ServerSocket;importjava.net.Socket;publicclassExample{// 50001번의 port에 바인딩ServerSocketserverSocket=newServerSocket(50001);// 기본 생성자로 객체를 생서하고 port 바인딩을 위해 bind() 메서드를 호출ServerSocketserverSocket=newServerSocket();serverSocket.bind(newInetSocketAddress(50001));// 서버 컴퓨터에 여러 개의 IP가 할당되어 있을 경우, 특정 IP에서만 서비스를 하고 싶다면ServerSocketserverSocket=newServerSocket();serverSocket.bind(newInetSocketAddress("xxx.xxx.xxx.xxx",50001));// ServerSocket이 생성되었다면 연결 요청을 수락하기 위해 accept() 메서드를 실행Socketsocket=serverSocket.accept();// return된 Socket을 통해 연결된 클라이언트의 IP 주소와 Port 번호를 얻고 싶다면InetSocketAddressisa=(InetSocketAddress)socket.getRemoteSocketAddress();StringclientIp=isa.getHostName();StringportNo=isa.getPort();// 서버를 종료하려면 close()serverSocket.close();}
클라이언트가 서버에 연결 요청을 하려면 Socket 객체를 생성할 때 생성자 매개값으로 서버 IP 주소와 Port 번호를 제공하면 된다.
로컬 컴퓨터에서 실행하는 서버로 연결 요청을 할 경우에는 IP 주소 대신 localhost를 사용할 수 있다.
importjava.io.IOException;importjava.net.InetSocketAddress;importjava.net.Socket;publicclassExample{Socketsocket=newSocket("IP",50001);// IP 주소 대신 도메인 이름을 사용하고 싶다면, DNS에서 IP 주소를 검색할 수 있도록 생성자 매개값으로 InetSocketAddress를 제공Socketsocket=newSocket(newInetSocketAddress("domainName",50001));// Socket 생성과 동시에 연결 요청을 하지 않고 기본 생성자로 Socket을 생성한 후 connect() 메서드로 연결 요청할 수도 있다.Socketsocket=newSocket();socket.connect(newInetSocketAddress("domainName",50001));// 연결 요청 시 두 가지 예뵈가 발생할 수 있다.// UnknownHostException은 IP 주소가 잘못 표기 되었을 때 발생// IOException 제공된 IP와 port 번호로 연결할 수 없을 때 발생// 따라서 두 가지 예외 모두 처리해야 한다try{Socketsocket=newSocket("IP",50001);}catch(UnknownHostExceptione){// IP 표기 방법이 잘못되었을 경우e.printStackTrace();}catch(IOExceptione){// IP와 Port로 서버에 연결할 수 없는 경우e.printStackTrace();}// 서버와 연결된 후에 클라이언트에서 연결을 끊고 싶다면socket.close();}
클라이언트가 연결 요청(connect())을 하고 서버가 연결을 수락(accept())했다면 클라이언트와 서버의 양쪽 Socket 객체로부터 가각 입력 스트림InputStream과 출력 스트림스트림OutputStream을 얻을 수 있다.
importjava.io.DataInputStream;importjava.io.DataOutputStream;importjava.io.InputStream;importjava.io.OutputStream;importjava.net.Socket;publicclassExample{Socketsocket=newSocket();InputStreamis=socket.getInputStream();OutputStreamos=socket.getOutputStream();// UTF-8로 인코딩 후 바이트 배열을 얻어내고, write() 메서드로 전송Stringdata="보낼 데이터";byte[]bytes=data.getBytes("UTF-8");os.write(bytes);os.flush();// 문자열을 좀 더 간편하게 보내고 싶다면 보조 스트림인 DataOutputStream을 사용DataInputStreamdos=newDataOutputStream(socket.getOutputStream());dos.writeUTF(data);dos.flush();// 받는 데이터가 문자열이라면byte[]bytes=newbyte[1024];intnum=is.read(bytes);Stringdata=newString(bytes,0,num,"UTF-8");// 해당 방법은 상대방이 DataOutputStream으로 문자열을 보낼 때만 가능DataInputStreamdis=newDataInputStream(socket.getInputStream());Stringdata=dis.readUTF();}
UDPUser Datagram Protocol는 발신자가 일방적으로 수신자에세 데이터를 보내는 방식.
TCP 처럼 연결 요청 및 수락 과정이 없기 때문에 TCP보다 데이터 전송 속도가 상대적으로 빠르다.
Java는 UDP 네트어킹을 위해 java.net 패키지에서 DatagramSocket과 DatagramPacket 클래스를 제공하고 있다.
DatagramSocket은 발신점과 수신점에 해당하고 DatagramPacket은 주고 받는 데이터에 해당한다.
UDP 서버
importjava.net.DatagramPacket;importjava.net.DatagramSocket;importjava.net.SocketAddress;publicclassExample{// DatagramSocket 객체 생성과 port 번호 생성자 매개값DatagramSocketdatagramSocket=newDatagramSocket(50001);// UDP 서버는 클라이언트가 보낸 DatagramPacket을 항상 받을 준비를 해야 한다. 이 역할을 하는 메서드가 receive()이다DatagramPacketreceivePacket=newDatagramPacket(newbyte[1024],1024);datagramSocket.receive(receivePacket);// 수신된 데이터와 바이트 수를 얻는 방법 및 문자열byte[]bytes=receivePacket.getData();intnum=receivePacket.getLength();Stringdata=newString(bytes,0,num,"UTF-8");// getSocketAddress() 메서드를 호출하면 정보가 담긴 SocketAddress 객체를 얻을 수 있다.SocketAddresssocketAddress=receivePacket.getSocketAddress();// 클라이언트로 보맬 Datagrampacket을 생성할 때 네 번째 매개값으로 사용Stringdata="처리 내용";byte[]bytes=data.getBytes("UTF-8");DatagramPacketsendPacket=newDatagramPacket(bytes,0,bytes.length,socketAddress);// 클라이언트에 보낼 때datagramSocket.send(sendPacket);// UDP 종료datagramSocket.close();}
UDP 클라이언트
importjava.net.DatagramPacket;importjava.net.DatagramSocket;importjava.net.InetSocketAddress;publicclassExample{// 기본생성자DatagramSocketdatagramSocket=newDatagramSocket();// 요청을 보내기 위한 DatagramPacket을 생성Stringdata="요청 데이터";byte[]bytes=data.getBytes("UTF-8");DatagramPacketsendPacket=newDatagramPacket(bytes,bytes.length,newInetSocketAddress("localhost",50001));// UDP 서버로 전송datagramSocket.send(sendPacket);// close();datagramSocket.close();}
Connection : Statement, PreparedStatement, CallableStatement 구현 객체를 생성하며, 트랜잭션Transaction 처리 및 DB 연결을 끊을 때 사용한다.
Statement : SQL의 DDLData Definition Language과 DMLData Manipulation Language을 실행할 때 사용한다. 주로 변경되지 않은 정적 SQL 문을 실행할 때 사용한다.
PreparedStatement : Statement와 동일하게 SQL의 DDL, DML 문을 실행할 때 사용한다. 차이점은 매개변수화된 SQL 문을 사용할 수 있기 때문에 편리성과 보안성이 좋다. 그래서 Statement보다는 PreparedStatement를 주로 사용한다.
CallableStatement : DB에 저장되어 있는 프로시저procedure와 함수function를 호출할 때 사용한다.
ResultSet : DB에서 가져온 데이터를 일을 때 사용한다.
프로시저와 함수 호출
프로시저와 함수는 DB에 저장되는 PL/SQL 프로그램이다.
클라이언트 프로그램에서 매개값과 함께 프로시저 또는 함수를 호출하면 DB 내부에서 일련의 SQL 문을 실행하고, 실행 결과를 클라이언트 프로그램으로 돌려주는 역할을 한다.
importjava.sql.CallableStatement;importjava.sql.Connection;publicclassExample{publicstaticvoidmain(String[]args){Connectionconn=null;// 프로시저를 호출할 경우Stringsql="{ call 프로시저명(?, ?, ?)}";CallableStatementcstmt=conn.prepareCall(sql);cstmt.setString(1,"값");// 프로시저 첫 번째 매개값cstmt.setString(2,"값");// 프로시저 두 번째 매개값cstmt.registerOutParameter(3,리턴타입);// 세 번째 ?는 OUT값(리턴값)임을 지정// 함수를 호출할 경우Stringsql="{ ? = call 함수명(?, ?)}";CallableStatementcstmt=conn.prepareCall(sql);cstmt.registerOutParameter(1,리턴타입);// 첫 번째 ?는 리턴값을 지정cstmt.setString(2,"값");// 함수의 두 번째 매개값cstmt.setString(3,"값");// 함수의 세 번째 매개값// 프로시저 또는 함수를 호출하기 위해cstmt.execute();intresult=cstmt.getInt(3);// 프로시저intresult=cstmt.getInt(1);// 함수// 종료cstmt.close();}}
트랜잭션 처리
트랜잭션transaction은 기능 처리의 최소 단위를 말한다.
하나의 기능은 여러 가지 소작업들로 구성된다.
최소 단위라는 것이 이 소작업들을 분리할 수 없으며, 전체를 하나로 본다는 개념이다.
트랜잭션은 소작업들이 모두 성공하거나 실패해야 한다.
// 출금 작업
UPDATE accounts SET balance=balance-이체금액 WHERE ano=출금계좌번호
// 입금 작업
UPDATE accounts SET balance=balance-이체금액 WHERE ano=입금계좌번호
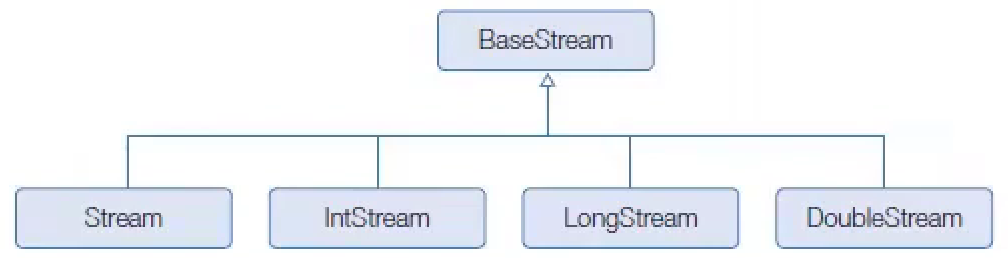
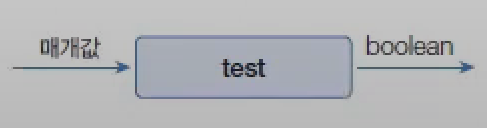
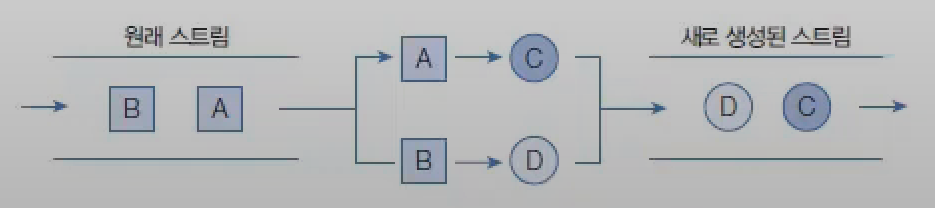
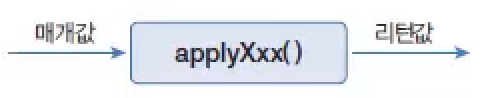
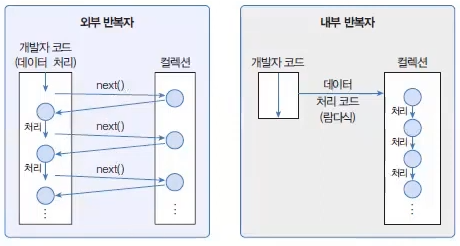
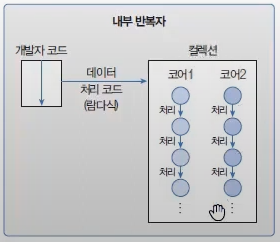
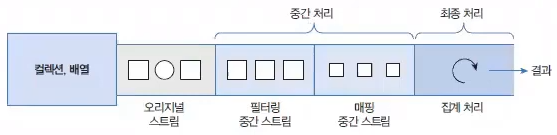
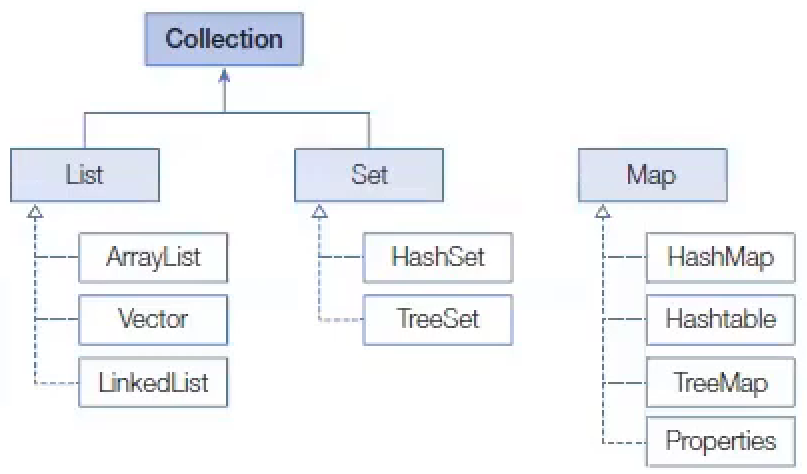
java.util.Collection 인터페이스는 스트림과 parallelStream() 메서드를 가지고 있기 때문에 자식 인터페이스인 List와 Set 인터페이스를 구현한 모든 컬렉션에서 객체 스트림을 얻을 수 있다. Continue with Get Stream from Collection Commit
리턴값인 Collector를 보면 A(누적기accumulator)가 ?로 되어 있는데, 이것은 Collector가 List, Set, Map 컬렉션에 요소를 저장하는 방법을 알고 있어 별도의 누적기가 필요 없기 때문이다.
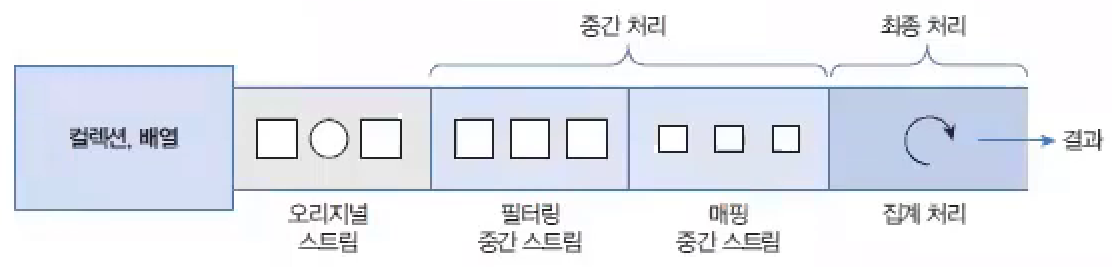
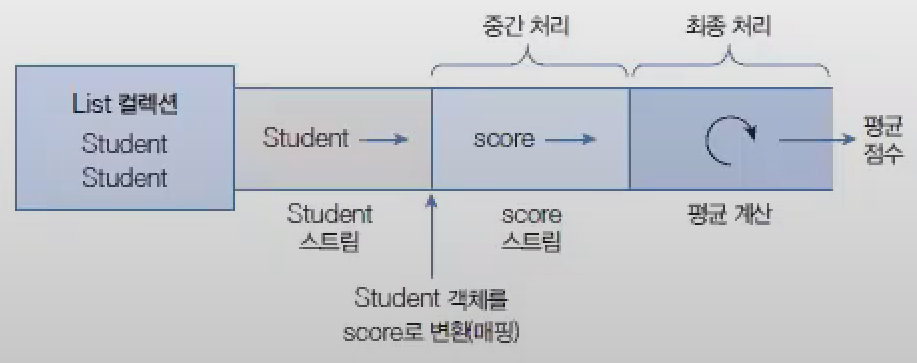
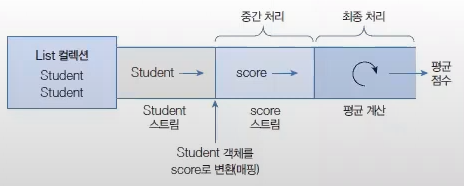
아래 코드는 Student 스트림에서 남학생만 필터링해서 별도의 List로 생성하는 코드
//file: "Student 스트림에서 남학생만 필터링해서 별도의 List로 생성하는 코드.java"importjava.util.Collections;publicclassExample{// Student 스트림에서 남학생만 필터링해서 별도의 List로 생성하는 코드List<Student>maleList=totalList.stream().filter(s->s.getSex().equals("남"))// 남학생만 필터링.collect(Collections.toList());}
//file: "Student 스트림에서 이름을 키로, 점수를 값으로 갖는 Map 컬렉션을 생성하는 코드.java"importjava.util.Map;importjava.util.stream.Collectors;publicclassExample{// Student 스트림에서 이름을 키로, 점수를 값으로 갖는 Map 컬렉션을 생성하는 코드Map<String,Integer>map=totalList.stream().collect(Collectors.toMap(s->s.getName(),// Student 객체에서 키가 될 부분 리턴s->s.getScore()// Student 객체에서 값이 될 부분 리턴));}
Java 16 부터 좀 더 편리하게 요소 스트림에서 List 컬렉션을 얻을 수 있다.
스트림에서 바로 toList() 메서드를 다음과 같이 사용하면 된다.
//file: "Java 16부터 스트림에서 List 컬렉션을 얻는 방법.java"publicclassExample{// Java 16부터 스트림에서 List 컬렉션을 얻는 방법List<Student>maleList=totalList.stream().filter(s->s.getSex().equals("남")).toList();// <-------------- Java 16부터 스트림에서 List 컬렉션을 쉽게 얻는 방법}
//file: "학생들을 성별로 그풉핑하고 각각의 평균 점수를 구해서 Map으로 얻는 코드.java"importjava.util.Map;importjava.util.stream.Collectors;publicclassExample{Map<String,Double>map=totalList.stream().collect(Collectors.groupingBy(s->s.getSex(),Collectors.averagingDouble(s->s.getScore)));}
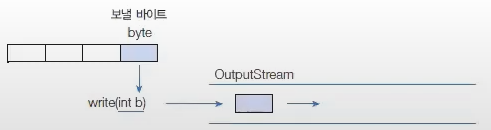
InputStream 클래스에는 바이트 입력 스트림이 기본적으로 가져야 할 메서드가 정의되어 있다.
리턴 타입
메서드
설명
int
read()
1byte를 읽은 후 읽은 바이트를 리턴
int
read(byte[] b)
읽은 바이트를 매개값으로 주어진 배열에 저장 후 읽은 바이트 수를 리턴
void
close()
입력 스트림을 닫고 상요 메모리 해제
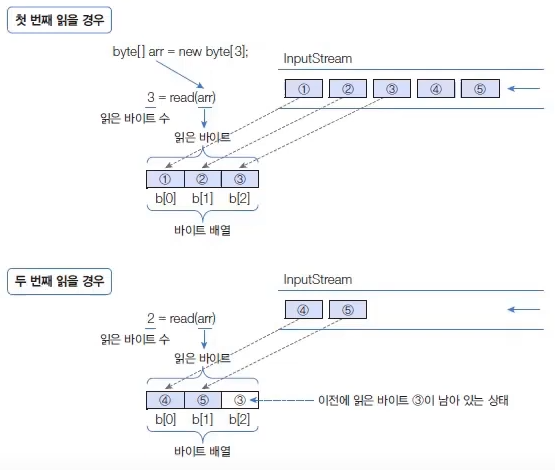
1바이트 읽기
read() 메서드는 입력 스트림으로부터 1byte를 읽고 int(4byte) 타입으로 리턴한다.
따라서 리턴된 4byte중 1byte에만 데이터가 들어 있다.
예를 들어 입력 스트림에서 5개의 바이트가 들어온 다면 다음과 같이 read() 메서드로 1byte씩 5번 읽을 수 있다.
더이상 입력 스트림으로부터 바이트를 읽을 수 없다면 read() 메서드는 -1을 리턴하는데, 이것을 이용하면 읽을 수 있는 마지막 바이트까지 반복해서 한 바이트씩 읽을 수 있다.
importjava.io.InputStream;publicclassExample{InputStreamis=...;while(true){intdata=is.read();// 1 바이트를 읽고 리턴if(data==-1)break;// -1을 리턴했을 경우 while 문 종료}}
FileInputStream 생성자는 주어진 파일이 존재하지 않을 경우 FileNotFoundException을 발생시킨다.
그리고 read(), close() 메서드에서 IOException이 발생할 수 있으므로 두 가지 예외를 모두 처리 해야한다.
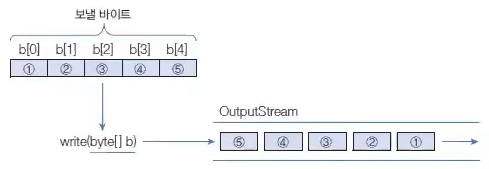
바이트 배열로 읽기
read(byte[] b) 메서드는 입력 스트림으로부터 주어진 배열의 길이만큼 바이트를 읽고 배열에 저장한 다음 읽은 바이트 수를 리턴한다.
예를 들어 입력 스트림에 5개의 바이트가 들어오면 다음과 같이 길이 3인 배열로 두 번 읽을 수 있다.
read(byte[] b) 역시 입력 스트림으로부터 바이트를 더 이상 읽을 수 없다면 -1을 리턴하는데, 이것을 이용하면 읽을 수 있는 마지막 바이트까지 반복해서 읽을 수 있다.
importjava.io.InputStream;publicclassExample{InputStreamis=...;byte[]data=newbyte[100];while(true){intnum=is.read(data);// 최대 100byte를 읽고, 읽은 바이트는 배열 data 저장, 읽은 수는 리턴if(num==-1)break;// -1을 리턴하면 while 문 종료}}
많은 양의 바이트를 읽을 때는 read(byte[] b) 메서드를 사용하는 것이 좋다.
입력 스트림으로부터 100개의 바이트가 들어온다면 read() 메서드는 100번을 반복해서 읽어야 하지만, read(byte[] b) 메서드는 한 번 읽을 때 배열 길이만큼 읽기 때문에 읽는 횟수가 현저히 줄어든다.
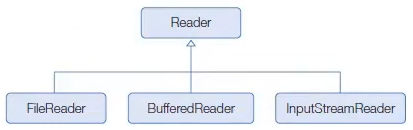
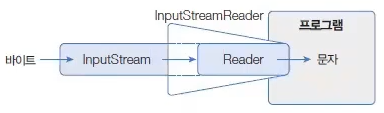
FileInputStream에 InputStreamReader을 연결하지 않고 FileReader를 직접 생성할 수 있다. FileReader는 InputStreamReader의 자식 클래스이다. 이것은 FileReader가 내부적으로 FileInputStream에 InputStreamReader 보조 스트림을 연결한 것이라고 볼 수 있다.
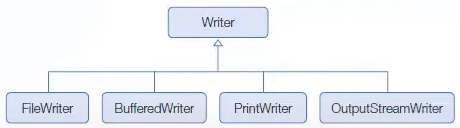
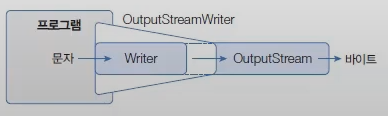
OutputStream을 Writer로 변환
OutputStream을 Writer로 변환하려면 OutputStreamWriter 보조 스트림을 연결하면 된다.
FileOutputStream에 OutputStreamWriter를 연결하지 않고 FileWriter를 직접 생성할 수 있다. FileWriter는 OutputStreamWriter의 자식 클래스이다. 이것은 FileWriter가 내부적으로 FileOutputStream에 OutputStreamWriter 보조 스트림을 연결한 것이라고 볼 수 있다.
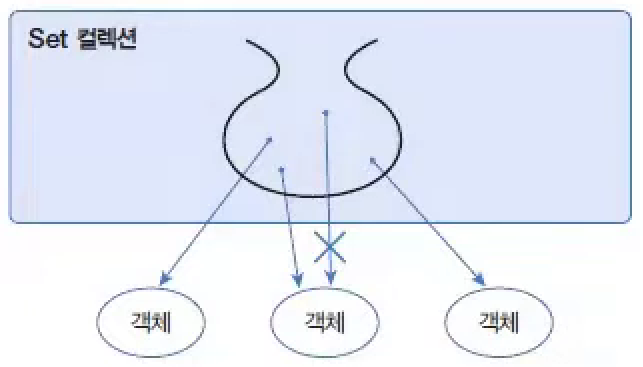
Set 컬렉션은 수학의 집합에 비유될 수 있다. 집합은 순서와 상관없고 중복이 허용되지 않기 때문이다.
기능
메서드
설명
객체 추가
boolean add(E e)
주어진 객체를 성공적으로 저장하면 true를 리턴하고 중복 객체면 false를 리턴
객체 검색
boolean contains(Object o)
주어진 객체가 저장되어 있는지 여부
isEmpty()
컬렉션이 비어있는지 조사
Iterator<E> iterator()
저장된 객체를 한 번씩 가져오는 반복자 리턴
int size()
저장된 모든 객체를 삭제
객체 삭제
void clear()
저장된 모든 객체를 삭제
boolean remove(Object o)
주어진 객체를 삭제
HashSet
Set 컬렉션 중에서 가장 많이 사용되는 것이 HashSet이다.
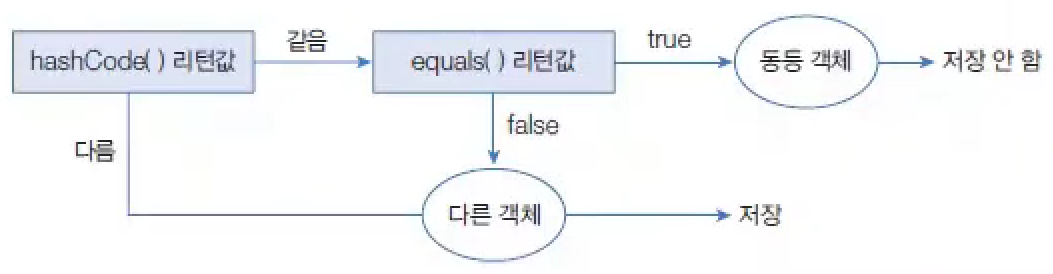
HashSet은 동일한 객체는 중복 저장하지 않는다. 여기서 동일한 객체란 동등 객체를 말한다.
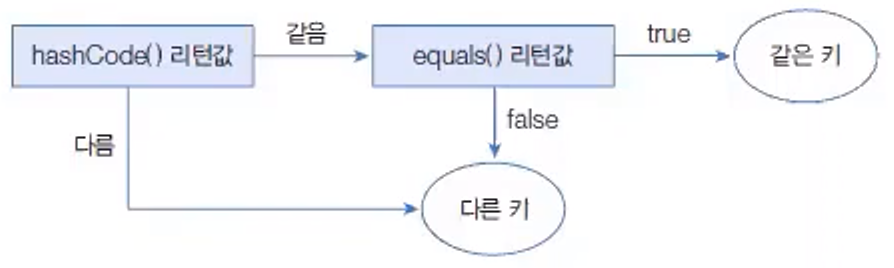
HashSet은 다른 객체라도 hashCode() 메서드의 리턴값이 같고, equals() 메서드가 true를 리턴하면 동일한 객체라고 판단하고 중복 저장하지 않는다.
publicclassSet{Set<E>set=newHashSet<E>();// E에 지정된 타입의 객체만 저장Set<E>set=newHashSet<>();// E에 지정된 타입의 객체만 저장Setset=newHashSet();// 모든 타입의 객체를 저장}
Set 컬렉션은 인덱스로 객체를 검색해서 가져오는 메서드가 없다. 대신 객체를 한 개씩 반복해서 가져와야 하는데, 여기에는 두 가지 방법이 있다.
//file: "for 문을 이용한 방법.java"publicclassSetUsingFor{publicstaticvoidmain(String[]args){Set<E>set=newHashSet<E>();for(Ee:set){System.out.println("for Set : "+e);}}}
Set 컬렉션의 iterator() 메서드로 반복자(iterator)를 얻어 객체를 하나씩 가져오는 것. 타입 파라미터 E는 Set 컬렉션에 저장되어 있는 객체의 타입이다.
//file: "set.iterator()를 사용하는 방법.java"publicclassSetIterator{Set<E>set=newHashSet<E>();Iterator<E>iterator=set.iterator();}
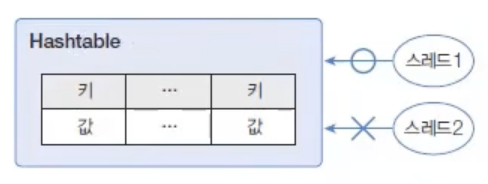
Hashtable은 HashMap과 동일한 내부 구조를 가지고 있다. 차이점은 Hashtable은 동기화된(synchronized) 메서드로 구성되어 있기 때문에 멀티 스레드가 동시에 Hashtable의 메서드들을 실행할 수 없다는 것이다.
따라서 멀티 스레드 환경에서도 안전하게 객체를 추가, 삭제할 수 있다.
publicclassHashtable{Map<String,Integer>map=newHashMap<String,Integer>();Map<String,Integer>map=newHashMap<>();Mapmap=newHashMap();// <- 해당 경우는 거의 없다.}
오늘 HashSet 다시 복습을 하는데 for 문과 iterator에서의 차이점을 새로 알게 되었다.
간략하게 말하자면 for 문은 몇 번 반목할지 이미 알고 있는 상태. 즉, 반복문 실행 중 반복할 횟수의 대상을 제거하면 Exception이 발생하게 된다. 이때 for 문이 아닌 iterator을 사용해야 한다.
// file: "IteratorRemoveErrorExample.java"publicclassIteratorRemoveError{publicstaticvoidmain(String[]args){Set<String>whileSet=newHashSet<String>();whileSet.add("Java");whileSet.add("Spring");whileSet.add("JDBC");whileSet.add("JPA");// 에러 예제 for 문for(Stringelement:whileSet){System.out.println("객체를 하나씩 가져와서 처리 element : "+element);// 에러 예제if(element.equals("Java")){whileSet.remove(element);// exception 발생// Exception in thread "main" java.util.ConcurrentModificationException// at java.base/java.util.HashMap$HashIterator.nextNode(HashMap.java:1597)// at java.base/java.util.HashMap$KeyIterator.next(HashMap.java:1620)// at ch15.collection_framwork.HashSetExample.main(HashSetExample.java:73)}}}}
위 문제 발생을 아래와 같이 해결 할 수 있다.
publicclassIteratorRemoveTroubleshooting{publicstaticvoidmain(String[]args){// file: "IteratorRemoveTroubleshootingExample.java"Set<String>whileSet=newHashSet<String>();whileSet.add("Java");whileSet.add("Spring");whileSet.add("JDBC");whileSet.add("JPA");// 문제 해결 예제Iterator<String>iterator=whileSet.iterator();while(iterator.hasNext()){Stringelement=iterator.next();System.out.println("while() element : "+element);if(element.equals("Spring")){iterator.remove();}}}}
컬렉션 자료구조(Set)
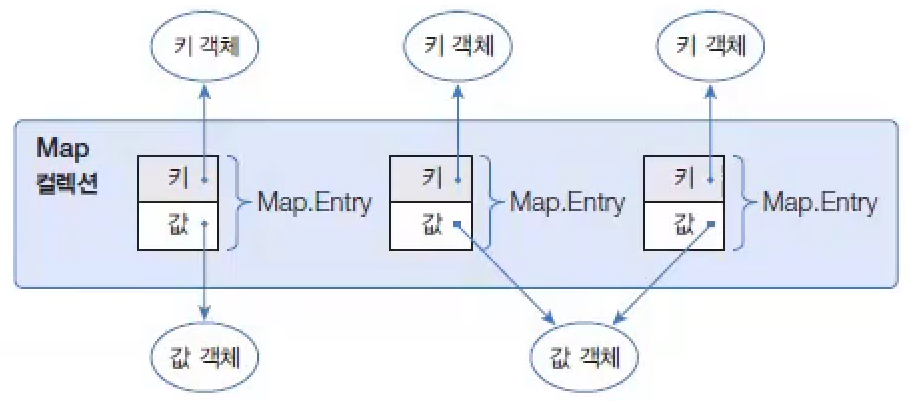
Map Collection
Properties
Properties는 Hashtable의 자식 클래스이기 때문에 Hashtable의 특징을 그대로 가지고 있다.
Properties키와 값을 String 타입으로 제한한 컬렉션이다. Properties는 주로 확장자가 .properties인 프로퍼티 파일을 읽을 때 사용한다.
프로퍼티 파일은 다음과 같이 키와 값이 = 기호로 연결되어 있는 텍스트 파일이다.
일반 텍스트 파일과 다르게 ISO 8859-1 문자셋으로 저장되며, 한글이리 경우에는 \u+유니코드로 표현되어 저장된다.
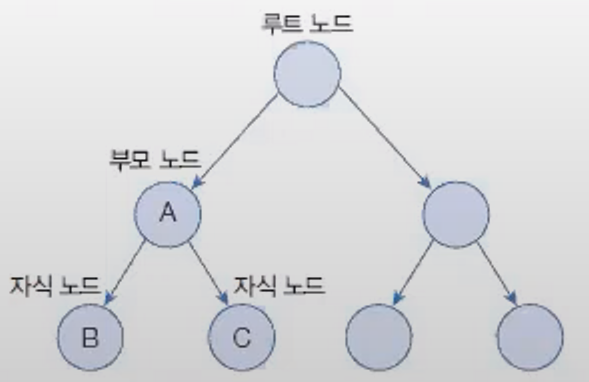
컬렉션 프레임워크는 검색 기능을 강화시킨 TreeSet과 TreeMap을 제공한다. 이름에서 알 수 있듯이 TreeSet은 Set 컬렉션이고, TreeMap은 Map 컬렉션이다.
TreeSet
TreeSet은 이진 트리binary tree를 기반으로 한 Set 컬렉션이다. 이진 트리는 여러 개의 노드node가 트리 형태로 연결된 구로조, 루트 노드root node라고 불리는 하나의 노드에서 시작해 각 노드에 최대 2개의 노드를 연결할 수 있는 구조를 가지고 있다.
TreeSet에 객체를 저장하면 다음과 같이 자동으로 정렬된다. 부모 노드의 객체와 비교해서 낮은 것은 왼쪽 자식 노드에, 높은 것은 오른쪽 자식 노드에 저장한다.
비교 기능이 있는 Comparable 구현 객체를 TreeSet에 저장하거나 TreeMap의 키로 저장하는 것이 원칙이지만, 비교 기능이 없는 Comparable 비구현 객체를 저장하고 싶다면 방법은 없진 않다.
TreeSet과 TreeMap을 생성할 때 비교자Comparator를 다음과 같이 제공하면 된다.
publicclassComparatorImpl{// new ComparatorImpl() ==> 비교자TreeSet<E>treeSet=newTreeSet<E>(newComparatorImpl());TreeMap<K,V>treeMap=newTreeMap<K,V>(newComparatorImpl());}
비교자는 Comparator 인터페이스를 구현한 객체를 말하는데, Comparator 인터페이스에는 compare() 메서드가 정의도어 있다.
리턴 타입
메서드
설명
int
compareTo(T o1, T 02)
o1과 o2가 동등하다면 0을 리턴 o1이 o2보다 앞에 오게 하려면 음수를 리턴 o1이 o2보다 뒤에 오게 하려면 양수를 리턴
컬렉션 프레임워크의 대부분의 클래스들은 싱글 스레드 환경에서 사용할 수 있도록 설계되었다.
그렇기 때문에 여러 스레드가 동시에 컬렉션에 접근한다면 의도하지 않게 요소가 변경될 수 있는 불안전한 상태가 된다.
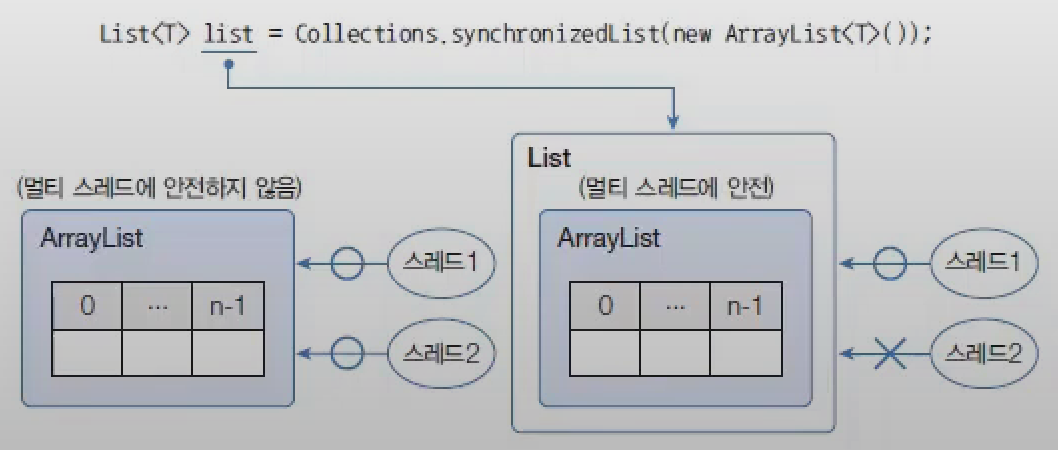
Vector와 Hashtable은 동기화된(synchronized) 메서드로 구성되어 있기 때문에 멀티 스레드 환경에서 안전하게 요소를 처리할 수 있지만, ArrayList, HashSet, HashMap은 동기화된 메서드로 구성되어 있지 않아 멀티 스레드 환경에서 안전하지 않다.
이 경우 멀티 스레드 환경에서 사용하고 싶을 때가 있을 것이다. 이런 경우를 대비해서 컬렉션 프레임워크는 비동기화된 메서드를 동기화된 메서드로 래핑하는 Collection의 synchronizedXXX() 메서드를 제공한다.
리턴 타입
메서드(매개변수)
설명
List<T>
synchronizedList(List<T> list)
List를 통기화된 List로 리턴
Map<K, V>
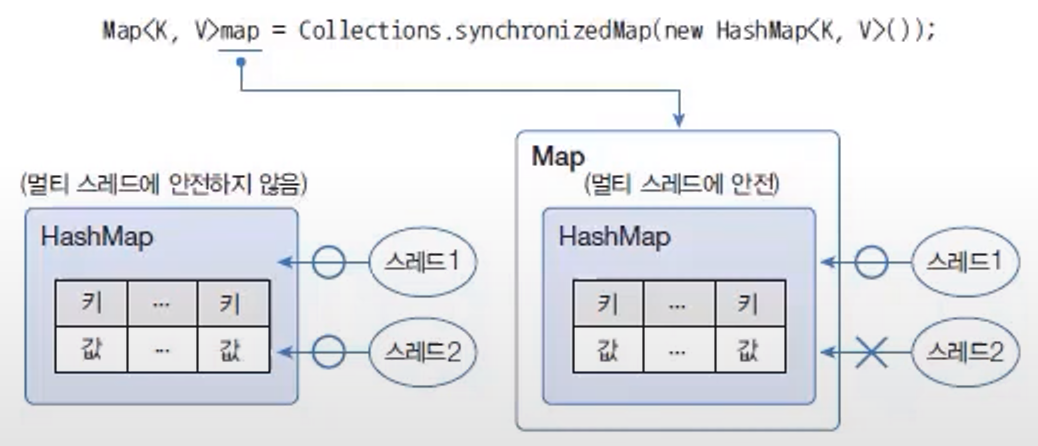
synchronizedMap(Map<K, V> m)
Map를 통기화된 Map로 리턴
Set<T>
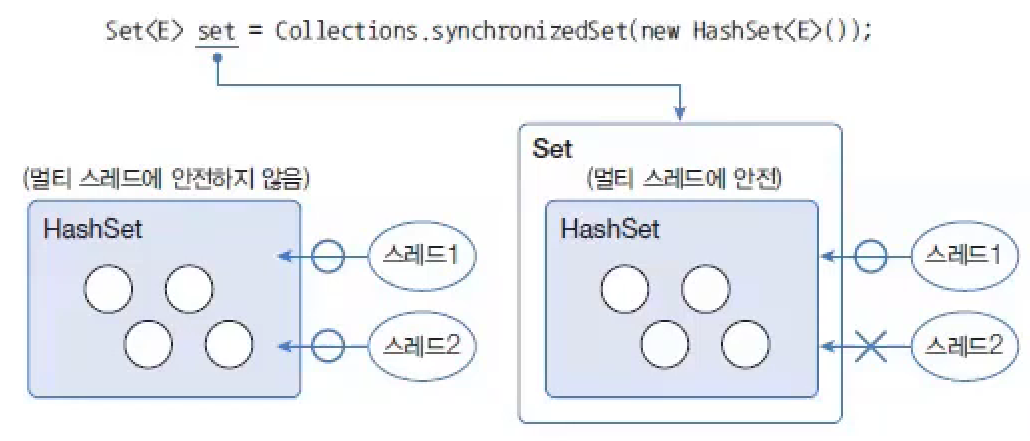
synchronizedSet(Set<T> s)
Set를 통기화된 Set로 리턴
ArrayList를 Collections.synchronizedList() 메서드를 사용해서 동기화된 List로 변환된다.
HashSet를 Collections.synchronizedSet() 메서드를 사용해서 동기화된 Set로 변환된다.
HashSet를 Collections.synchronizedMap() 메서드를 사용해서 동기화된 Map로 변환된다.
publicclassSynchronizedMap{Map<Integer,String>map=Collections.synchronizedMap(newHashMap<>());// 출력 : 일정한 값Map<Integer,String>map=newHashMap<>();// 출력 : 일정하지 않은 값}
HashMap은 두 스레드가 동시에 put() 메서드를 호출할 수 있기 때문에 경합이 발생하고 결국 하나만 저장되기 때문이다.
하지만 동기화된 Map은 한 번에 하나의 스레드만 put() 메서드를 호출할 수 있기 때문에 경합이 발생하지 않는다.
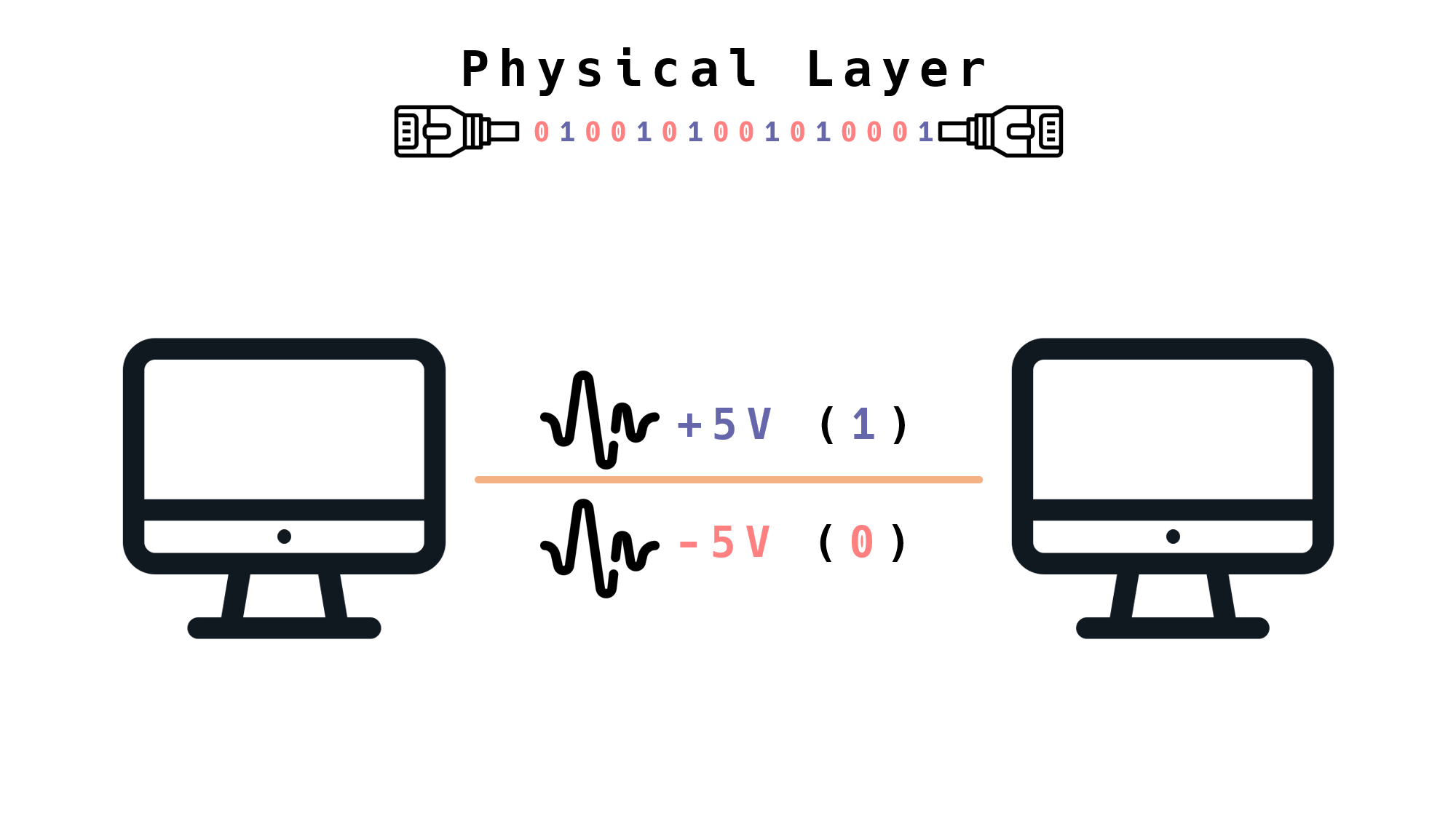
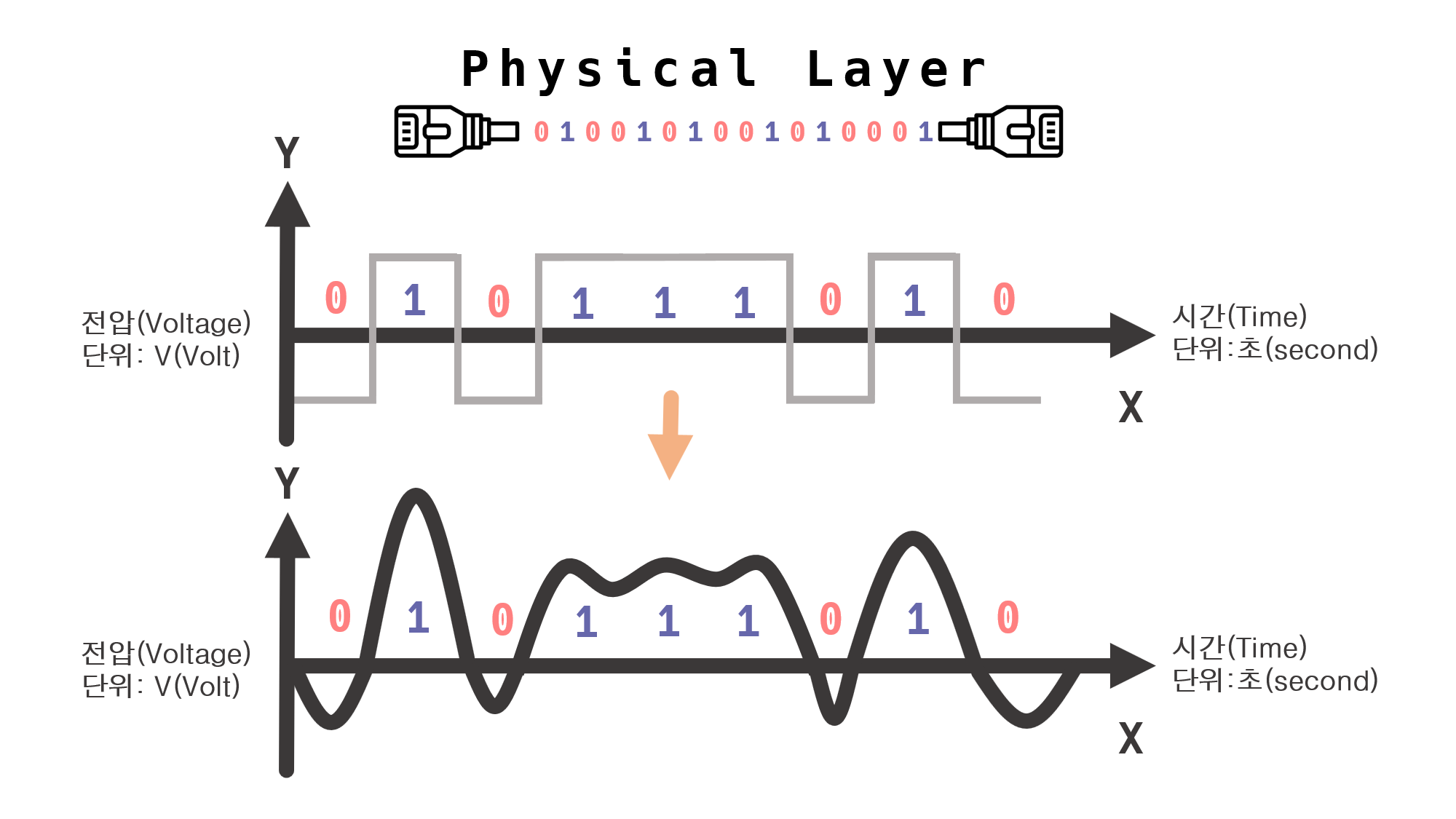
1을 보낼 때는 +5V의 전기를, 0을 보낼 때는 -5V의 전기를 전선으로 보낸다고 가정해 보자.
이렇게 하면 0과 1의 전송이 가능할 것이다.
하지만, 위 방법은 문제가 있는데, 실제론 잘 작동하지 않는다.
실제론 잘 작동하지 않는 문제 발생
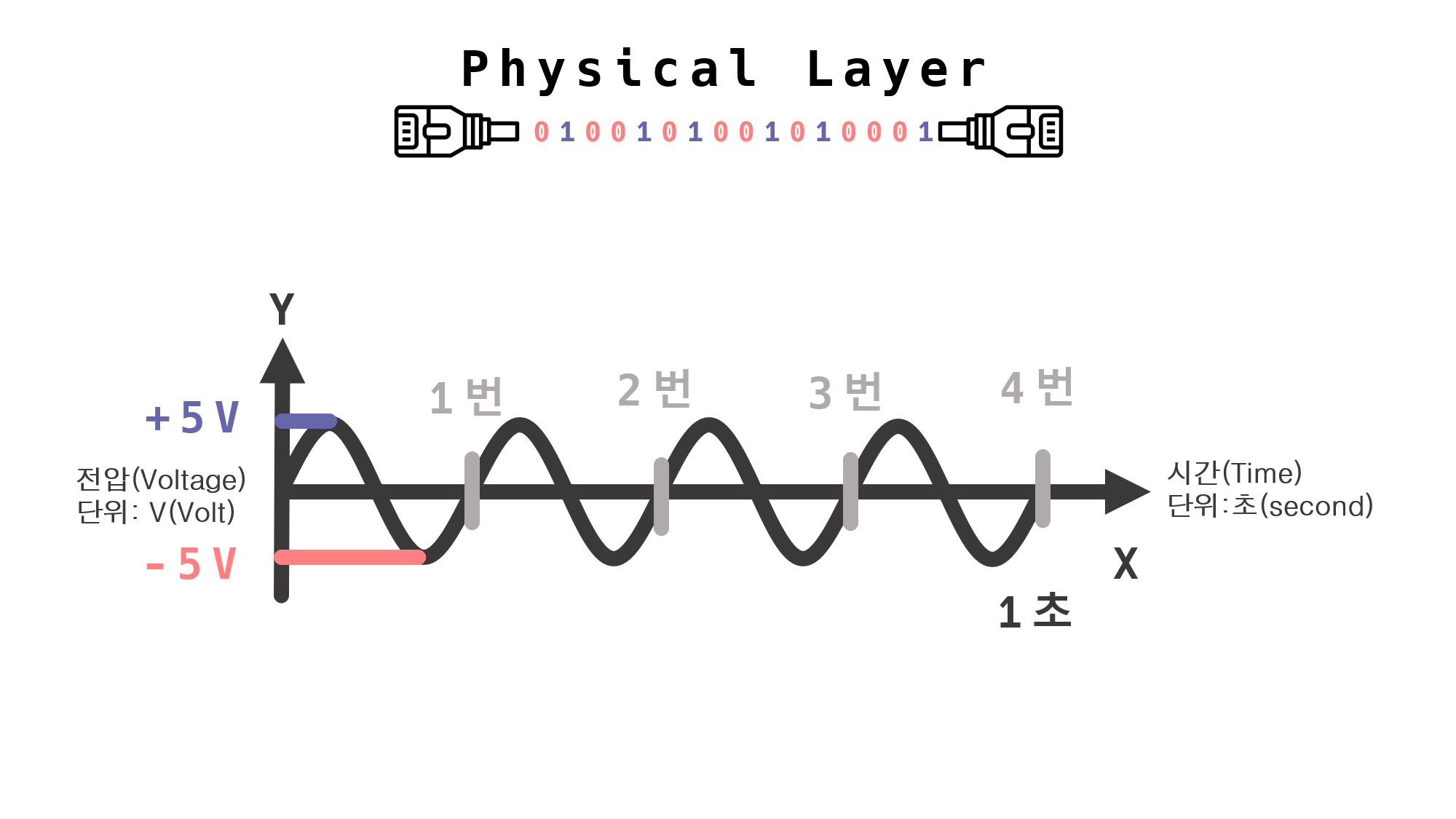
“전자기파를 표현하는 Sin 함수 그래프”
주파수란? 1초당 진동한 진동 횟수. 단위 : Hz(헤르츠)
1초당 진동한 진동 횟수를 Hz(헤르츠)라고 하고, 위 예시는 1초에 4번의 사이클이기 때문에 4Hz(헤르츠)가 된다.
위 그래프는 파동이 진행되는 내내 주파수가 4Hz(헤르츠)이다.
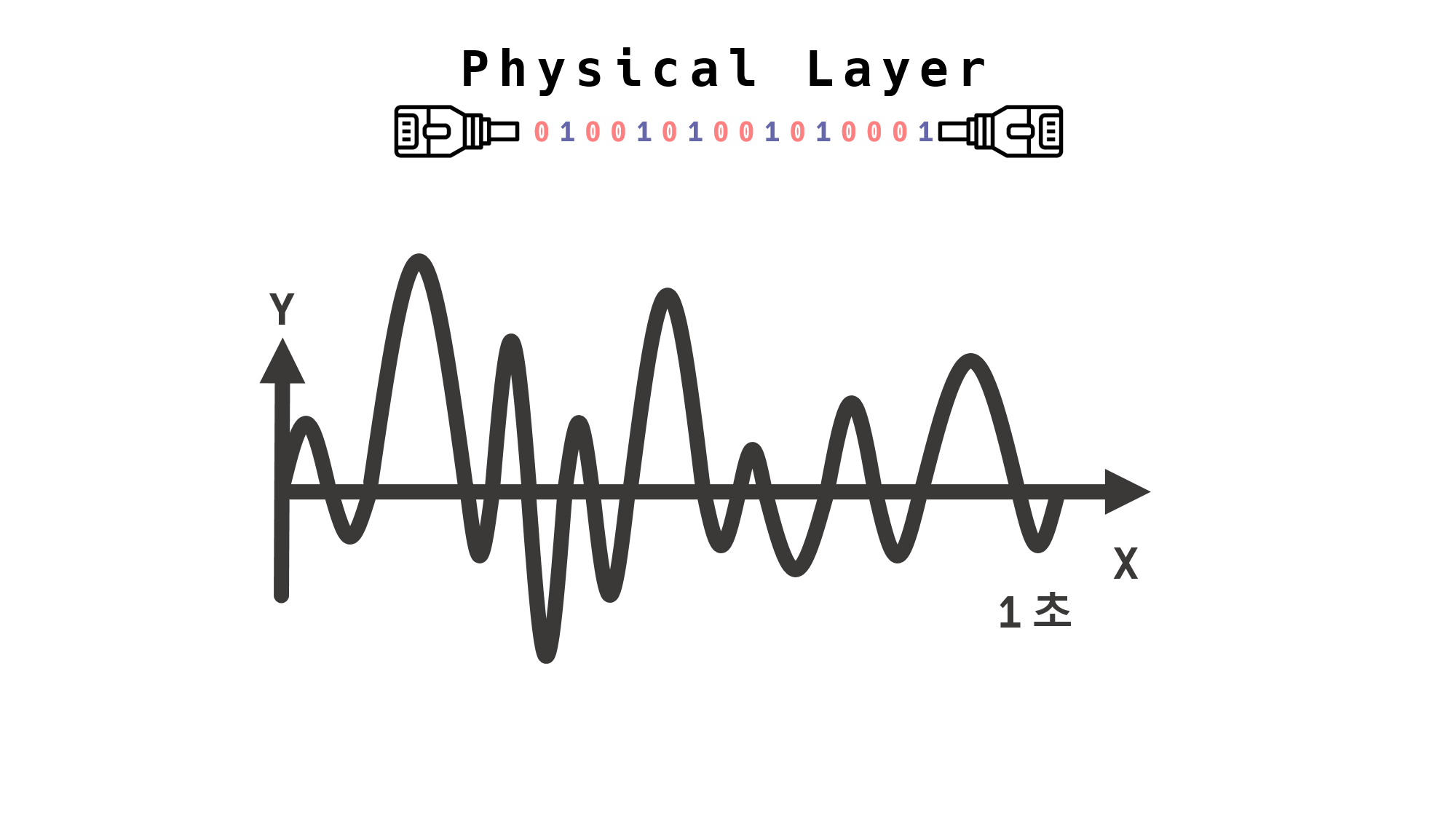
만약, 일정하지 않은 주파수이면?
“이런 전자기파는 주파수 값이 숫자 하나로 고정되지 않고, 파동이 진행되는 동안 주파수 값이 계속 변하게 된다.”
하지만, 위 그림처럼 일정하지 않은 주파수이면 어떻게 되는 것일까?
위 전자기파의 주파수 최솟값이 1Hz, 최댓값이 10Hz라고 생각해 보자.
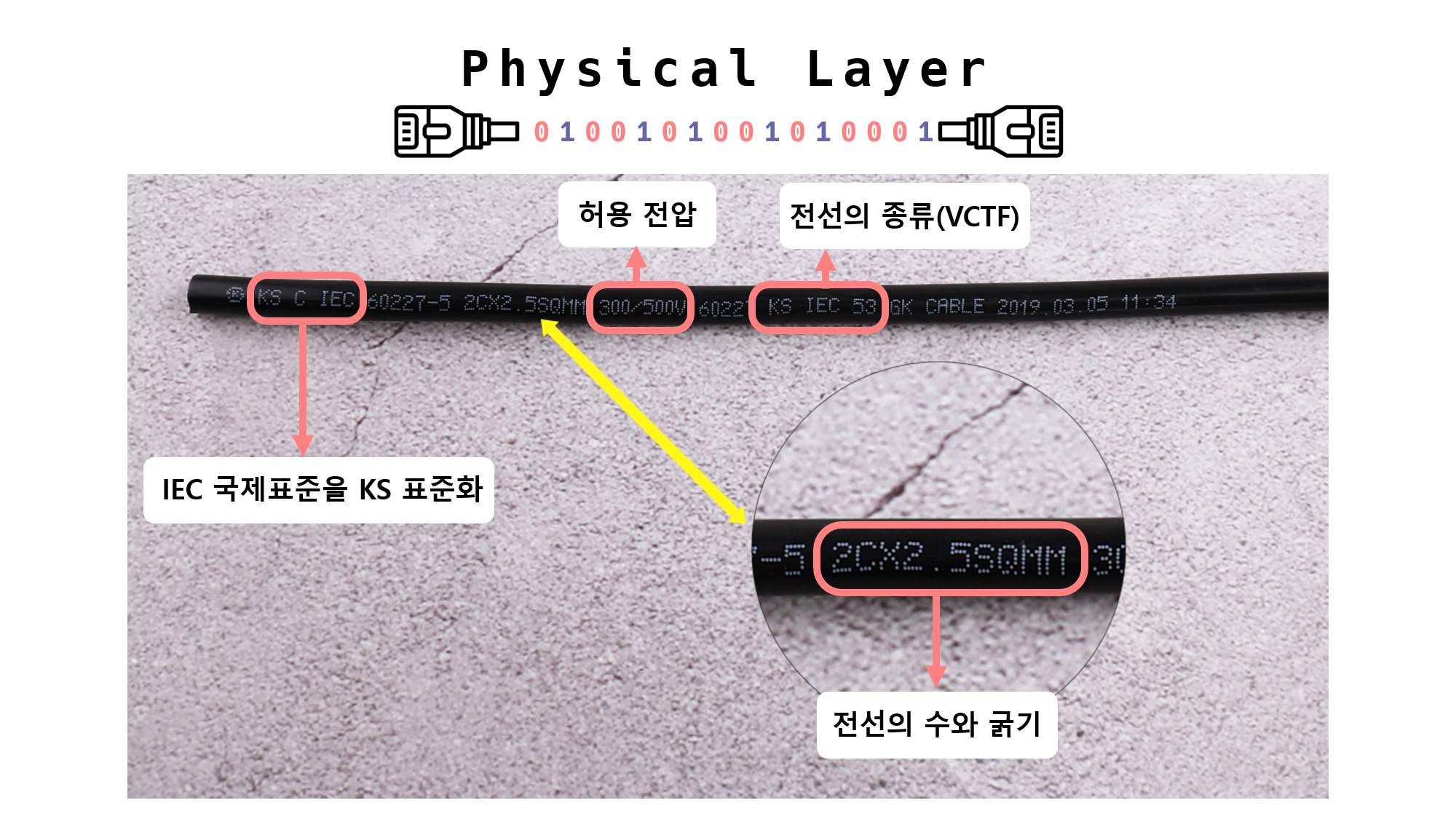
그런데, 모든 전선에는 저항이 있어 전선에 맞는 허용 범위의 전류와 전압이 있다.
즉, 전선은 모든 전류, 그리고 모든 주파수를 다 통과시키지 못하고 허용 범위가 생긴다.
모든 전선에는 저항이 있어 전선에 맞는 허용 범위의 전류와 전압이 존재
“KS C IEC - IEC(국제 전기 표준화 기구)를 KS(한국 산업 표준)에 맞게 표준화” “2CX 2.5SQ MM - 2core(2가닥의 전선)와 각 전선의 굵기는 2.5SQ (MM) 2.5mm” “300(상전압)/500(선간전압)V - 허용 범위의 전압(Volt), 국내 가정용 220V 표준” “KS C IEC 53 - 케이블의 종류(해당 케이블은 VCTF)”
간단하게 설명하자면, 우리나라는 그 당시 미국의 영향을 많이 받아 미국 방식을 채택하게 된 것.
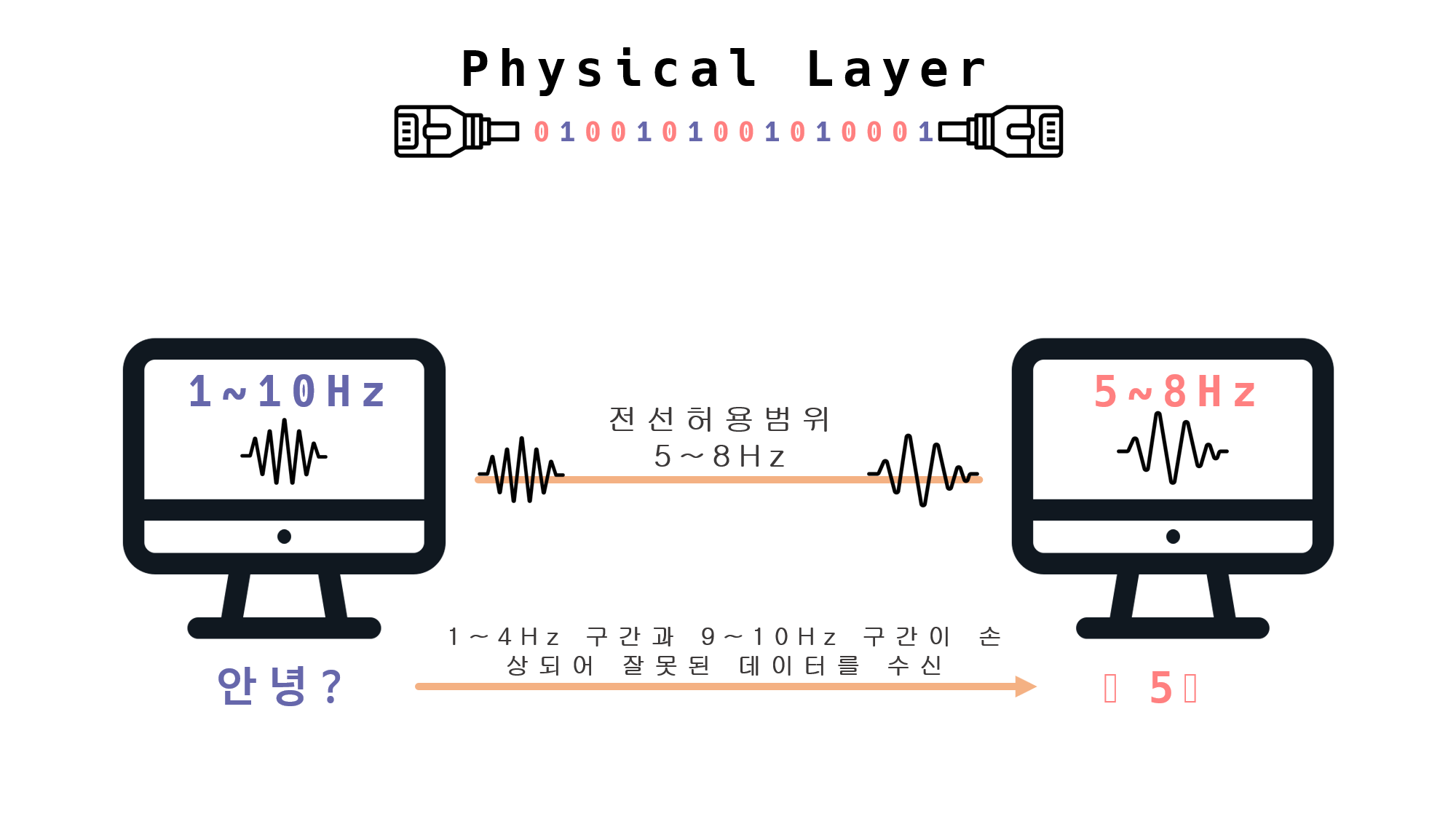
잘못된 데이터 수신
“Hz의 허용 범위가 다른 전선의 사용한 경우 잘못된 데이터를 수신할 수 있게 되는 문제점 발생”
보내는 쪽에서는 1~10Hz의 데이터 안녕을 보낸다.
하지만, 전선의 주파수 허용 범위가 5~8Hz여서 1~4Hz, 9~10Hz의 데이터가 손상이 된다.
그래서 받은 데이터는 전혀 다른 데이터를 받게 되는 문제가 발생한다.
그런데, 앞에서 두 대의 컴퓨터가 통신하려면 0과 1을 주고받을 수 있으면 된다고 했는데, 그 방법은 두 대의 컴퓨터에 다음과 같은 전자기파를 주고받을 수 있으면 된다.
수직/수평선이 있는 전자기파
“그런데, 수직선과 수평선이 있는 전자기파는 항상 0~무한대 Hz의 주파수 범위를 갖는다?”
“수직선과 수평선이 있는 전자기파는 편파(polarized) 전자기파이며, 편파 전자기파는 진폭이 한 방향으로 고정되어 있고, 이러한 편파 전자기파는 하나의 평면에서 전파가 진행된다.” “따라서, 수직선과 수평선이 있는 전자기파의 주파수 범위는 항상 0 ~ 무한대(Hz)를 갖는다. 왜냐하면 편파 전자기파는 진폭이 한 방향으로 고정되어 있으며, 주파수는 전파의 진동수를 나타내기 때문이다.”
“따라서, 수직선과 수평선이 있는 전자기파는 특정한 주파수 범위에서만 발생하는 것이 아니라, 전체 주파수 범위에서 발생할 수 있다.”
무한 vs 유한 전자기파
위 내용을 나만의 해석을 통해 조금 더 쉽게 이해하자면…
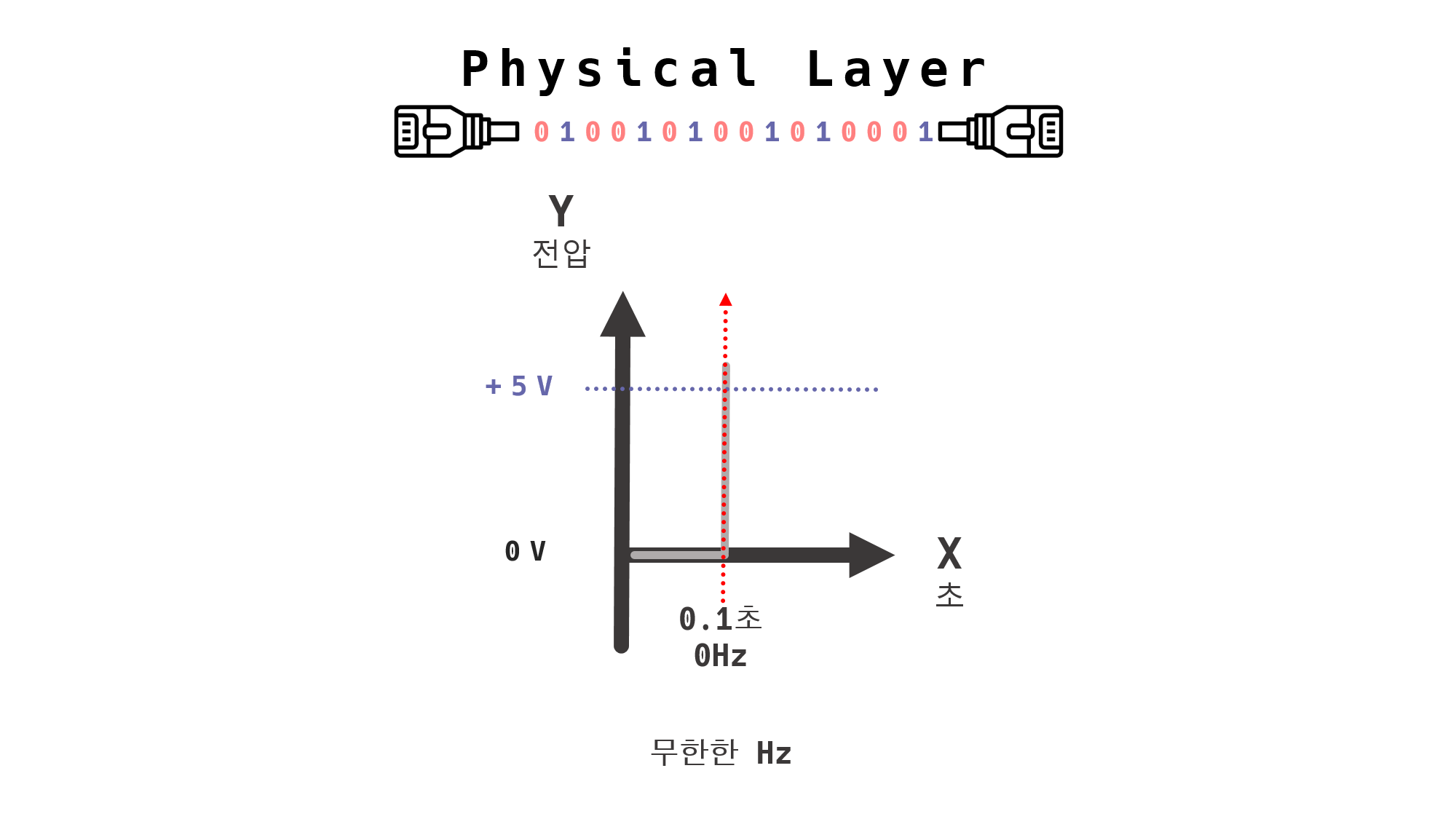
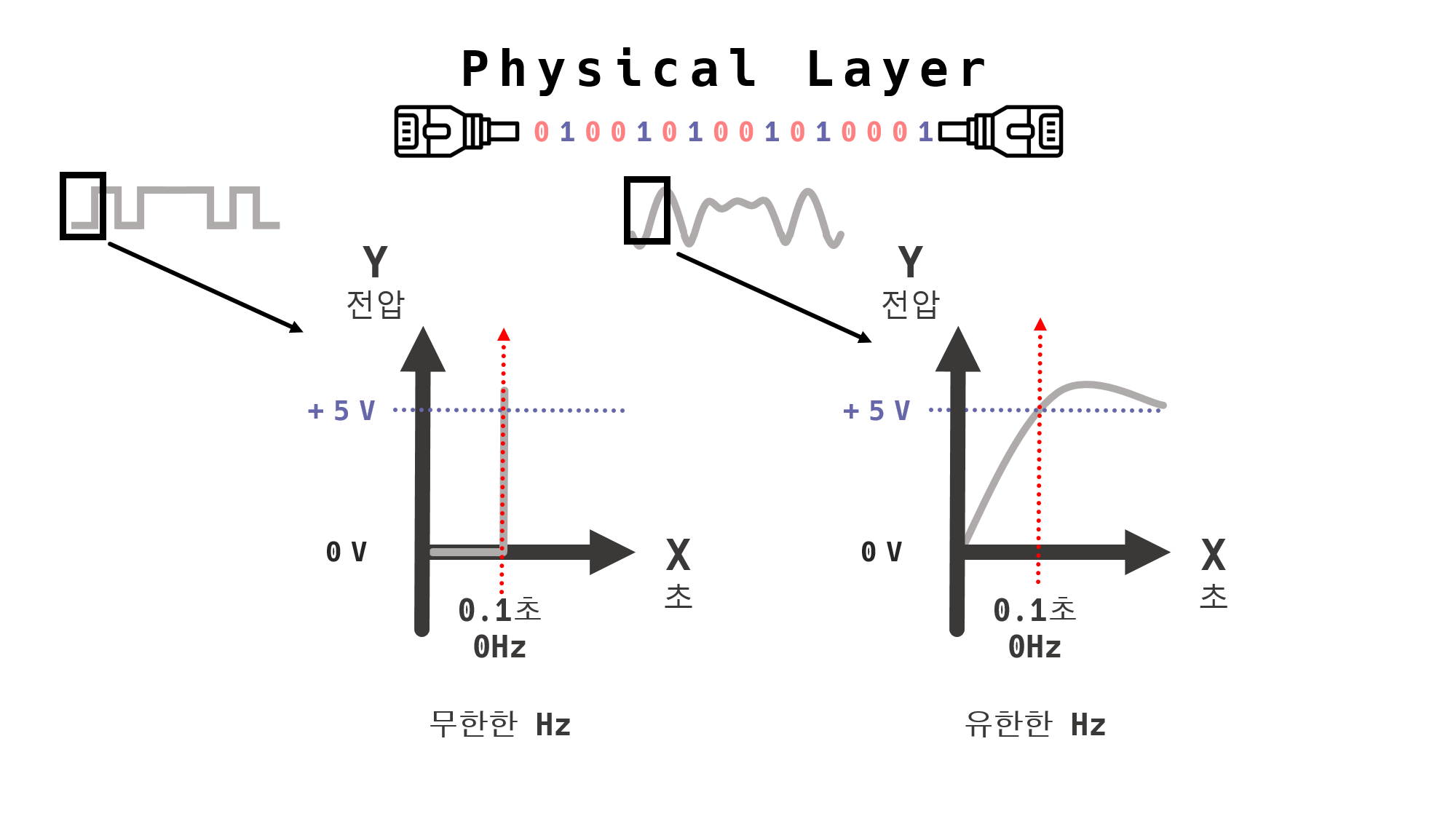
왼쪽 그래프에서는 0초에서 0.1초의 전압은 0V이기 때문에 전자기파가 생겨나지 않는다. 즉, 0Hz의 주파수를 갖는다.
0.1초에서부터 +5V 이상의 수직적 전압이 발생하여 전자기파가 생겨났다.
시간의 흐름에 따라 서서히 증가 또는 감소하는 것이 아니라 해당 시간에 수직으로 생겨난 전압이기 때문에 0.1초에는 측정 불가한무한대의 Hz를 갖는다.
오른쪽 그래프에서는 시간에 따라 서서히 전압이 증가 또는 감소하는 것을 볼 수 있다.
따라서, 왼쪽 그래프는 시간이 변하지 않고 해당 시간에 수직적이고 무한한 전압이 생성되었기 때문에 측정 불가한 무한대의 Hz를 갖는 전자기파가 생성된다.
오른쪽 그래프는 시간에 따라 변화하는 전압이 발생하므로 측정 가능한 유한대의 Hz를 갖는 전자기파가 생성된다.
결론은, 이러한 무한한 Hz의 전기신호를 통과시킬 수 있는 전선은 없다.
그렇다면 0과 1의 신호를 어떻게 전송해야 할까?
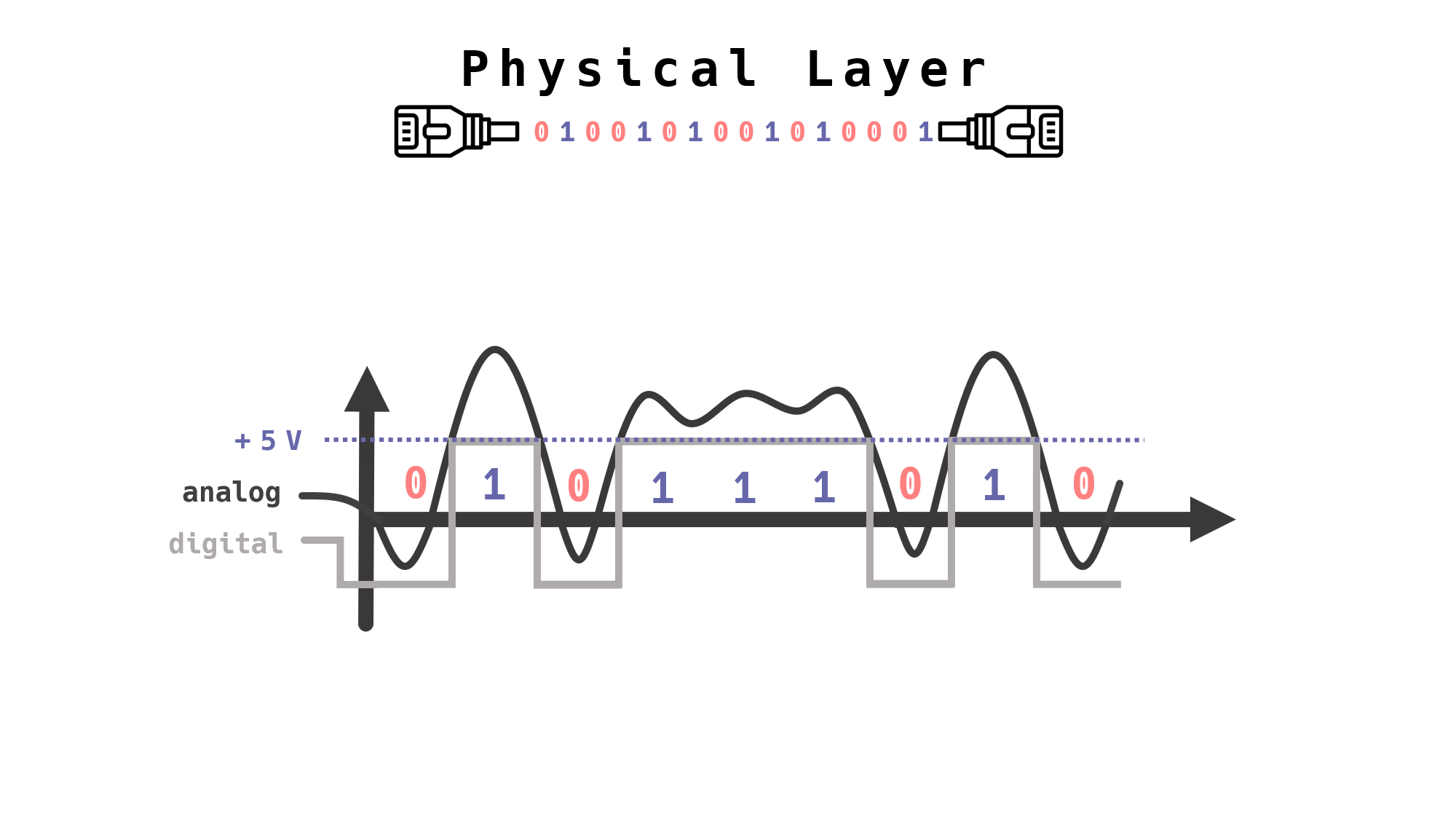
디지털 신호를 아날로그 신호로
“디지털 신호를 아날로그 신호로 바꿔서 전송해야 한다.”
아날로그 신호의 특징
아날로그 신호는 끊김 없이 연속된 신호로 이루어져 있다.
신호의 세기를 아주 정밀하게 표현이 가능하다.
거리에 따라 신호의 세기가 약해지면서 결국 소멸되는 특징을 가지고 있다.
전자기파의 스펙트럼을 통해 다양한 데이터들을 송/수신할 수 있게 되었다.
디지털 신호의 특징
디지털 신호는 1로 표현하고 싶을 땐 특정 전압 이상을 가하고, 0으로 표현하고 싶을 땐 특정 전압의 미만로 가해 표현한다.
즉, 1을 5V라고 가정할 때 1로 표현하고 싶으면 5V이상의 전압을 가하고, 0으로 표현하고 싶을 땐 5V미만의 전압을 가하게 된다.
디지털 신호 그래프의 0은 끊어진 것처럼 보이지만 사실 끊어진 게 아니라 특정 전압 미만이기 때문에 0으로 그래프상 표시한 것뿐이다. 실제론 계속 전류는 흐른다.
아날로그 신호와 디지털 신호를 합치면
위 그림처럼 컴퓨터는 특정 전압(예 5V)을 기준으로 미만은 0으로, 이상은 1로 인식하여 2진수의 데이터를 송/수신하게 된다.
그렇게 송/수신한 데이터를 가지고 어떠한 기능((예) 해석, 출력, 등등)을 실행하게 된다.
아날로그 신호의 데이터화
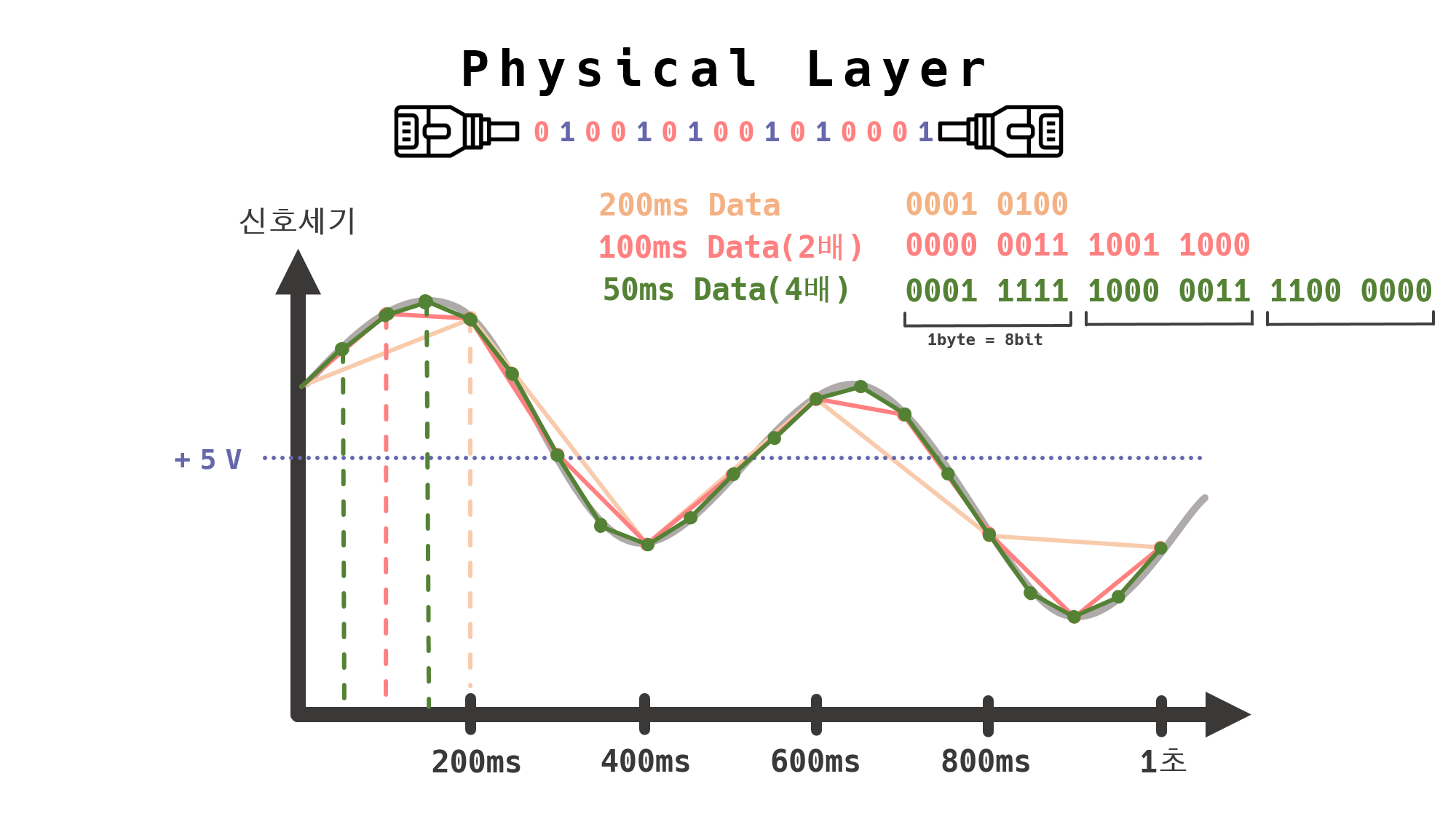
“1byte는 8bit이다.”
위 그래프는 1초 동안 발생한 아날로그 신호를 디지털 신호로 해석한 그래프이다.
위 그래프에서 볼 수 있듯이 200ms는 1btye의 데이터를, 100ms는 2btye의 데이터를, 50ms는 3btye의 데이터를 수집할 수 있는 것을 볼 수 있다.
1초의 시간을 촘촘히 측정할 수 있게 된다면 더 많은 양의 데이터를 주고받을 수 있게 된다.
또한, 조금 더 촘촘히 많은 데이터를 수집할 수 록 아날로그 데이터에 굉장히 가까워진다.
하지만, 아무리 아날로그 신호를 디지털 신호로 바꾸어도 어쩔 수 없이 데이터 왜곡은 생기기 마련이다.
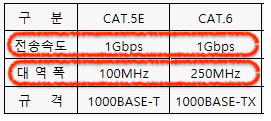
가정에서 많이 사용하는 CAT5.E Cable
CAT.5E vs CAT.6 차이
“bps = bit per second(1초당 몇 비트를 전송하는가?) 즉, 100메가 인터넷 속도는 100Mbps이고 이는 1초에 100Megabit 즉, 12.5MB(메가 바이트)의 데이터를 다운로드할 수 있다는 이야기다. 또한 100MHz(100 메가헤르츠) 주파수의 전파는 1초에 100만 번 진동한다는 의미이다.”
1초에 100MHz의 데이터 전송이 가능한 케이블이다.
참고로, 1초에 진동하는 주파수가 많을수록 주파수가 높다고 표현을 한다.
주파수가 높을수록 빛과 같이 직진성이 강해서 특정 방향으로 송신하는데 유리하고 많은 정보를 실을 수 있다는 장점이 있다.
하지만, 비가 오거나 안개가 많이 낀 날은 공기 중에 물방울과 수증기가 많아지기 때문에 전파가 흡수되어 멀리 전파될 수 없다는 단점이 있다.
반대로 주파수가 낮은 전파는 직진성은 약하지만 장애물을 뛰어넘는 특성이 있어 넓은 지역을 커버하는데 유리다. 하지만 주파수가 낮을수록 실을 수 있는 데이터 정보량은 적다.
위에서 예시로 든 50ms(1초에 2번의 주파수)와 1초에 100MHz(1초에 1,000,000번 - 100만 번의 주파수)의 데이터 수집 양에 엄청난 차이를 느낄 수 있다.
참고로, “현재 통신사에서 1기가 인터넷을 최대 속도로 서비스하고 있는 상황에서 케이블의 종류에 따른 속도의 차이는 없다.”
다만, 차후 2.5G나 5G의 속도가 상용화되면 지금의 1Gbps보다 빠른 속도를 제공받을 수 있다는 이야기.
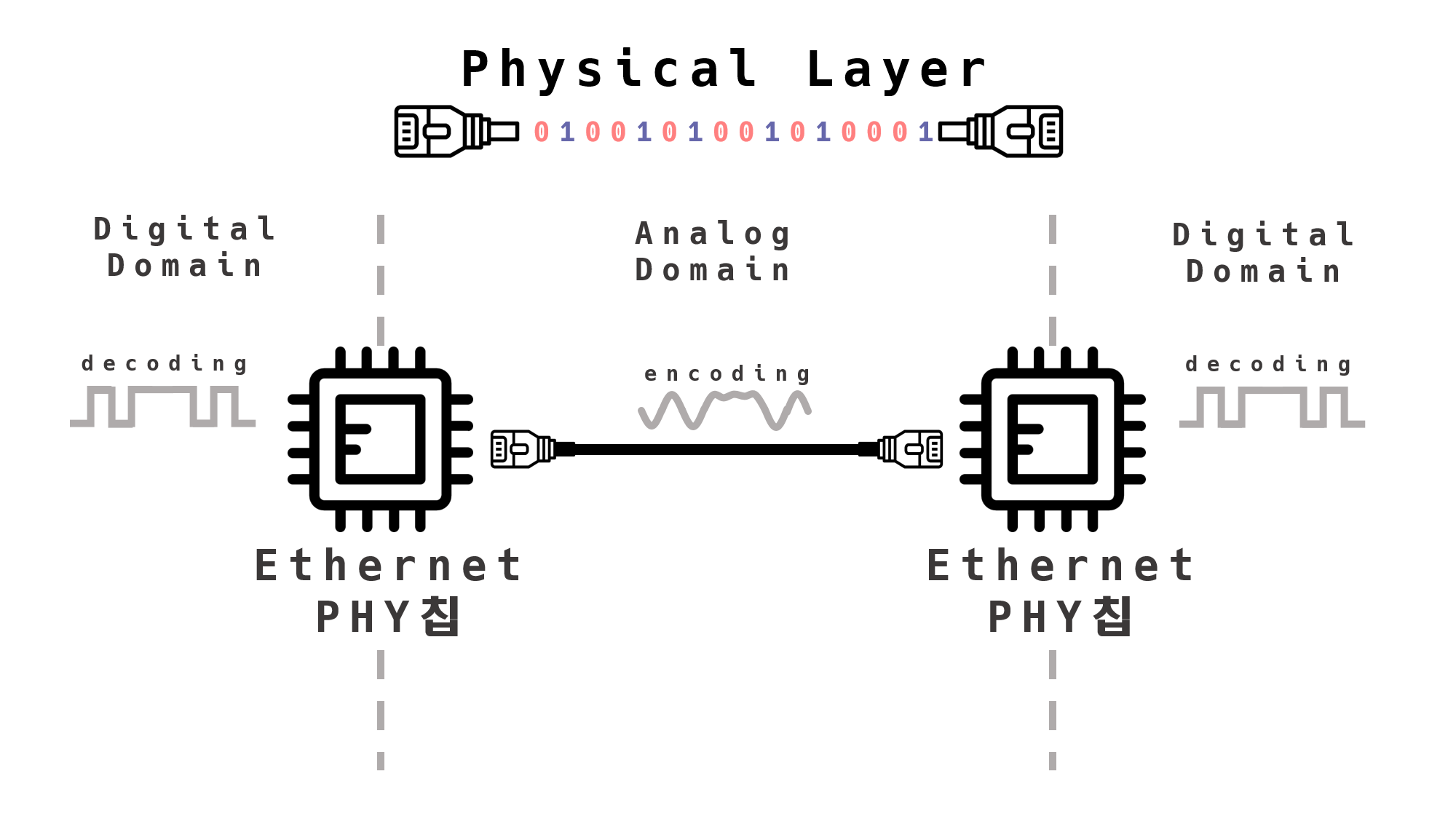
위 전파(전자기파) 신호를 담당하는 하드웨어 PHY 칩
Physical Layer는 하드웨어적으로 구현되어 있다.
PHY 칩이 아날로그 신호를 디지털 신호(decoding)로,
디지털 신호를 아날로그 신호(encoding)로 변환해 주는 하드웨어이다.
그래서 결국 Physical Layer란?
물리적인 전선과 Phy 칩을 통해 0과 1의 나열된 신호를 통신하는 계층이다.
0과 1의 나열된 디지털 신호를 아날로그 신호로 바꾸어 전선을 통해 송신하게 된다. -> encoding
아날로그 신호가 들어오면 0과 1의 나열로 해석한다. -> decoding
물리적으로 연결된 두 대의 컴퓨터가 0과 1의 나열을 주고받을 수 있게 해주는 모듈(module)이다.
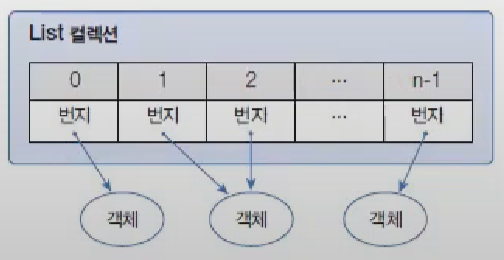
“List 컬렉션은 객체 자체를 저장하는 것이 아니라 객체의 번지를 저장한다. 또한 동일한 객체를 중복 저장할 수 있는데, 이 경우에는 동일한 번지가 저장된다. null 또한 저장이 가능하다.”
importjava.util.List;publicclassArrayList{publicstaticvoidmain(String[]args){List<E>list=newArrayList<E>();// E에 지정된 타입의 객체만 저장List<E>list=newArrayList<>();// E에 지정된 타입의 객체만 저장Listlist=newArrayList();// 모든 타입의 객체를 저장}}
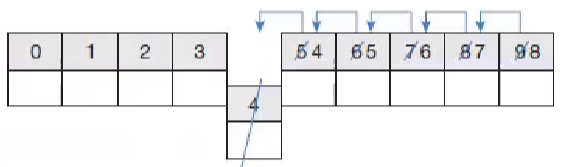
ArrayList 컬렉션에 객체를 추가하면 인덱스 0번부터 차례대로 저장된다.
특정 인덱스의 객체를 제거하면 바로 뒤 인덱스부터 마지막 인덱스까지 모두 앞으로 1씩 당겨진다.
마찬가지로 특정 인덱스에 객체를 span style=”color:#ff8080”>삽입</span>하면 해당 인덱스부터 마지막 인덱스까지 모두 1씩 밀려난다.
“따라서 빈번한 객체 삭제와 삽입이 일어나는 곳에서는 ArrayList를 사용하는 것은 바람직하지 않다. 대신 이런 경우라면 LinkedList를 사용하는 것이 좋다.”
퇴근하면서 들은 생각이 인강을 듣기만 하지 말고 코드로 옮겨서 정리해야겠다 라는 생각이 들었다.
집에 와서 밥을 먹고 운동한 후에 오전에 공부한 내용을 정리하였다.
markdown 문법 중 테이블 컬럼또는 행을 병합하던 중 문제가 발생했는데 합쳐지지가 않는 것이었다.
1시간의 사투 후 결국 아래와 같이 방법을 찾아냈는데 바로 jekyll-spaceship라는 플러그인을 설치하면 잘 되었다.
# file: "Gemfile"# If you have any plugins, put them here!group:jekyll_pluginsdogem'jekyll-spaceship'end
# file: "_config.yml"plugins:-jekyll-spaceship
# file: "_config.yml"# Where things arejekyll-spaceship:# default enabled processorsprocessors:-table-processor-mathjax-processor-plantuml-processor-mermaid-processor-polyfill-processor-media-processor-emoji-processor-element-processormathjax-processor:src:-https://polyfill.io/v3/polyfill.min.js?features=es6-https://cdn.jsdelivr.net/npm/mathjax@3/es5/tex-mml-chtml.jsconfig:tex:inlineMath:-['$','$']-['\(','\)']displayMath:-['$$','$$']-['\[','\]']svg:fontCache:'global'optimize:# optimization on building stage to check and add mathjax scriptsenabled:true# value `false` for adding to all pagesinclude:[]# include patterns for math expressions checking (regexp)exclude:[]# exclude patterns for math expressions checking (regexp)plantuml-processor:mode:default# mode value 'pre-fetch' for fetching image at building stagecss:class:plantumlsyntax:code:'plantuml!'custom:['@startuml','@enduml']src:http://www.plantuml.com/plantuml/svg/mermaid-processor:mode:default# mode value 'pre-fetch' for fetching image at building stagecss:class:mermaidsyntax:code:'mermaid!'custom:['@startmermaid','@endmermaid']config:theme:defaultsrc:https://mermaid.ink/svg/media-processor:default:id:'media-{id}'class:'media'width:'100%'height:350frameborder:0style:'max-width:600px;outline:none;'allow:'encrypted-media;picture-in-picture'emoji-processor:css:class:emojisrc:https://github.githubassets.com/images/icons/emoji/
얼른 커밋 하고 독학사 공부해야겠다…😭
2023-02-21
컬렉션 자료구조(Vector, LinkedList)
List Collection
오늘도 영한 님의 인강을 들으면서 출근을 했다.
어제 자기 전에 markdown 테이블 병합한 걸 보고 싶어 빌드 된 나의 블로그를 확인해 보았는데, 결론적으론 나의 local쪽에서만 가능한 것으로 확인되었다.
차이점은 Vector는 동기화된(synchronized) 메서드로 구성되어 있기 때문에 멀티 스레드가 동시에 Vector() 메서드를 실행할 수 없다는 것이다.
그렇기 때문에 멀티 스레드 환경에서 안전하게 객체를 추가 또는 삭제할 수 있다.
importjava.util.List;importjava.util.Vector;publicclassVector{publicstaticvoidmain(String[]args){List<E>list=newVector<E>();// E에 지정된 타입의 객체만 저장List<E>list=newVector<>();// E에 지정된 타입의 객체만 저장Listlist=newVector();// 모든 타입의 객체를 저장}}
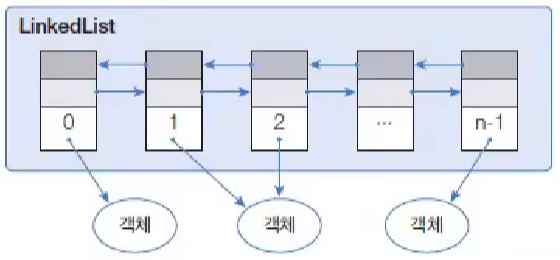
LinkedList는 ArrayList와 사용 방법은 동일하지만 내부 구조는 완전히 다르다.
ArrayList는 내부 배열에 객체를 저장하지만, LinkedList는 인접 객체를 체인처럼 연결해서 관리한다.
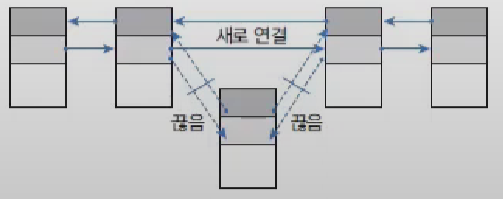
LinkedList는 특정 위치에서 객체를 삽입하거나 삭제하면 바로 앞뒤 링크만 변경하면 되므로 빈번한 객체 삭제와 삽입이 일어나느 곳에서는 ArrayList보다 좋은 성능을 발휘한다.
importjava.util.List;importjava.util.LinkedList;publicclassLinkedList{publicstaticvoidmain(String[]args){List<E>list=newLinkedList<E>();// E에 지정된 타입의 객체만 저장List<E>list=newLinkedList<>();// E에 지정된 타입의 객체만 저장Listlist=newLinkedList();// 모든 타입의 객체를 저장}}
“스레드가 사용중인 객체를 다른 스레드가 변경할 수 없도록 하려면 스레드 작업이 끝날 때까지 객체에 잠금을 걸면 되는데, 이를 위해 Java는 synchronized 메서드와 블록을 제공한다.”
publicclassSynchronized{// example 1publicsynchronizedvoidmathodA(){// 단 하나의 스레드만 실행하는 영역}// example 2publicvoidmethodB(){// 여러 스레드가 실행할 수 있는 영역synchronized(공유객체){// 단 하나의 스레드만 실행하는 영역}// 여러 스레드가 실행할 수 있는 영역}}
스레드는 자신의 run() 메서드가 모두 실행되면 자동적으로 종료되지만, 경우에 따라서는 실행 중인 스레드를 즉시 종료할 필요가 있다.
유튜브 같은 동영상을 끝까지 보지 않고 사용자가 멈춤을 요구하는 경우이다.
스레드를 안전하게 종료하는 방법은 사용하던 리소스들을 정리하고 run() 메서드를 빨리 종료하는 것.
주로 조건 이용 방법과 interrup() 메서드 이용 방법을 사용한다.
조건 이용
스레드가 while 문을 반복 실행할 경우, 조건을 이용해서 run() 메서드의 종료를 유도할 수 있다.
다음 코드는 stop 필드 조건에 따라서 run() 메서드의 종료를 유도한다.
publicclassXXXThreadextendsThread{privatebooleanstop;// stop 필드 선언publicvoidrun(){while(!stop){// stop이 true가 되면 while 문을 빠져나간다.// 스레드가 반복 실행하는 코다;}// 스레드가 사용한 리소스 정리}// 스레드 종료}
interrupt() 메서드는 스레드가 일시 정지 상태에 있을 때 InterruptedException 예외를 발생시키는 역할을 한다.
이것을 이용하면 예외 처리를 통해 run() 메서드를 정상 종료시킬 수 있다.
스레드가 실행 대기/실행 상태일 때에는 interrupt() 메서드가 호출되어도 InterruptException이 발생하지 않는다.
그러나 스레드가 어떤 이유로 일시 정지 상태가 되면, InterruptException예외가 발생한다.
그래서 짧은 시간이나마 일시 정지를 위해 Thread.sleep(1)을 사용한 것.
일시 정지를 만들지 않고도 interrupt() 메서드 호출 여부를 알 수 있는 방법이 있다.
Thread의 interrupted()와 isInterrupted() 메서드는 interrupt() 메서드 호출 여부를 return한다.
boolean status = Thread.interrupted();
boolean status = objThread.isInterrupted();
// file: "InterruptPrintThread.java"publicclassInterruptPrintThreadextendsThread{publicvoidrun(){try{while(true){System.out.println("실행 중");// 방법 1. 일시 정지를 만듦 (InterruptedException 이 발생할 수 있게)Thread.sleep(1);// 방법 2. interrupted() 메서드를 통해 interrupt() 메서드가 호출 되었다면 while 문을 빠져 나가게if(Thread.interrupted()){break;}}}catch(InterruptedExceptione){e.printStackTrace();}System.out.println(("리소스 정리"));System.out.println(("실행 종료"));}}
// file: "InterruptExample.java"publicclassInterruptExample{publicstaticvoidmain(String[]args){Threadthread=newInterruptPrintThread();thread.start();try{Thread.sleep(1000);}catch(InterruptedExceptione){e.printStackTrace();}thread.interrupt();// interrupt() 메서드 호출 }// 결과 -------------------------------// 실행 중// ...// java.lang.InterruptedException: sleep interrupted// at java.base/java.lang.Thread.sleep(Native Method)// at ch14.multi_thread.InterruptPrintThread.run(InterruptPrintThread.java:8)}
// 좀 더 구체적인 스레드 풀 생성publicclasscreateDetailThreadPool{publicstaticvoidmain(String[]args){ExecutorServicethreadPool=newThreadPoolExecutor(3,// 코어 스레드 개수100,// 최대 스레드 개수120L,// 놀고 있는 시간TimeUnit.SECONDS,// 놀고 있는 시간 단위newSynchronousQueue<Runnable>()// 작업 큐);}}
스레드풀 종료
스레드풀의 스레드는 기본적으로 데몬 스레드가 아니기 때문에 main 스레드가 종료되더라도 작업을 처리하기 위해 계속 실행 상태로 남아있다.
스레드풀의 모든 스레드를 종료하려면 ExecutorService의 다음 두 메서드 중 하나를 실행해야 한다.
리턴 타입
메서드명(매개변수)
설명
void
shutdown()
현재 처리 중인 작업뿐만 아니라 작업 큐에 대기하고 있는 모든 작업을 처리한 뒤에 스레드풀을 종료
List
shutdownNow()
현재 작업 처리 중인 스레드를 interrupt해서 작업을 중지시키고 스레드풀을 종료시킨다. 리턴값은 작업 큐에 있는 미처리된 작업(Runnable)의 목록이다.
작업 생성과 처리 요청
하나의 작업은 Runnable 또는 Callable 구현 클래스로 표현한다.
Runnable의 run() 메서드는 리턴값이 없고, Callable의 call() 에서드는 리턴값이 있다.
Runnable 익명 구현 클래스
Callable 익명 구현 클래스
new Runnable() { @Overrid public void run() { // 스레드가 처리할 작업 내용 } }
new Callable { @Overrid public T call() throws Exception { // 스레드가 처리할 작업 내용 return T; } }
call()의 리턴 타입은 Callable<T>에서 지정한 T타입 파라미터와 동일한 타입이여야 한다.
작업 처리 요청을 위해 ExecurotService는 다음 두 가지 메서드를 제공한다.
리턴 타입
메서드명(매개변수)
설명
void
execute(Runnable command)
- Runnable을 작업 큐에 저장 - 작업 처리 결과를 리턴하지 않음
Future
submit(Callable task)
- Callable을 작업 큐에 저장 - 작업 처리 결과를 얻을 수 있도록 Future를 리턴
![[Routine] 9 주차 시작!](/assets/img/daily/routine/2023/2023-03-19/2023-03-19-myroutine-9th.png)




![[Programming] 이것이 자바다](/assets/img/books/tech/2023/2023-03-16/thisisjava.png)
![[Routine] 8 주차 시작!](/assets/img/daily/routine/2023/2023-03-12/2023-03-12-myroutine-8th.png)








![[Routine] 7 주차 시작!](/assets/img/daily/routine/2023/2023-03-05/2023-03-05-myroutine-7th.png)




![[Network] OSI 7 Layer - Physical Layer](/assets/img/development/client/2023-03-02/osi_7_layer_physical_layer_cover.png)

![[Routine] 6 주차 시작!](/assets/img/daily/routine/2023/2023-02-26/2023-02-26-myroutine-6th.png)






![[마이그레이션] 내가 회사 프로젝트 마이그레이션을 vue2가 아닌 vue3로 선택한 이유](/assets/img/development/problem_solving/2023-02-23/reason_why_i_chose_vue3_cover.png)
 Options API를 Composition API로 리팩토링한 결과
Options API를 Composition API로 리팩토링한 결과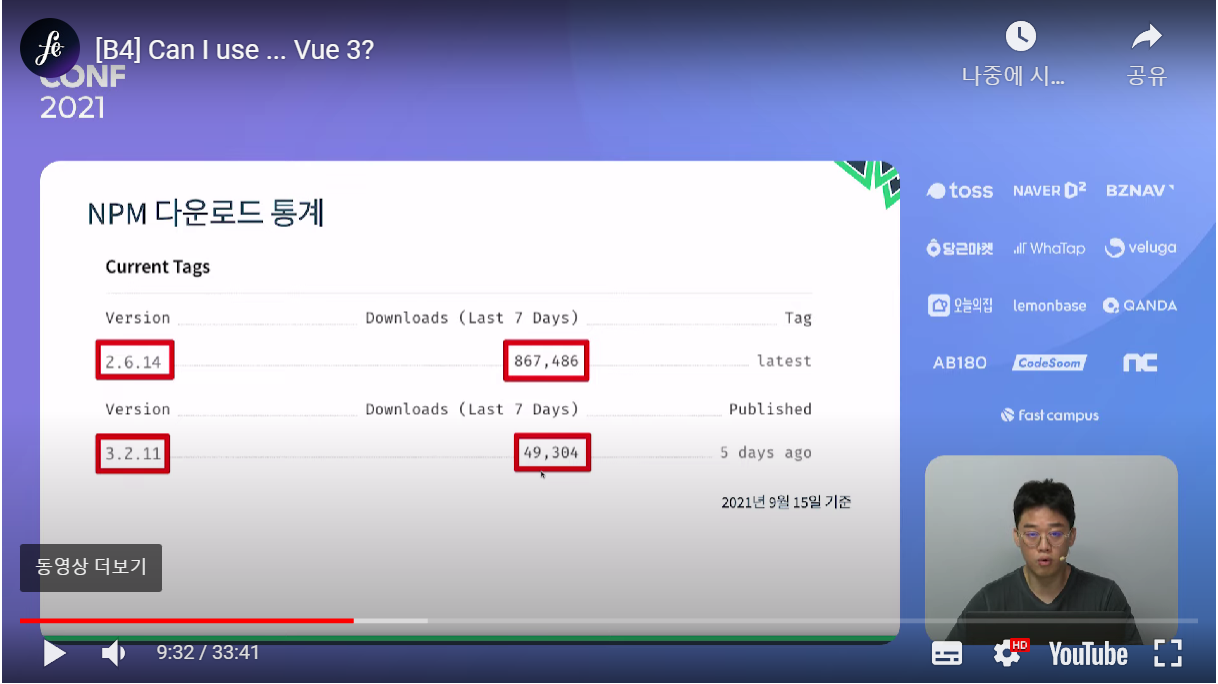 캡틴 판교 님의 vuejs 2.x vs 3.x 비교 영상 중 npm 다운로드 수
캡틴 판교 님의 vuejs 2.x vs 3.x 비교 영상 중 npm 다운로드 수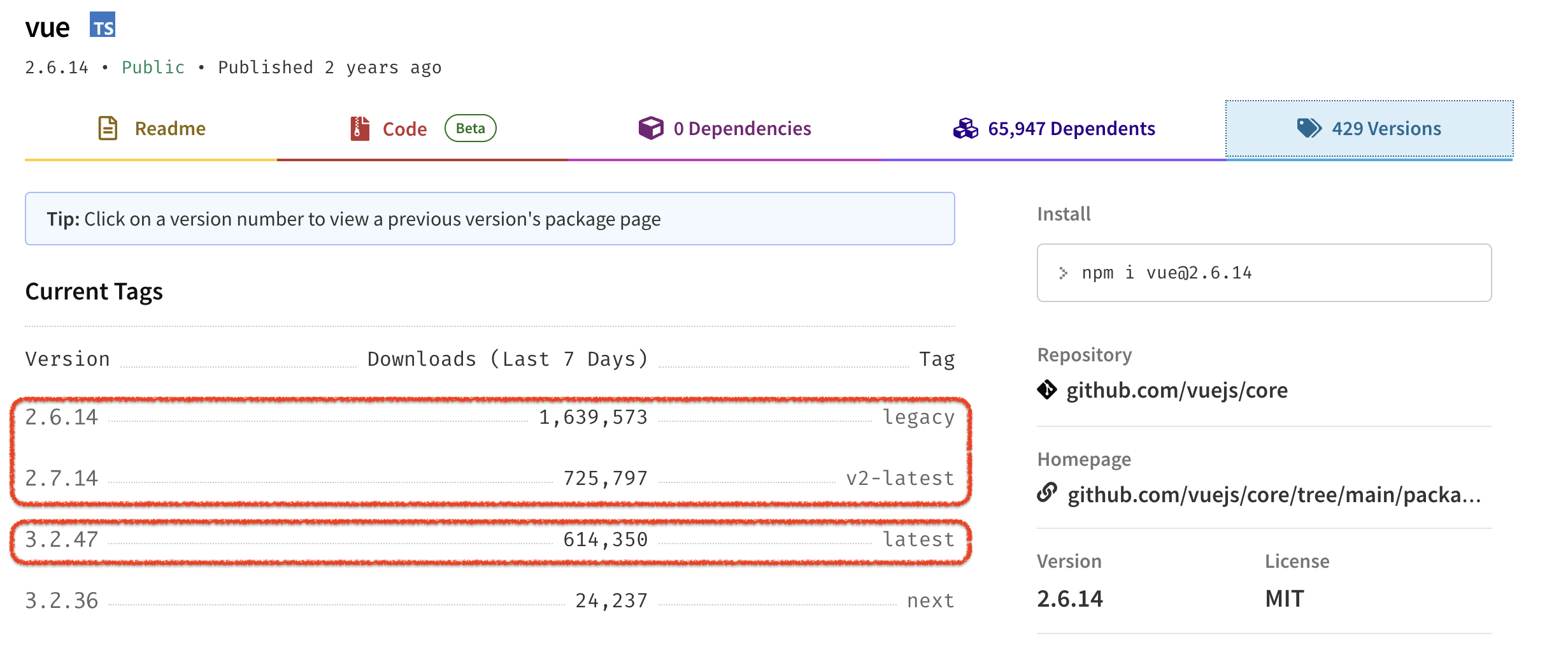 (2023년 4월 3일 기준)
(2023년 4월 3일 기준)![[Routine] 5 주차 시작!](/assets/img/daily/routine/2023/2023-02-19/2023-02-19-myroutine-5th.png)




![[Routine] 4 주차 시작!](/assets/img/daily/routine/2023/2023-02-12/2023-02-12-myroutine-4th.png)





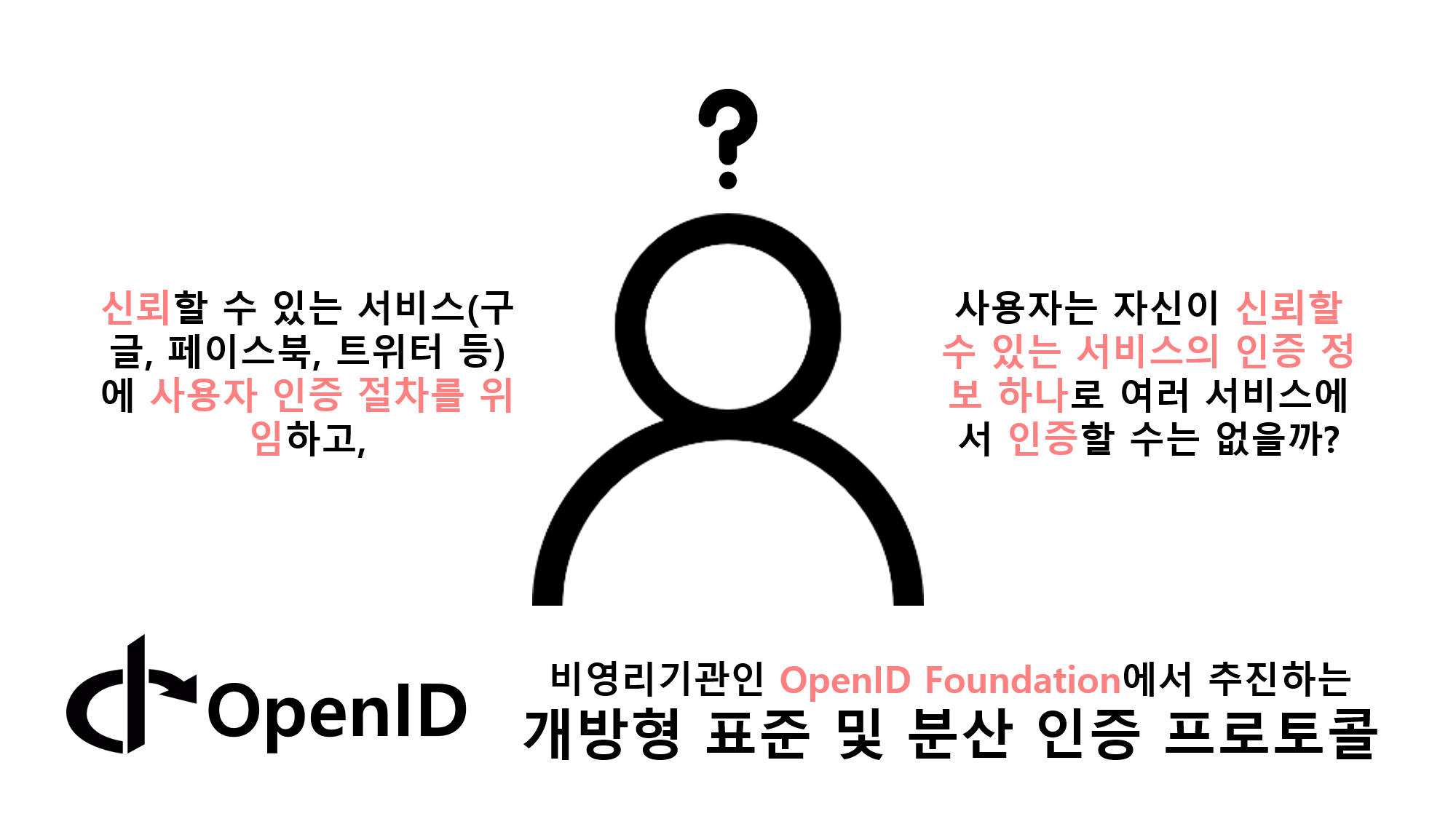
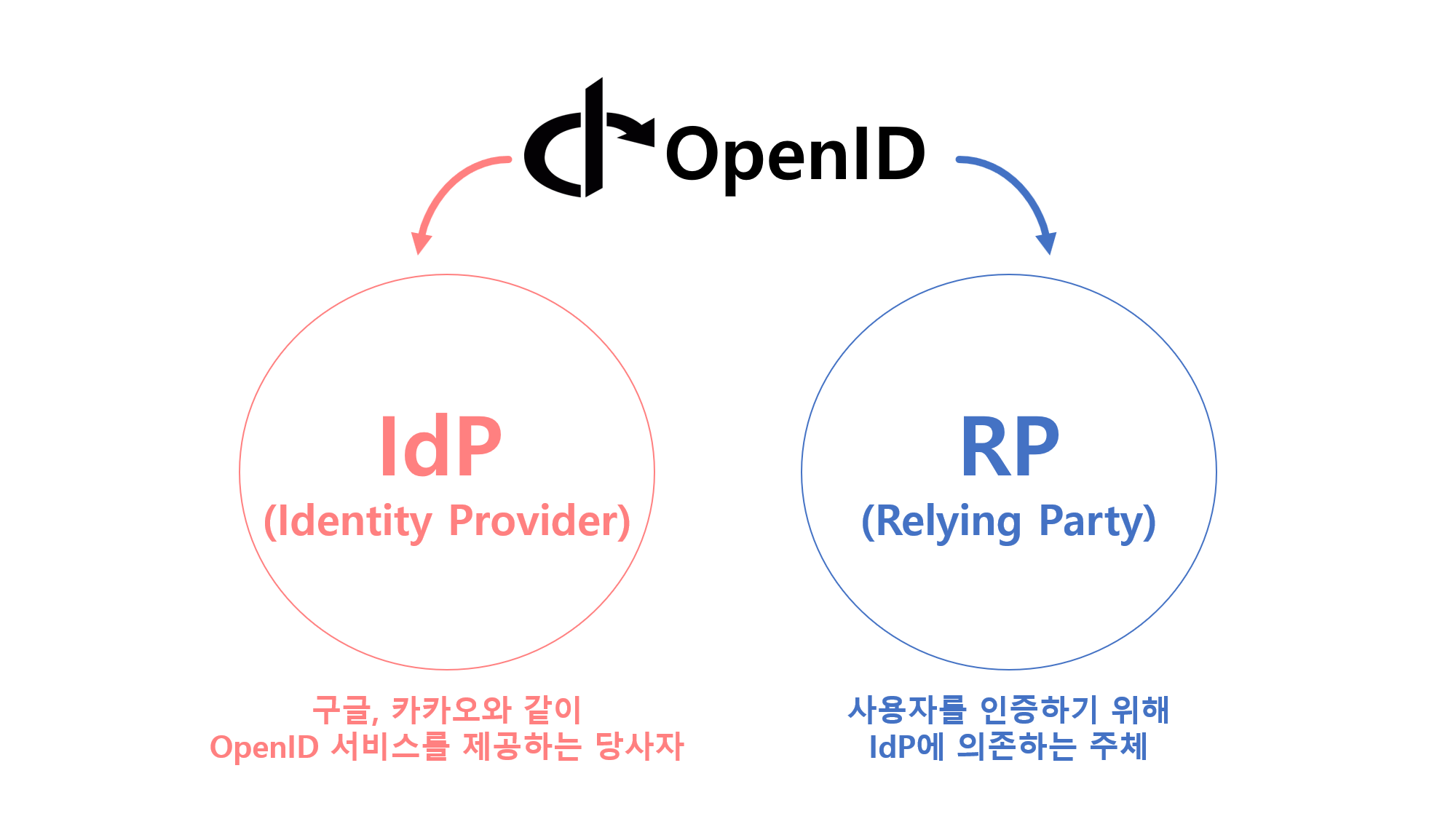
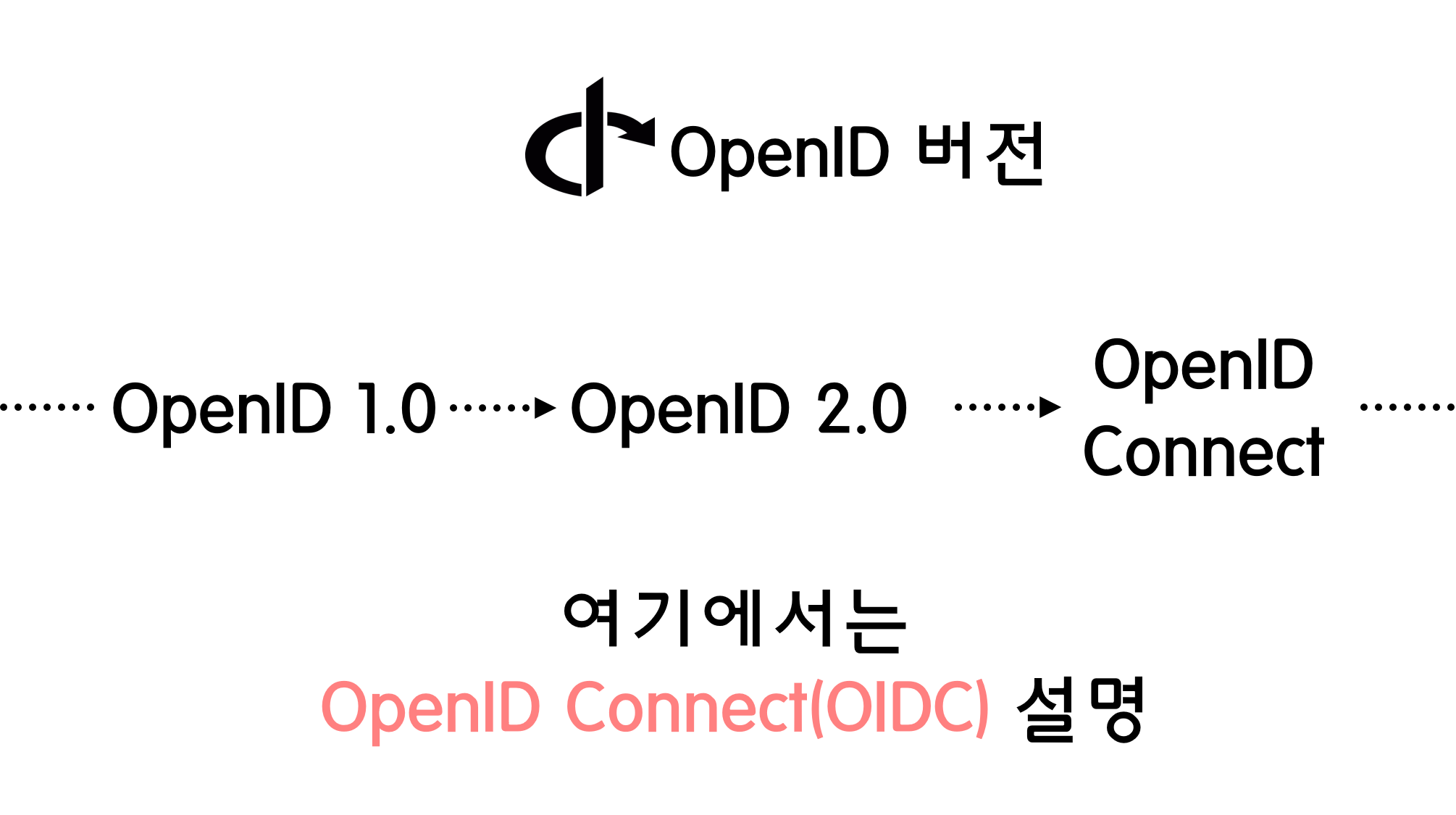
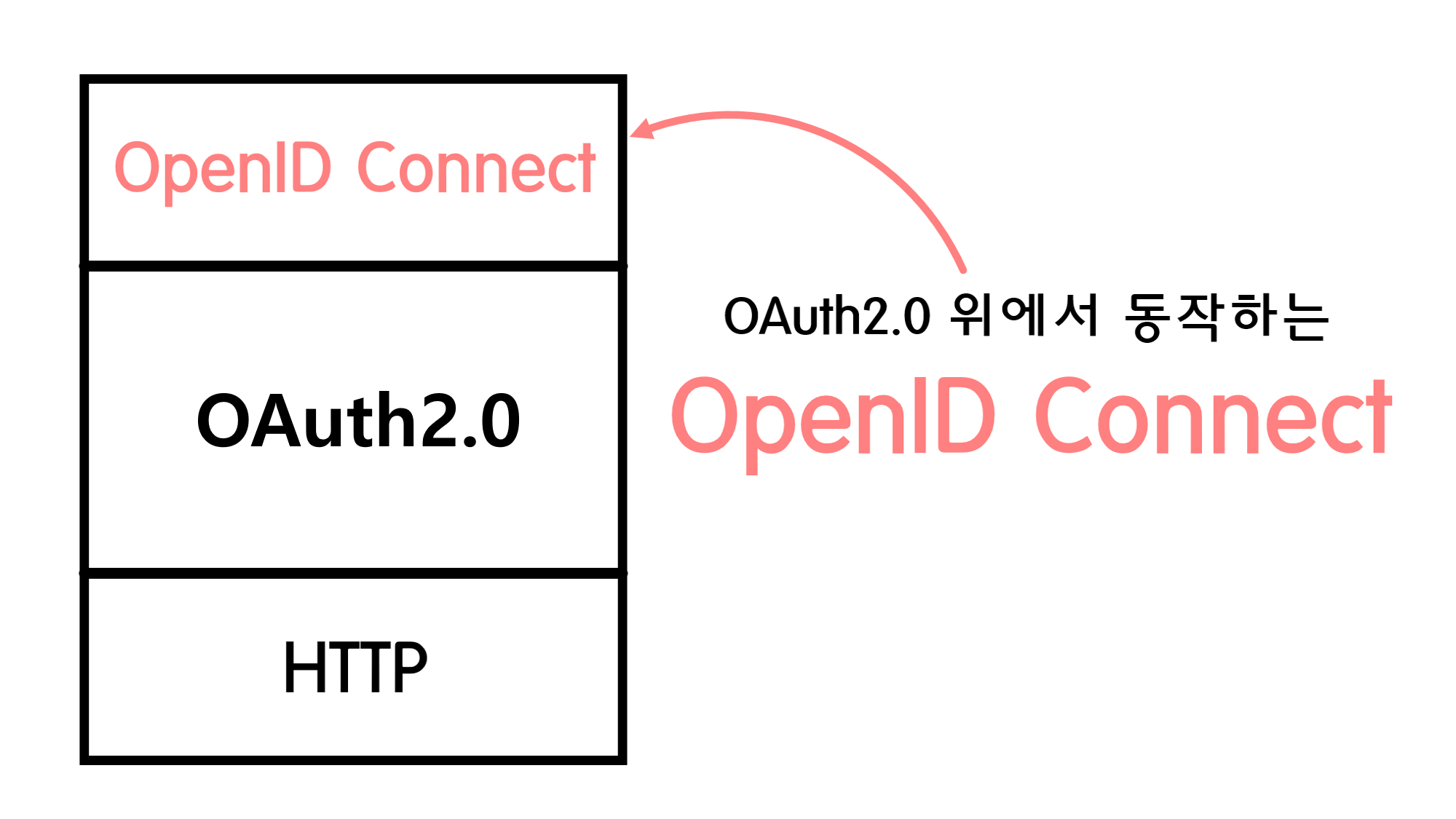
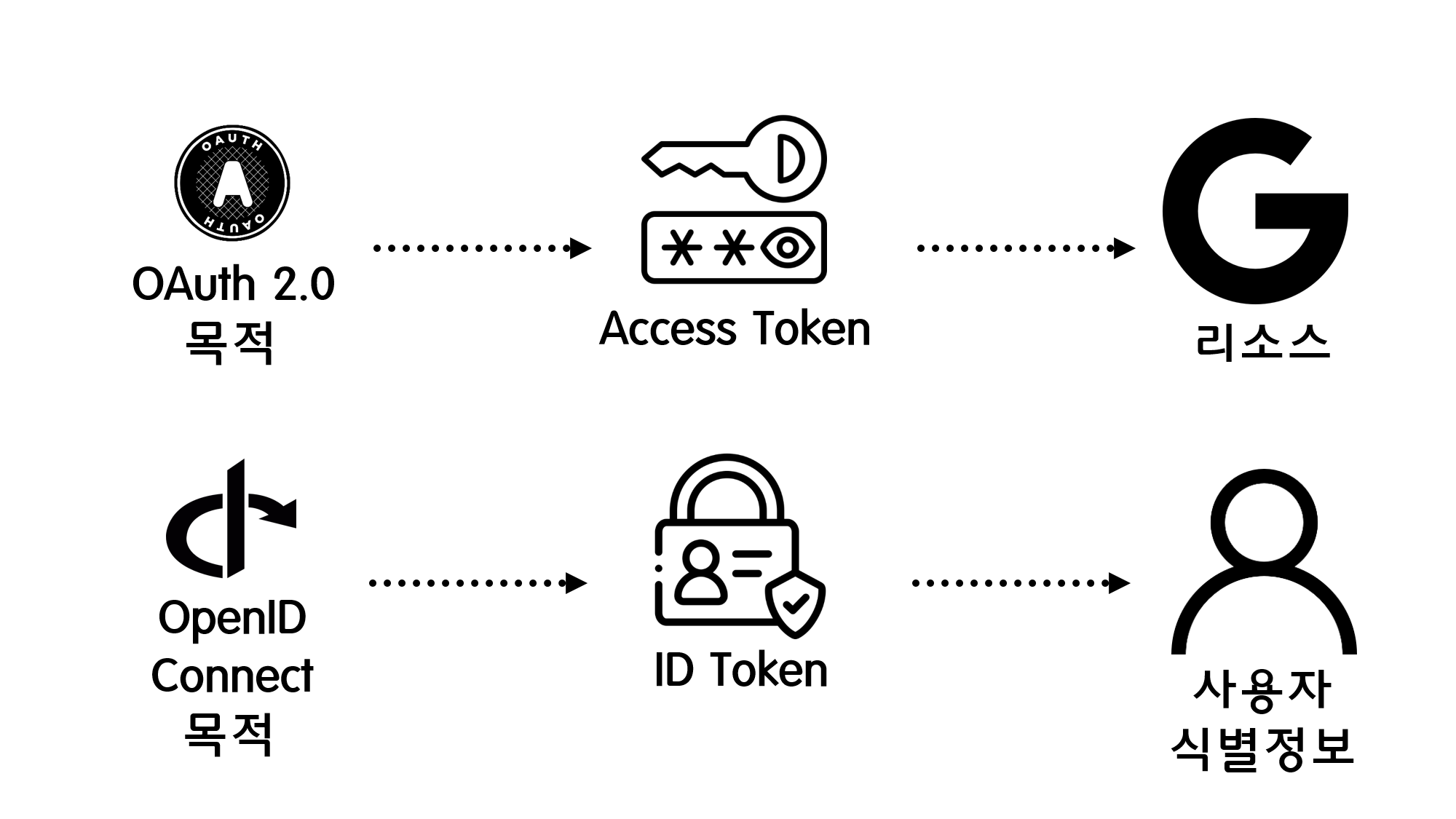
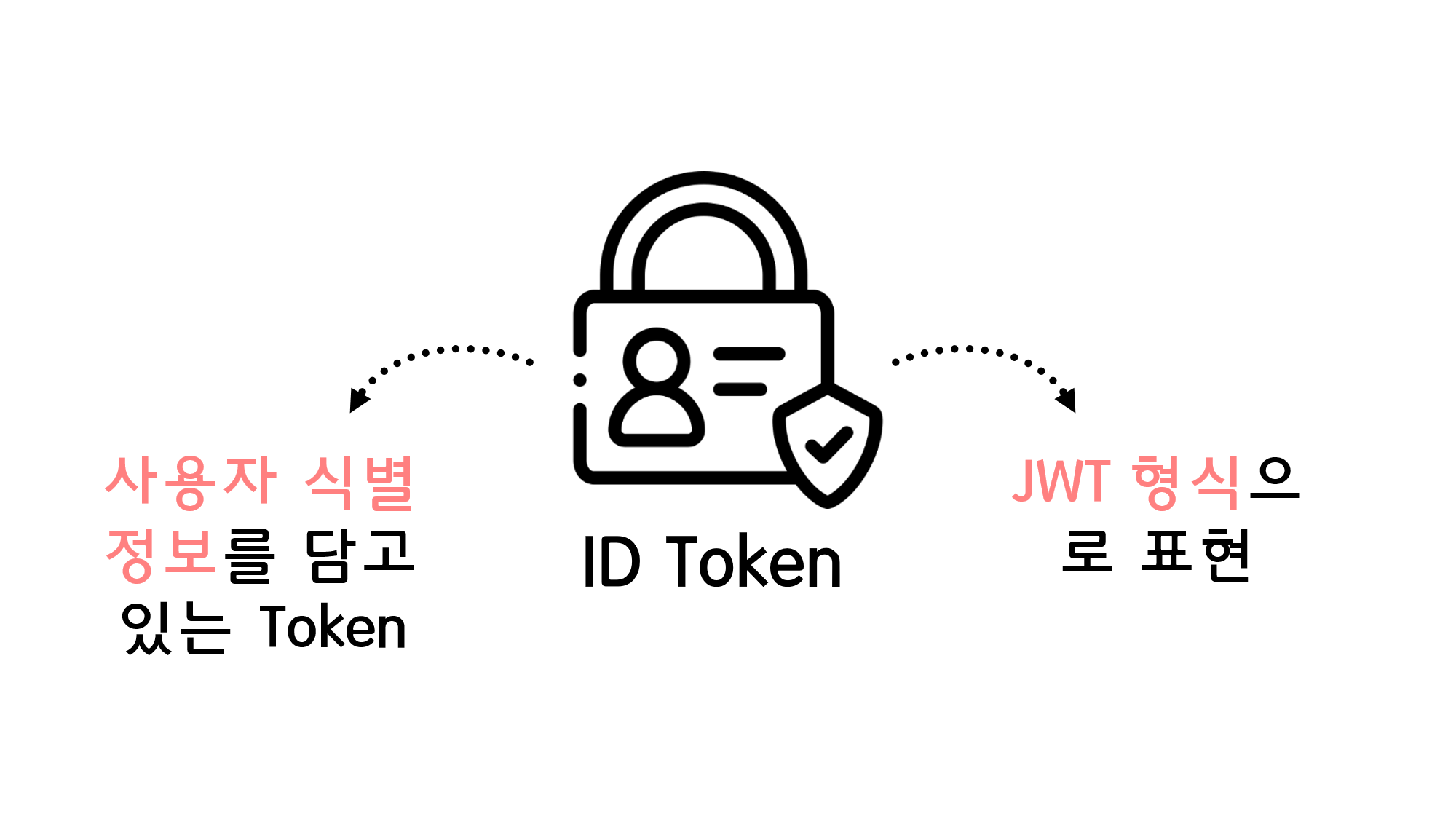
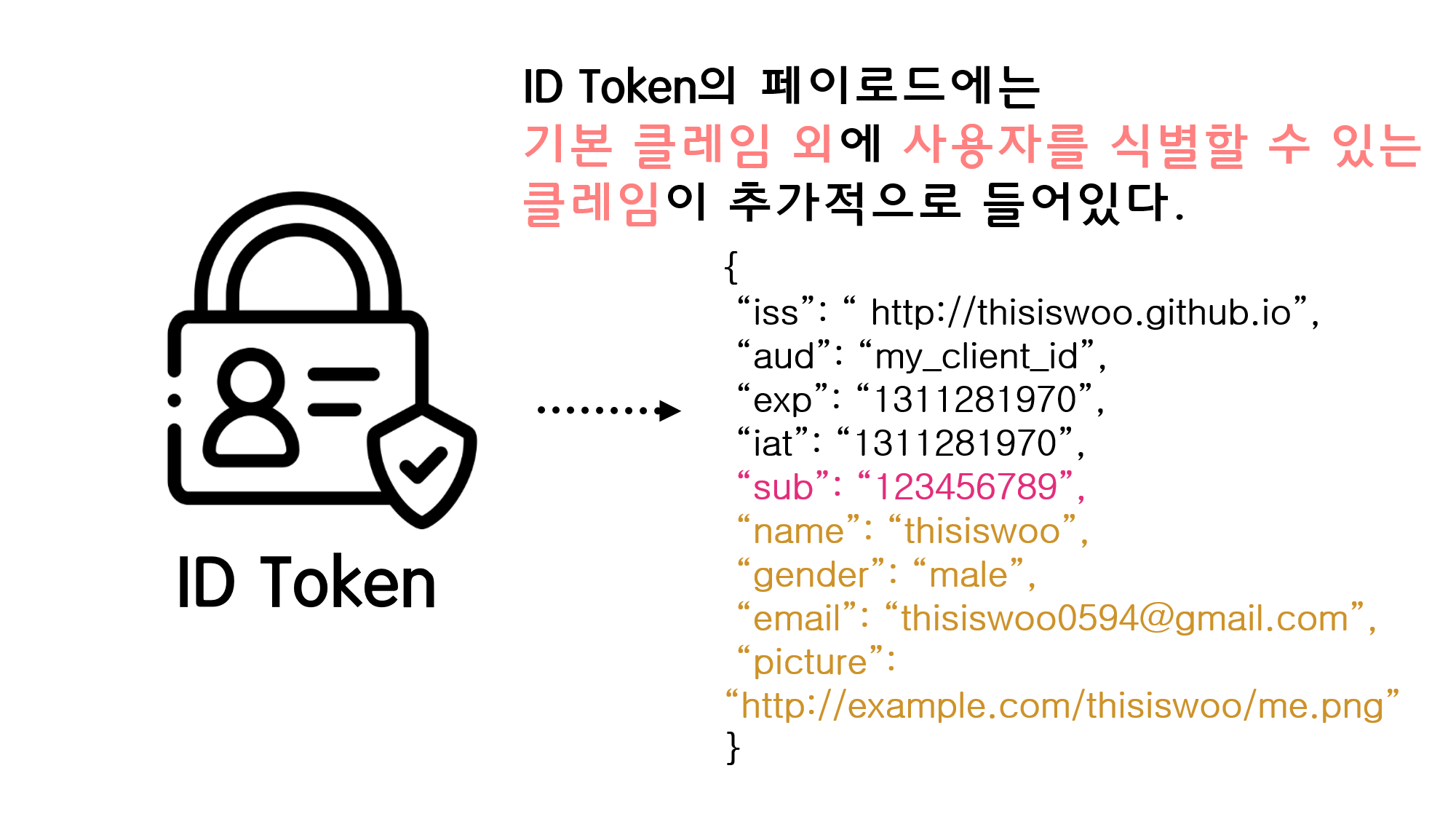
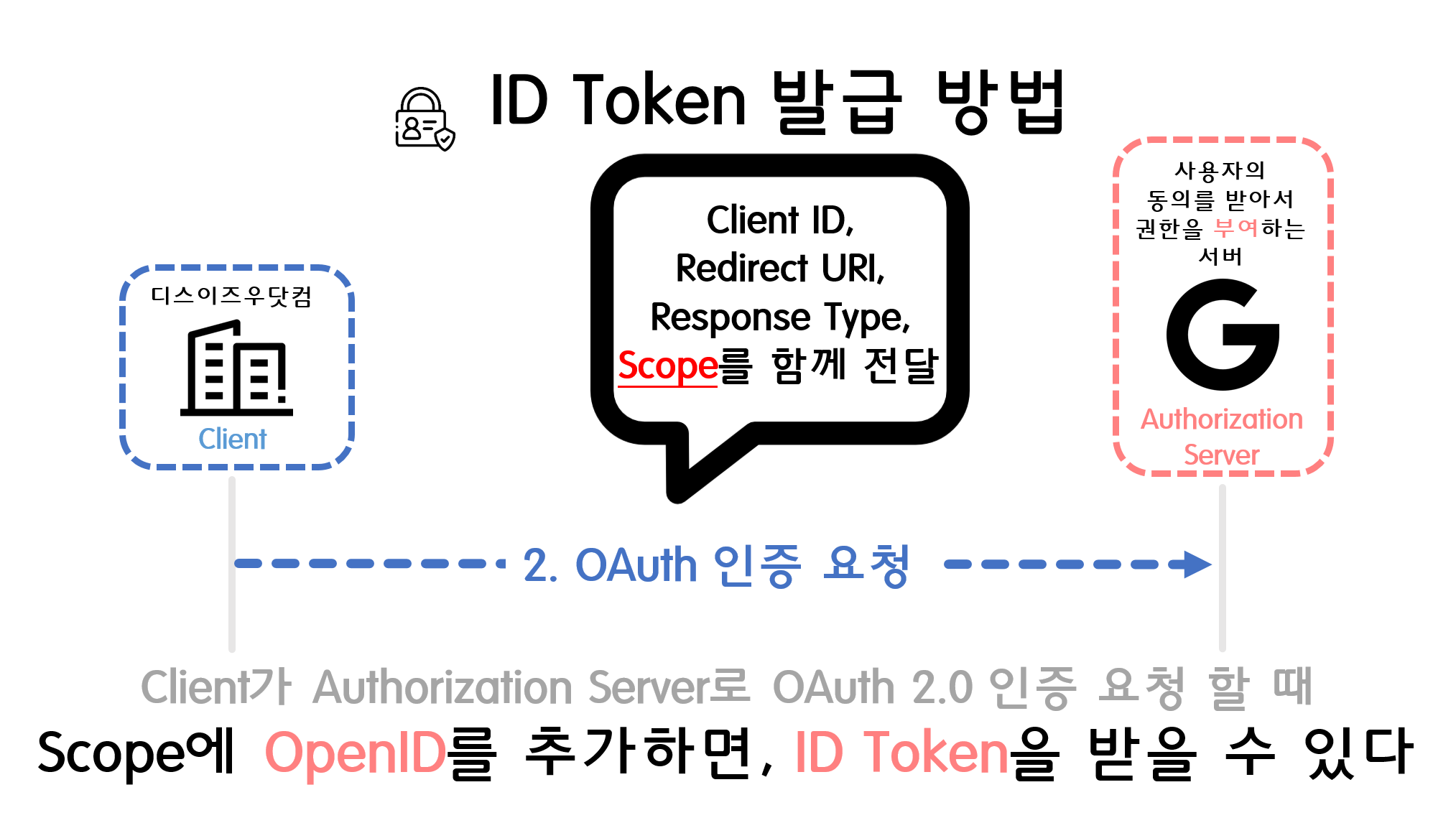
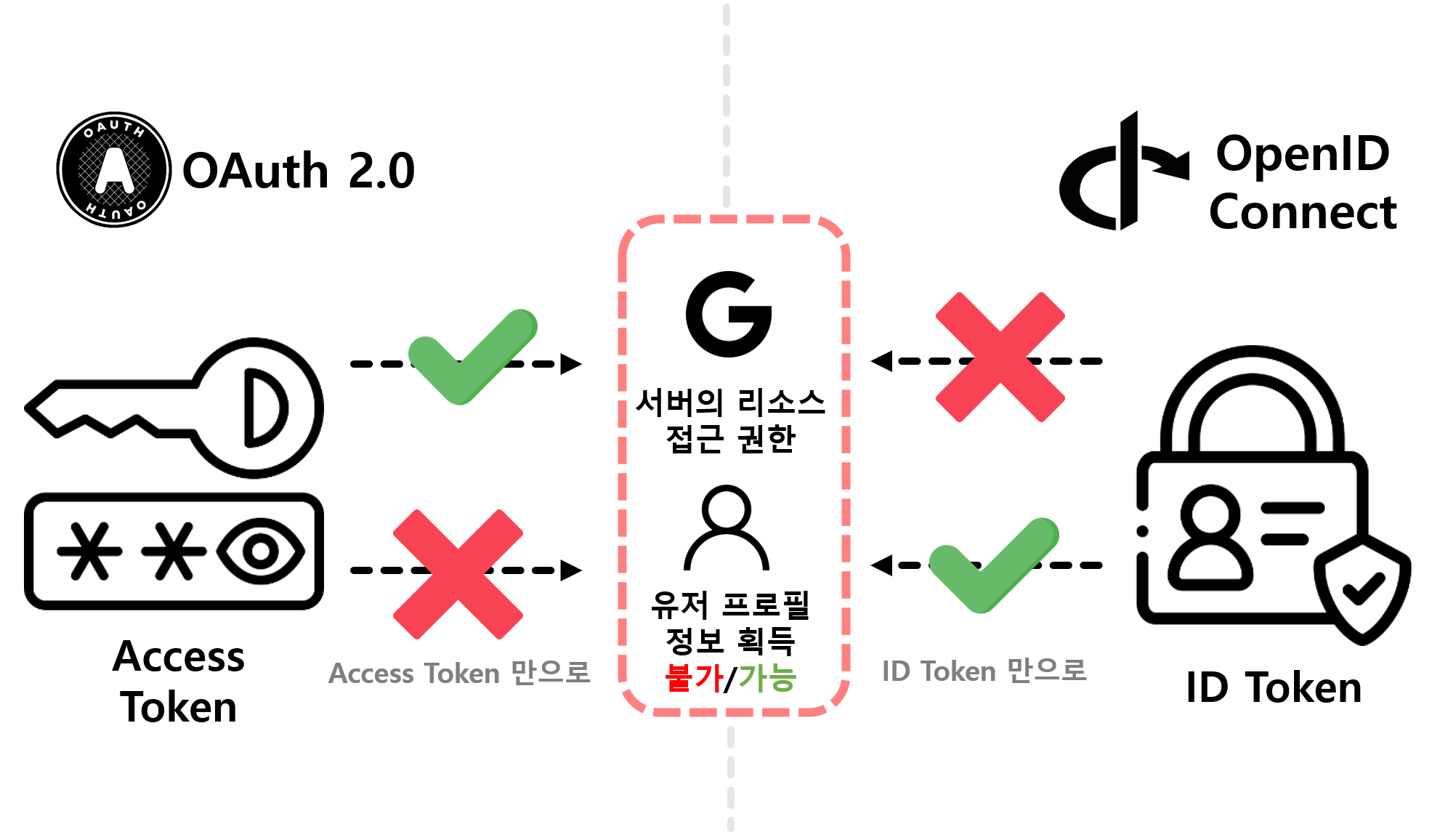
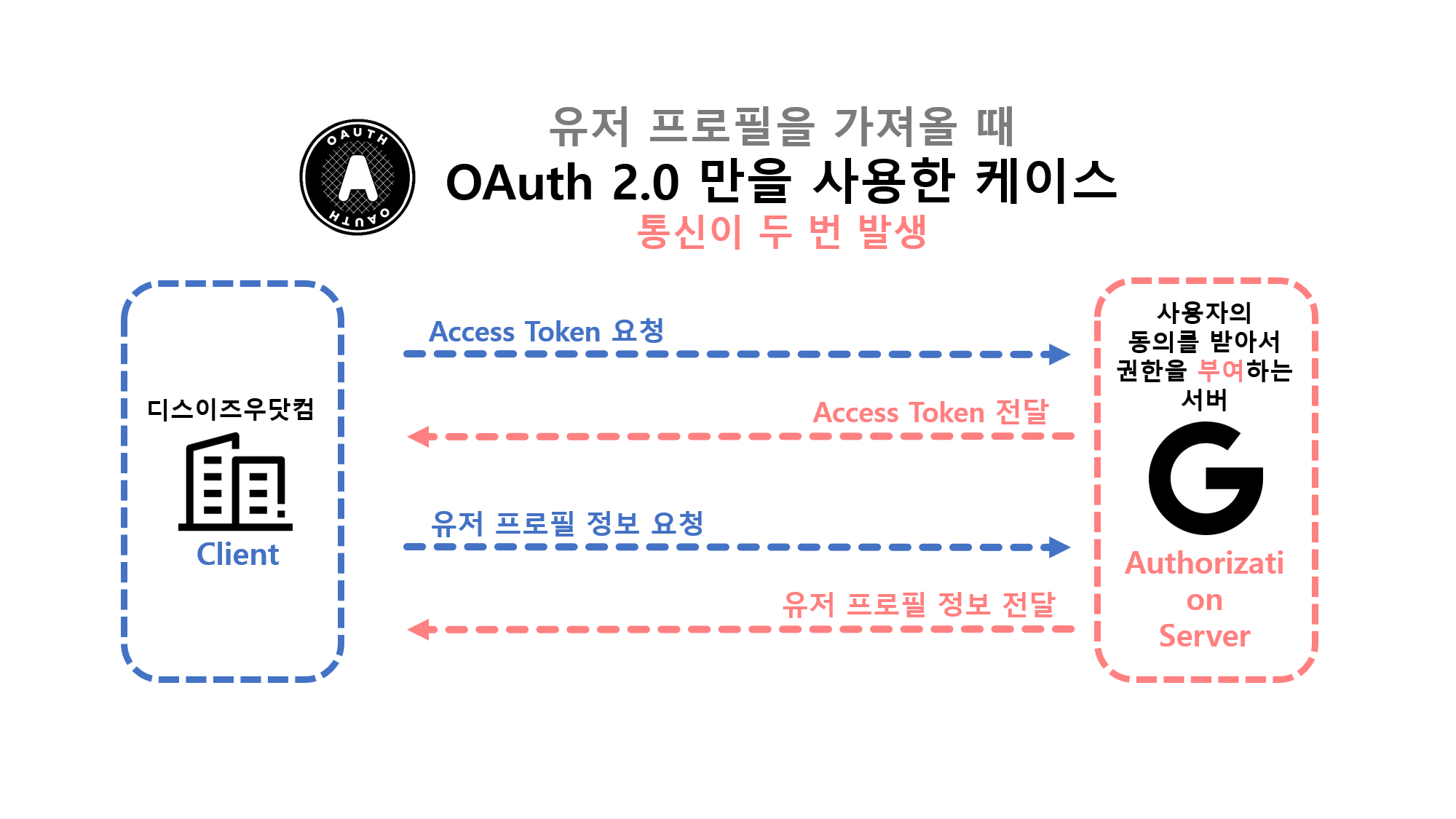
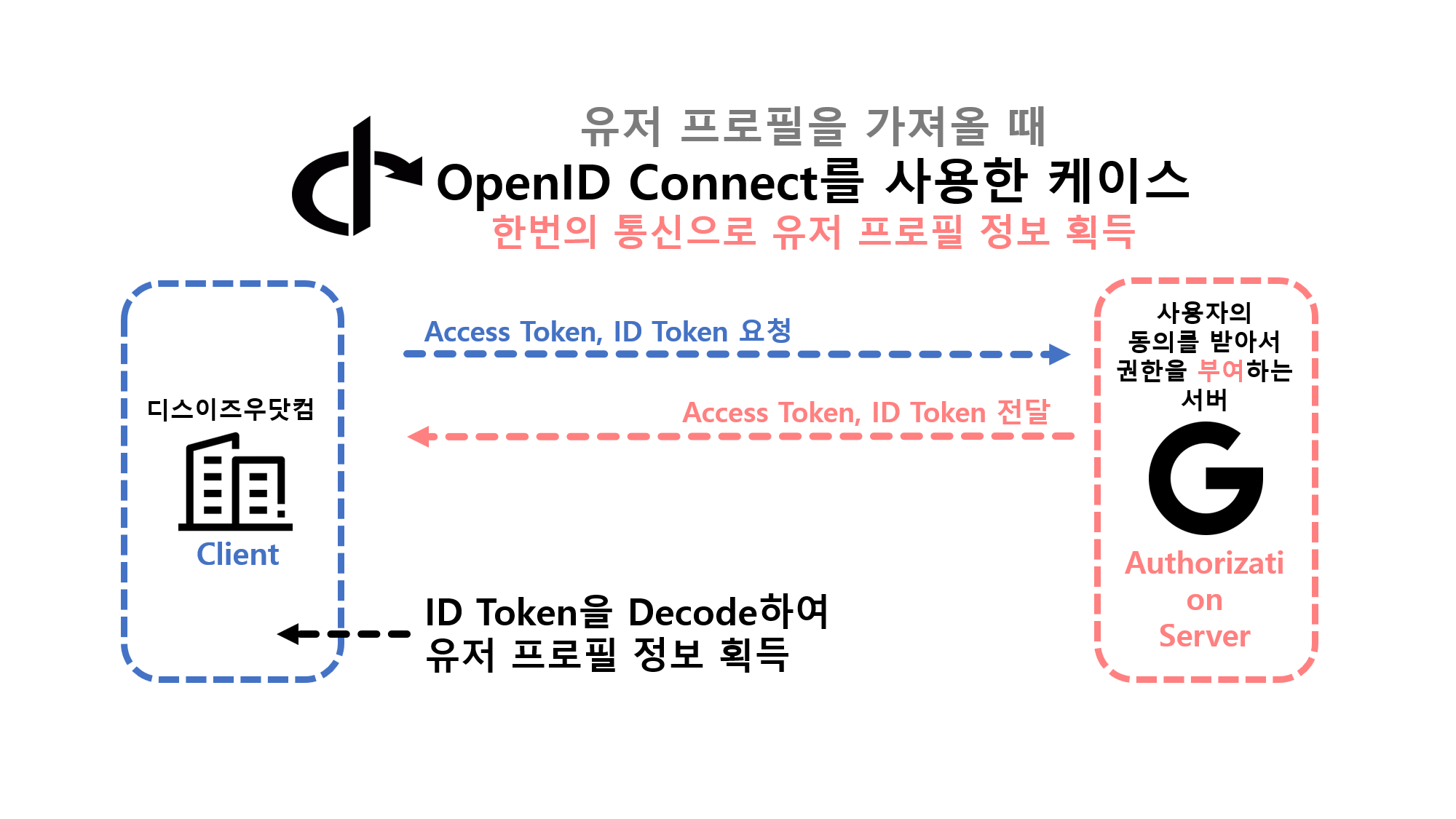
![[Security] OpenID Connect](/assets/img/development/server/2023-02-08/openid_cover.png)