사용자가 조회, 등록, 등 작업을 하려는 행위들을 했을 때 사용자에게 안내 팝업창과 저장했으면 저장, 취소했으면 취소하는 행동의 팝업창을 띄워주고 있는데, 그 코드들을 계속 새로 작성하여 중복코드가 상당히 발견되는 상황을 발견하였다.
문제의 재현 코드
// file: "문제의 javascript파일.js"functionprocessDone(jqXHR,textStatus,errorThrown){// ...if(jqXHR.status==500){Swal.fire({title:'알림',text:'내부 시스템 에러',icon:'error',confirmButtonText:'확인',}).then(function(result){if(result.value){alertify.error('내부 시스템 에러');}});}elseif(jqXHR.status==404){Swal.fire({title:'알림',text:'경로가 잘못 되었습니다.',icon:'error',confirmButtonText:'확인',}).then(function(result){if(result.value){alertify.error('경로가 잘못 되었습니다.');}});}elseif(jqXHR.status==408){Swal.fire({title:'알림',text:'잠시 후 다시 시도해 주세요.',icon:'error',confirmButtonText:'확인',}).then(function(result){if(result.value){alertify.error('잠시 후 다시 시도해 주세요.');}});}elseif(jqXHR.status==401){errorAlert('접근 권한이 없습니다.');}elseif(jqXHR.status==403){Swal.fire({title:'알림',text:'ID 또는 비밀번호를 확인해주세요.',icon:'error',confirmButtonText:'확인',}).then(function(result){if(result.value){alertify.error('ID 또는 비밀번호를 확인해주세요.');}});}if(jqXHR.getResponseHeader("SESSION_EXPIRED")!=null){Swal.fire({title:'알림',text:'세션이 만료되어 로그인 페이지로 이동합니다.',icon:'error',confirmButtonText:'확인',}).then(function(result){if(result.value){location.href="/login";}});}}
문제의 재현 코드
위 코드를 보게 되면 api 호출 후 응답 결과에 따른 안내 팝업창을 나타내는 코드이다.
위 조건문 안에 Bootstrap의 팝업 기능인 Swal.fire() 부분의 코드들이 중복적으로 계속 발생한다는 것을 알 수 있다.
위 코드처럼 사용하게 되면 만약, 기능들이 추가되거나 사용자에게 팝업 형태의 알림을 보여줘야 할 때 계속 비슷한 코드를 사용해야 한다는 문제가 발생한다.
그것을 방지하고 함수로 정의하여 호출하는 형태로 바꾸어 아래 코드처럼 리팩토링하였다.
리팩토링 재현 코드
// file: "sg.ajax.js"functionprocessFail(jqXHR,textStatus,errorThrown){// ...if(jqXHR.stat표us==500){notification('내부 시스템 에러','error',null);}elseif(jqXHR.status==404){notification('경로가 잘못 되었습니다.','error',null);}elseif(jqXHR.status==408){notification('잠시 후 다시 시도해 주세요.','error',null);}elseif(jqXHR.status==401){notification('접근 권한이 없습니다.','error',null);}elseif(jqXHR.status==403){notification('ID 또는 비밀번호를 확인해주세요.','error',null);}// ...if(jqXHR.getResponseHeader("SESSION_EXPIRED")!=null){notification('세션이 만료되어 로그인 페이지로 이동합니다.','error',()=>{location.href="/login";});}// ...}
리팩토링한 재현 코드
위 코드처럼 리팩토링하여 약 71%의 코드 사용량을 줄였다.
물론 코드가 예제 파일 파일 한 곳에 결과를 반영한 것으로 실제와 다를 순 있다.
하지만, 확실한 건 코드의 사용량이 예제 코드를 통해서만 보아도 많이 줄일 수 있다는 것을 볼 수 있다.
리팩토링 공통 함수 재현 코드
// file: "리팩토링.js"/**
* Notification (success/error/warning/question/info alert)
*
* @param text 팝업 문구
* @param type 팝업 종류 : success, error, warning, info
* @param method 실행 메서드
* @returns Swal.fire
*/functionnotification(text,type,method){// When text and type are not usedif(text===null||type===null){returnSwal.fire({title:'알림',text:'시스템 오류가 발생했습니다. 관리자에게 문의해주세요.',icon:'warning',confirmButtonText:'확인',});}// Common AlertreturnSwal.fire({title:'알림',// 알림text:text,icon:type,showCancelButton:type==='question'?true:false,confirmButtonText:'확인',cancelButtonText:'취소',}).then((result)=>{if(result.isConfirmed){method();}elseif(result.isDismissed){notification('취소 하였습니다.','warning',null);}});}
공통 팝업 함수 재현 코드
위 파라미터 text의 경우 공통 팝업 창의 안내 문구를 넣어주는 파라미터이다.
type은 팝업창의 아이콘 타입으로 error, warning, success을 통해 공통 팝업창의 아이콘을 설정할 수 있게 된다.
method의 경우 공통 팝업 창의 실행 후 추가적인 작업이 이 필요할 때 함수를 넣어주는 파라미터이다.
따라서, 위 공통 함수 코드로 리팩토링하여 사용자에게 필요한 팝업창을 제공하고 싶을 때 호출하여 사용하면 된다.
매번 사용자에게 팝업 알림 창을 보여줘야 하는 코드를 만들어서 보여주는 것보다 그곳에서 해당 공통 함수를 호출하여 제공하면 코드 사용량이 줄어들어 유지 보수에도 편하게 된다.
결론
리팩토링을 통해 코드가 훨씬 간결해졌다.
또한 유지 보수가 편리해졌다는 것을 알 수 있다.
이렇게 리팩토링을 진행하면서 리팩토링의 재미를 느끼게 되었다. 위 코드 또한 좀 더 리팩토링해볼 수 있지 않을까? 란 생각을 잠시나마 해본다.
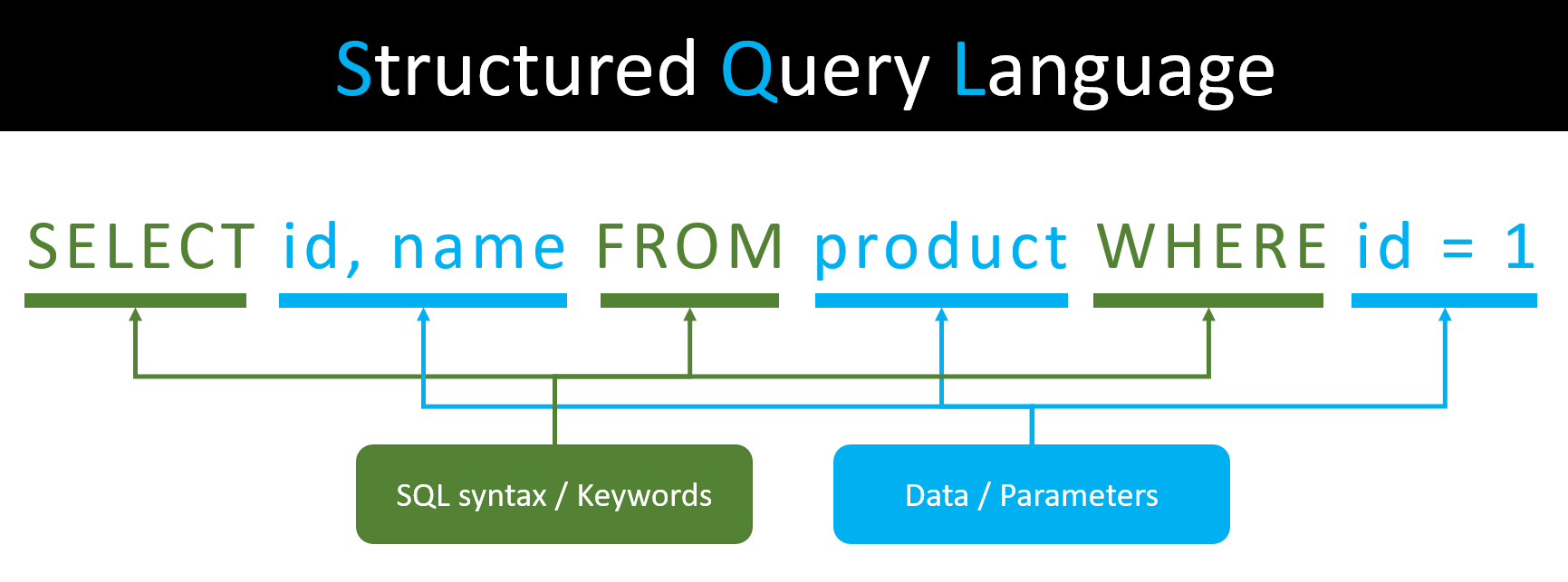
SQL 데이터베이스 구조의 데이터는 열(row)과 행(column)으로 구성된 테이블로 구성되어 있다.
SQL 데이터베이스는 수직적 구조로 새로운 데이터가 추가될 때마다 수직적으로 쌓이게 된다.
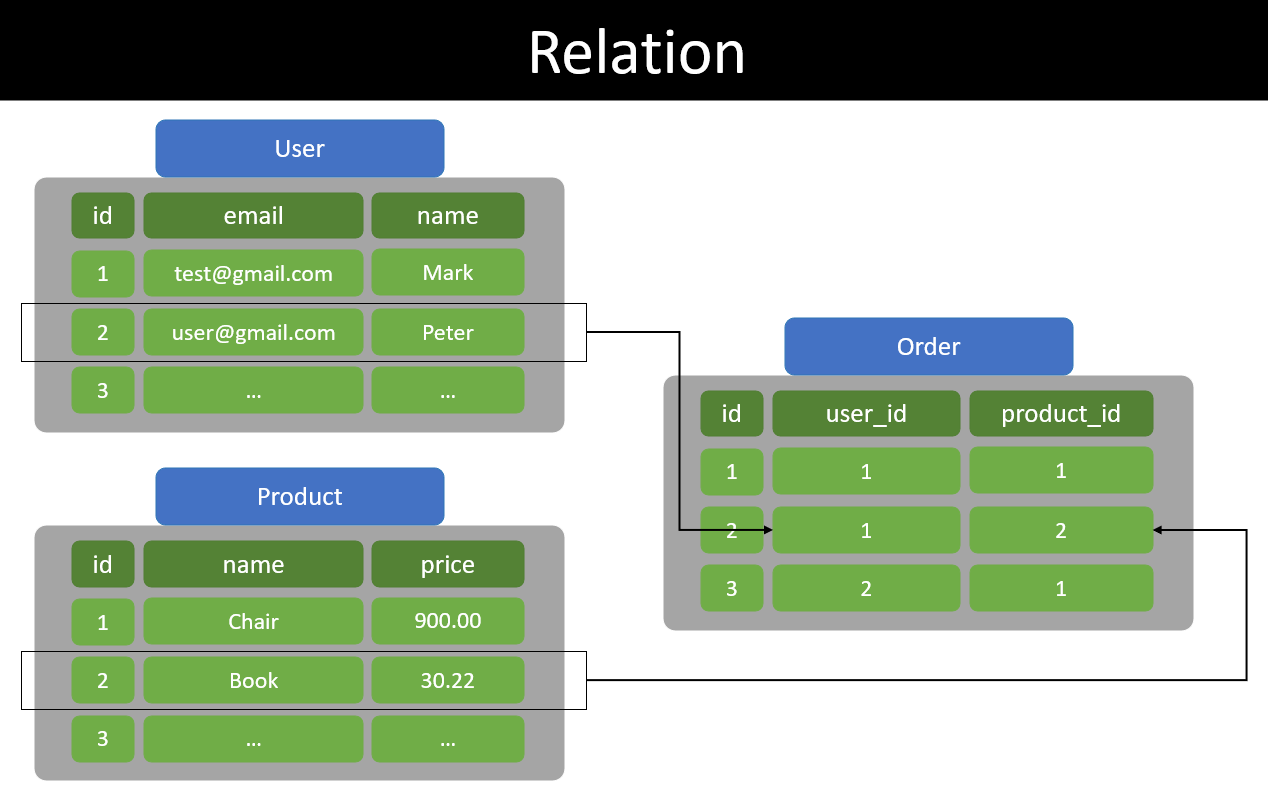
관계형 데이터베이스(Relational database)
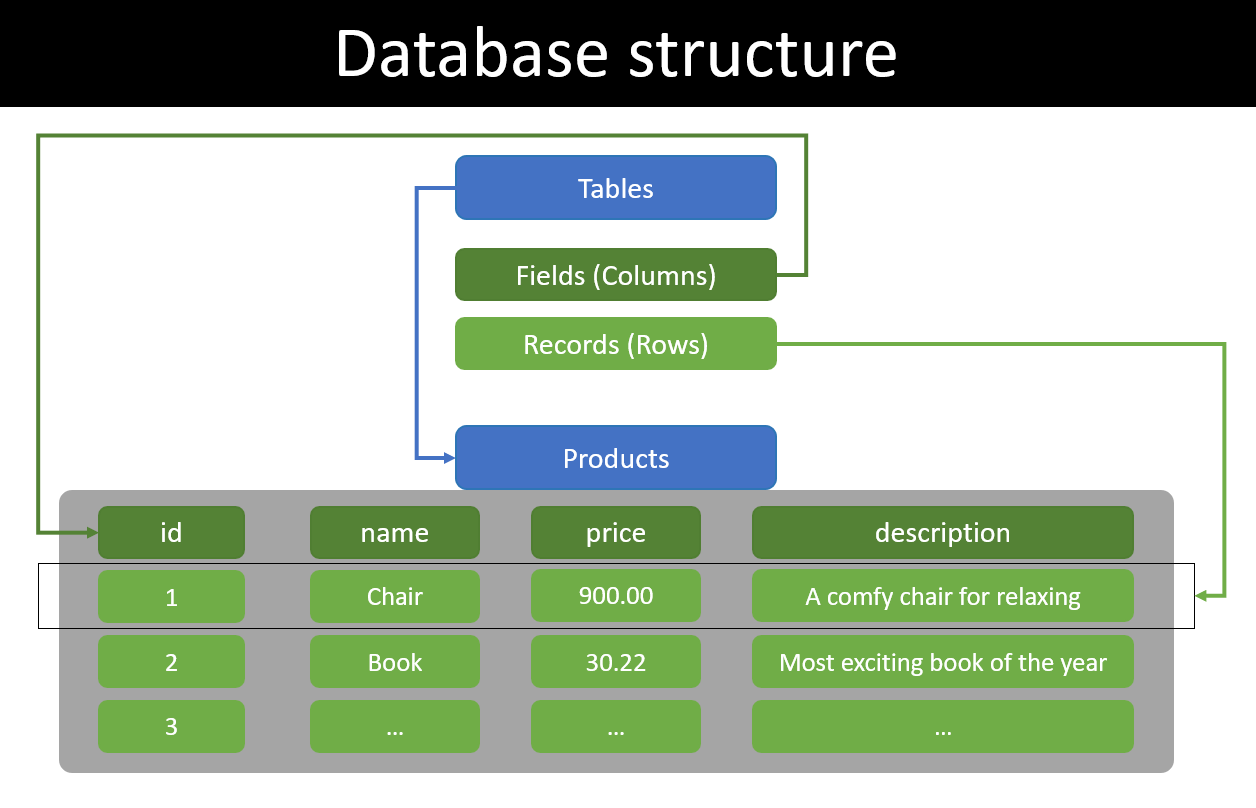
DB Structure
관계형 DB(RDBMS)는 데이터베이스에 저장된 데이터의 구조, 즉 데이터 스키마를 명확하게 정의하는 것 또한 매우 중요하다.
테이블의 모든 레코드(column - fields)는 정의된 열(row)을 준수해야 하며, 해당 형식(테이블/행/열)에서만 데이터 조작을 수행할 수 있다.
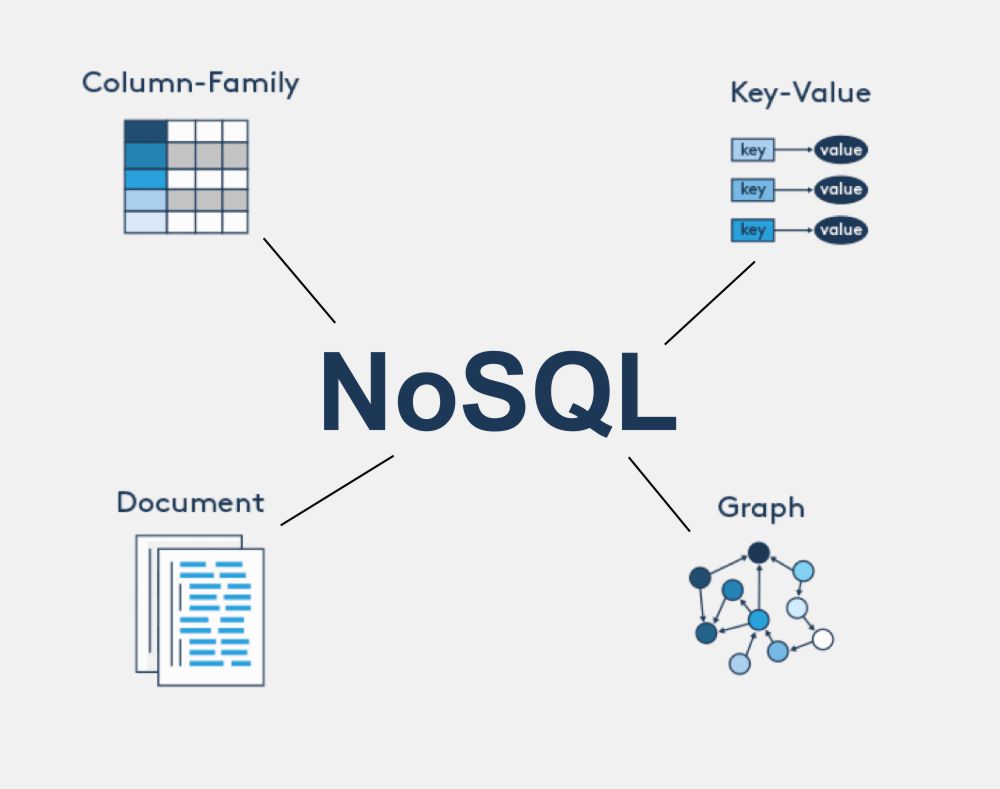
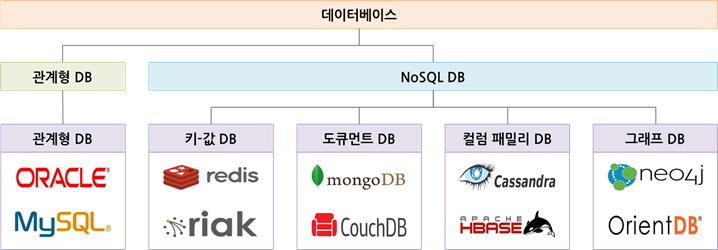
NoSQL(Non SQL) 이란?
NoSQL
NoSQL은 고정 스키마가 필요하지 않고 쉽게 확장되며 조인을 수행할 수 없는 비관계형 데이터베이스이다.
방대한 데이터 스토리지가 필요한 분산 데이터 저장소에 적합하여 빅데이터와 실시간 웹 앱에 많이 사용된다.
NoSQL 데이터베이스는 관계형 스키마에 데이터를 저장하지 않기 때문에 전체 테이블의 구조를 변경하거나 나머지 행에 중복 요소를 추가하지 않고도 즉시 데이터 속성을 추가할 수 있다.
NoSQL 데이터베이스는 수평적 확장이 뛰어나고 파티션 허용 오차가 기반에 내장되어 있어 많은 양의 데이터에 대해 1초 미만의 응답 시간이 필요한 시나리오에서 잘 작동한다.
NoSQL의 종류
NoSQL
NoSQL 데이터베이스는 수평적 구조로 새로운 데이터가 추가될 때마다 수평적으로 쌓이게 된다.
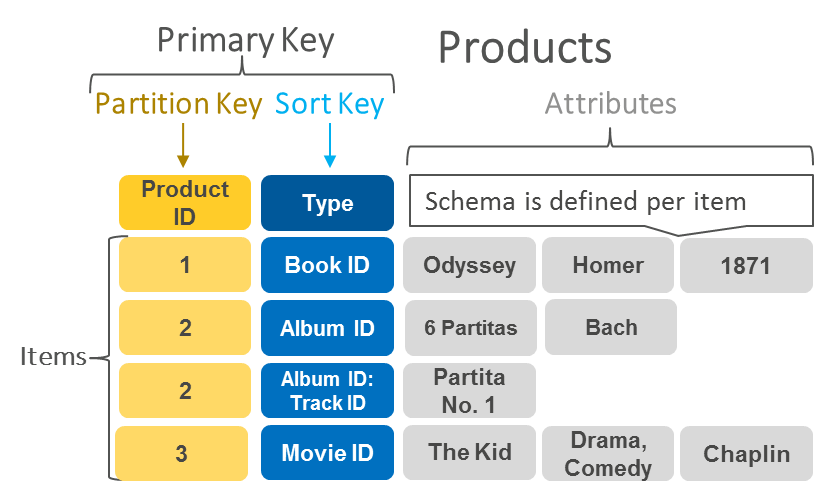
Document Databases
[{"title":"The Thieves","year":2012,"info":{"directors":["Choi Dong-hoon"],"release_date":"2012-07-25T00:00:00Z","rating":8,"genres":["Action","Drama"],"image_url":"https://en.wikipedia.org/wiki/The_Thieves#/media/File:The_Thieves.jpg","plot":"Ten Thieves. Only One Diamond. They began to Move.","actors":["Kim Yoon-seok","Kim Hye-soo","Lee Jung-jae","Jun Ji-hyun","Simon Yam","Kim Hae-sook","Oh Dal-su","Kim Soo-hyun","Derek Tsang","Angelica Lee","Shin Ha-kyun"]}},{"title":"The Age of Shadows","year":2016,"info":{"plot":"Enemy or Comrade","rating":43}}]
Document DB는 데이터를 JSON 형식의 문서로 데이터를 저장 및 쿼리하도록 설계된 비관계형 데이터베이스이다.
Document DB를 사용하면 개발자들이 자신의 애플리케이션 코드에서 사용하는 것과 동일한 문서 모델 형식을 사용하여 데이터베이스에서 보다 손쉽게 데이터를 저장하고 쿼리 작업을 할 수 있다.
Document DB는 문서 및 문서 데이터베이스의 유연하고 반구조화된 계층적 특성을 통해 개발자는 계속해서 애플리케이션의 요구를 발전시킬 수 있다.
Document DB는 유연한 인덱싱, 강력한 임시 쿼리, 문서 모음에 대한 분석을 지원한다.
Document DB는 MongoDB, CouchDB, MarkLogic 등이 있다.
// mongo DB Query 사용예db.movies.insert({"title":"The Thieves","year":2012,"info":{"directors":["Choi Dong-hoon"],// ...},},// ...)
Key-Value-Based Databases
Key-Value-Based DB
Key-Value DB는 키-값 메소드를 사용하여 데이터를 저장하는 비관계형 데이터베이스 유형이다.
Key-Value DB는 key를 고유한 식별자로 사용하는 키-값 쌍의 집합으로 데이터를 저장한다.
Key-Value DB는 단순한 객체에서 복잡한 집합체에 이르기까지 무엇이든 키와 값이 될 수 있으며 파티셔닝이 가능하고 다른 유형의 데이터베이스로는 불가능한 범위까지 수평 확장을 가능하게 한다.
Key-Value 기반 DB는 Redis, Memcache 등이 있다.
DynamoDB의 JAVA API를 활용한 key-value 데이터 CRUD 예제
/**
* Copyright 2010-2019 Amazon.com, Inc. or its affiliates. All Rights Reserved.
*
* This file is licensed under the Apache License, Version 2.0 (the "License").
* You may not use this file except in compliance with the License. A copy of
* the License is located at
*
* http://aws.amazon.com/apache2.0/
*
* This file is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
* CONDITIONS OF ANY KIND, either express or implied. See the License for the
* specific language governing permissions and limitations under the License.
*/packagecom.amazonaws.codesamples.document;importjava.io.IOException;importjava.util.Arrays;importjava.util.HashMap;importjava.util.HashSet;importjava.util.Map;importcom.amazonaws.services.dynamodbv2.AmazonDynamoDB;importcom.amazonaws.services.dynamodbv2.AmazonDynamoDBClientBuilder;importcom.amazonaws.services.dynamodbv2.document.DeleteItemOutcome;importcom.amazonaws.services.dynamodbv2.document.DynamoDB;importcom.amazonaws.services.dynamodbv2.document.Item;importcom.amazonaws.services.dynamodbv2.document.Table;importcom.amazonaws.services.dynamodbv2.document.UpdateItemOutcome;importcom.amazonaws.services.dynamodbv2.document.spec.DeleteItemSpec;importcom.amazonaws.services.dynamodbv2.document.spec.UpdateItemSpec;importcom.amazonaws.services.dynamodbv2.document.utils.NameMap;importcom.amazonaws.services.dynamodbv2.document.utils.ValueMap;importcom.amazonaws.services.dynamodbv2.model.ReturnValue;publicclassDocumentAPIItemCRUDExample{staticAmazonDynamoDBclient=AmazonDynamoDBClientBuilder.standard().build();staticDynamoDBdynamoDB=newDynamoDB(client);staticStringtableName="ProductCatalog";publicstaticvoidmain(String[]args)throwsIOException{createItems();retrieveItem();// Perform various updates.updateMultipleAttributes();updateAddNewAttribute();updateExistingAttributeConditionally();// Delete the item.deleteItem();}privatestaticvoidcreateItems(){Tabletable=dynamoDB.getTable(tableName);try{Itemitem=newItem().withPrimaryKey("Id",120).withString("Title","Book 120 Title").withString("ISBN","120-1111111111").withStringSet("Authors",newHashSet<String>(Arrays.asList("Author12","Author22"))).withNumber("Price",20).withString("Dimensions","8.5x11.0x.75").withNumber("PageCount",500).withBoolean("InPublication",false).withString("ProductCategory","Book");table.putItem(item);item=newItem().withPrimaryKey("Id",121).withString("Title","Book 121 Title").withString("ISBN","121-1111111111").withStringSet("Authors",newHashSet<String>(Arrays.asList("Author21","Author 22"))).withNumber("Price",20).withString("Dimensions","8.5x11.0x.75").withNumber("PageCount",500).withBoolean("InPublication",true).withString("ProductCategory","Book");table.putItem(item);}catch(Exceptione){System.err.println("Create items failed.");System.err.println(e.getMessage());}}privatestaticvoidretrieveItem(){Tabletable=dynamoDB.getTable(tableName);try{Itemitem=table.getItem("Id",120,"Id, ISBN, Title, Authors",null);System.out.println("Printing item after retrieving it....");System.out.println(item.toJSONPretty());}catch(Exceptione){System.err.println("GetItem failed.");System.err.println(e.getMessage());}}privatestaticvoidupdateAddNewAttribute(){Tabletable=dynamoDB.getTable(tableName);try{UpdateItemSpecupdateItemSpec=newUpdateItemSpec().withPrimaryKey("Id",121).withUpdateExpression("set #na = :val1").withNameMap(newNameMap().with("#na","NewAttribute")).withValueMap(newValueMap().withString(":val1","Some value")).withReturnValues(ReturnValue.ALL_NEW);UpdateItemOutcomeoutcome=table.updateItem(updateItemSpec);// Check the response.System.out.println("Printing item after adding new attribute...");System.out.println(outcome.getItem().toJSONPretty());}catch(Exceptione){System.err.println("Failed to add new attribute in "+tableName);System.err.println(e.getMessage());}}privatestaticvoidupdateMultipleAttributes(){Tabletable=dynamoDB.getTable(tableName);try{UpdateItemSpecupdateItemSpec=newUpdateItemSpec().withPrimaryKey("Id",120).withUpdateExpression("add #a :val1 set #na=:val2").withNameMap(newNameMap().with("#a","Authors").with("#na","NewAttribute")).withValueMap(newValueMap().withStringSet(":val1","Author YY","Author ZZ").withString(":val2","someValue")).withReturnValues(ReturnValue.ALL_NEW);UpdateItemOutcomeoutcome=table.updateItem(updateItemSpec);// Check the response.System.out.println("Printing item after multiple attribute update...");System.out.println(outcome.getItem().toJSONPretty());}catch(Exceptione){System.err.println("Failed to update multiple attributes in "+tableName);System.err.println(e.getMessage());}}privatestaticvoidupdateExistingAttributeConditionally(){Tabletable=dynamoDB.getTable(tableName);try{// Specify the desired price (25.00) and also the condition (price =// 20.00)UpdateItemSpecupdateItemSpec=newUpdateItemSpec().withPrimaryKey("Id",120).withReturnValues(ReturnValue.ALL_NEW).withUpdateExpression("set #p = :val1").withConditionExpression("#p = :val2").withNameMap(newNameMap().with("#p","Price")).withValueMap(newValueMap().withNumber(":val1",25).withNumber(":val2",20));UpdateItemOutcomeoutcome=table.updateItem(updateItemSpec);// Check the response.System.out.println("Printing item after conditional update to new attribute...");System.out.println(outcome.getItem().toJSONPretty());}catch(Exceptione){System.err.println("Error updating item in "+tableName);System.err.println(e.getMessage());}}privatestaticvoiddeleteItem(){Tabletable=dynamoDB.getTable(tableName);try{DeleteItemSpecdeleteItemSpec=newDeleteItemSpec().withPrimaryKey("Id",120).withConditionExpression("#ip = :val").withNameMap(newNameMap().with("#ip","InPublication")).withValueMap(newValueMap().withBoolean(":val",false)).withReturnValues(ReturnValue.ALL_OLD);DeleteItemOutcomeoutcome=table.deleteItem(deleteItemSpec);// Check the response.System.out.println("Printing item that was deleted...");System.out.println(outcome.getItem().toJSONPretty());}catch(Exceptione){System.err.println("Error deleting item in "+tableName);System.err.println(e.getMessage());}}}
Column-Oriented/Family Databases
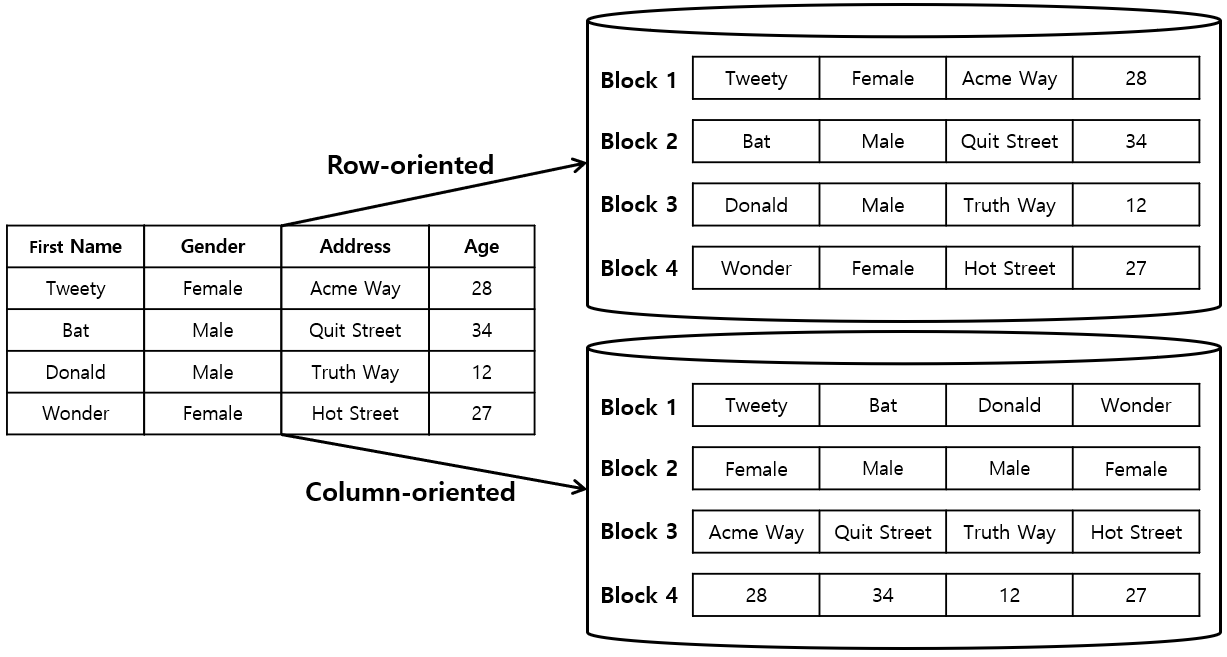
1.Column-Oriented Databases
Column-Oriented DB
Column-Oriented DB는 Tabled의 data를 Column 단위로 쪼개어 저장하는 DB를 의미한다.
Column-Oriented DB는 하나의 Column이 하나의 Disk Block안에 저장된다.
Column-Oriented DB는 1개의 Block만 읽고 결과를 구할 수 있기 때문에 빠른 처리가 가능하다.
이처럼 Data를 분석하는 동작의 경우 Data Table에서 모든 Column이 필요한 것이 아니라 일부 Column이 필요한 경우가 대부분이다.
따라서 Column-oriented DB는 OLAP(Online Analytical Processing) 처리에 유리한 반면, OTLP(Online transaction processing) 처리에 불리하다.
2.Column-Family Databases
Column-Family DB
Column-Family DB는 Column을 나타내는 Column Key/Data/Timestamp Tuple을 Row를 나타내는 Row Key에 Mapping하여 Data Table을 표현하는 DB이다.
RDBMS에서 NULL값도 Disk Block 공간을 차지하지만 Column Family DB에서는 Row별로 자유로운 Column 추가/삭제가 가능하기 때문에 NULL값을 위한 Column이 별도로 필요없다.
일반적으로 Column-oriented DB와 Column Family DB가 혼용되어 사용되어 Column Family DB가 Column-oriented DB라고 간주하는 경우가 많은데 같은 DB라고 할 수는 없다.
Column Family DB인 HBASE는 Column의 집합인 Column Family 단위로 Disk Block에 저장되기 때문에 Column-oriented DB로 분류된다.
하지만 또 하나의 Column Family DB인 Cassandra는 Row 단위로 Disk Block에 저장되기 때문에 Column-oriented DB라고 할 수 없다.
Cassandra DB의 CRUD 예제
-- create a tupleCREATETABLEsubjects(kintPRIMARYKEY,vtuple<int,text,float>);-- insert valuesINSERTINTOsubjects(k,v)VALUES(0,(3,'cs',2.1));-- retrieve valuesSELECT*FROMsubjects;
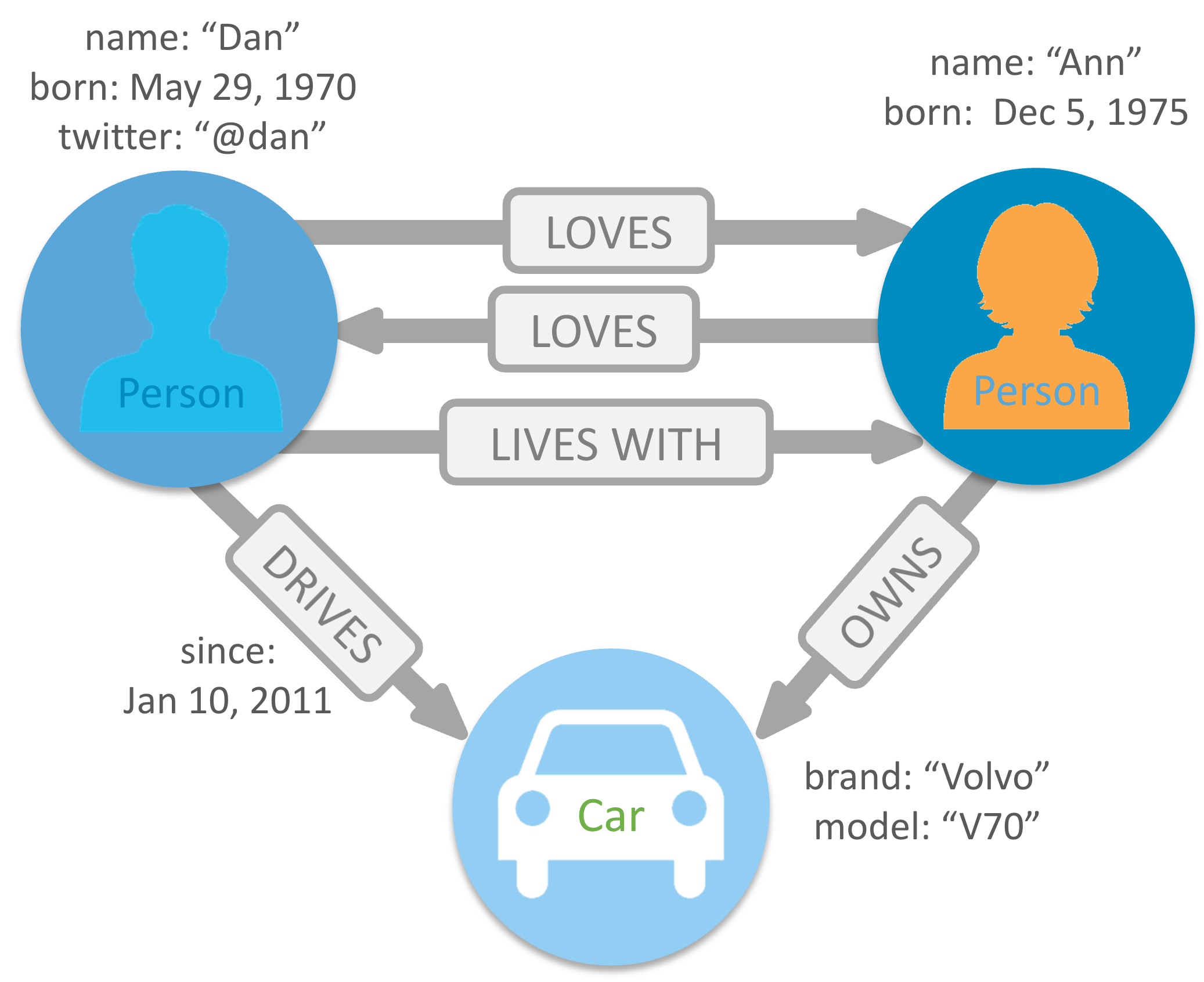
Graph Databases
Graph DB
Graph DB는 관계를 저장하고 탐색하도록 특별히 구축되다.
Graph DB는 노드를 사용하여 데이터 엔터티를 저장하고, 엣지로는 엔터티 간의 관계를 저장하게 되는데, 엣지는 항상 시작 노드, 끝 노드, 유형과 방향을 가지며, 상-하위 관계, 동작, 소유자 등을 문서화 한다.
하나의 노드가 가질 수 있는 관계의 수와 종류에는 제한이 없다.
Graph DB 그래프는 특정 엣지의 유형 또는 전체 그래프를 전반을 통하여 트래버스될 수 있다.
Graph DB에서 노드 간의 관계는 쿼리 시간에는 포함되지 않지만 데이터베이스에서 유지되기 때문에 조인 또는 관계를 트래버스하는 속도가 매우 빠르다.
Graph DB는 데이터 간의 관계를 만들고 이러한 관계를 신속하게 쿼리해야 할 때 소셜 네트워킹, 추천 엔진, 이상 탐지 등의 사용 사례에 유용하다.
Graph DB는 Neo4j, RedisGraph(Redis에 내장된 그래프 모듈), OrientDB 등이 있다.
SQL의 언어의 사용량이 높긴 하지만 NoSQL의 사용량도 점차 꾸준히 늘고 있다. 즉, 기획하고 설계하는 프로젝트에 대해 선택하는 언어가 다른 거 같다. 어느 한쪽이 좋은 언어 라고 얘기하기는 어려운 거 같다. 각자의 장/단점이 있는 언어이기 때문에 해당 프로젝트에 가장 알맞은 언어를 선택하여 설계하여 개발하는 것이 가장 좋은 거 같다.
![[Routine] 3 주차 시작!](/assets/img/daily/routine/2023/2023-02-05/2023-02-05-myroutine-3nd.png)





![[리팩토링] 무분별한 팝업창 코드 공통 함수로 리팩토링](/assets/img/development/problem_solving/2023-02-03/refactoring_common_popup_cover.png)
![[Routine] 2 주차 시작!](/assets/img/daily/routine/2023/2023-01-29/2023-01-29-myroutine-2nd.png)



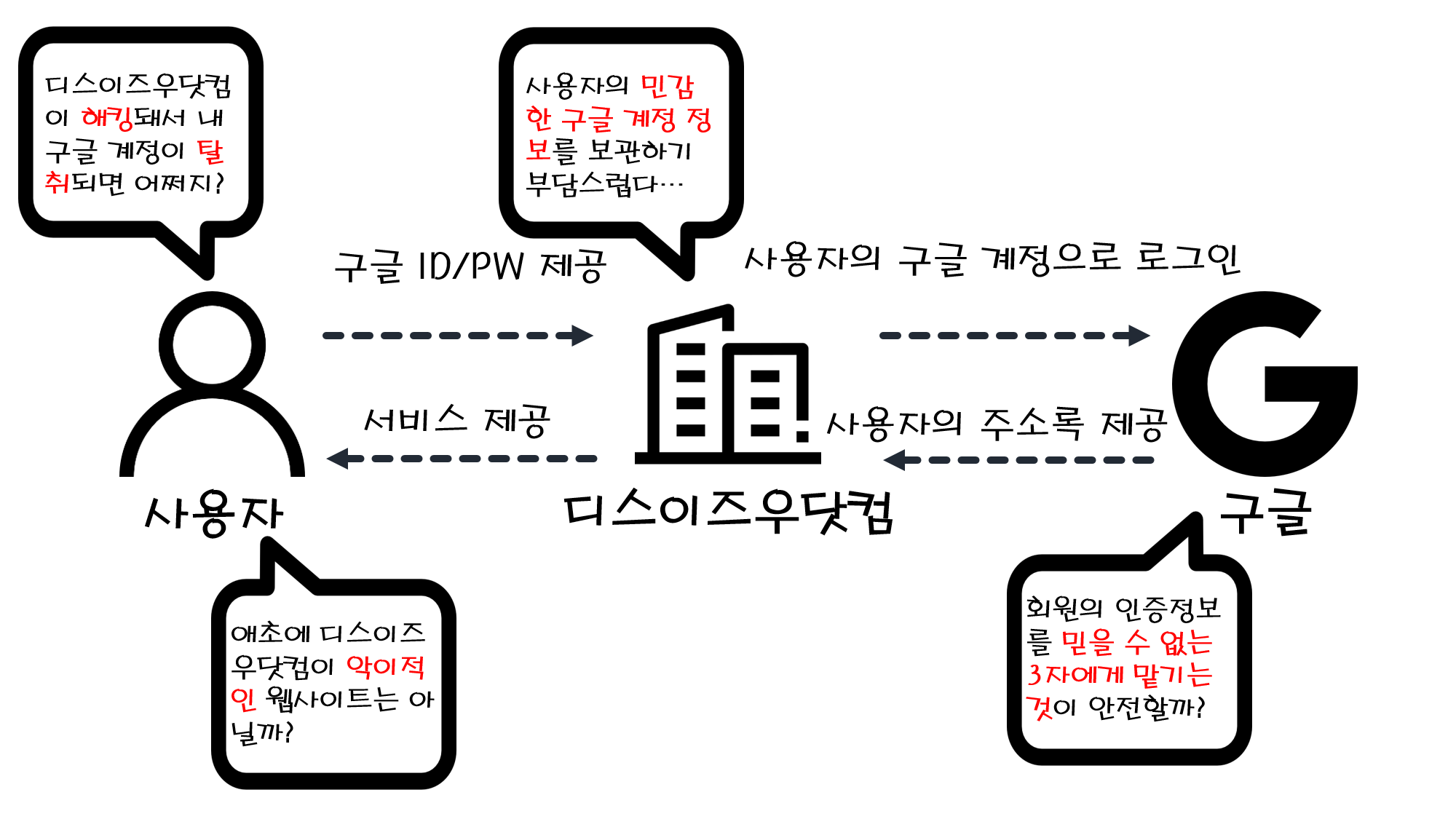
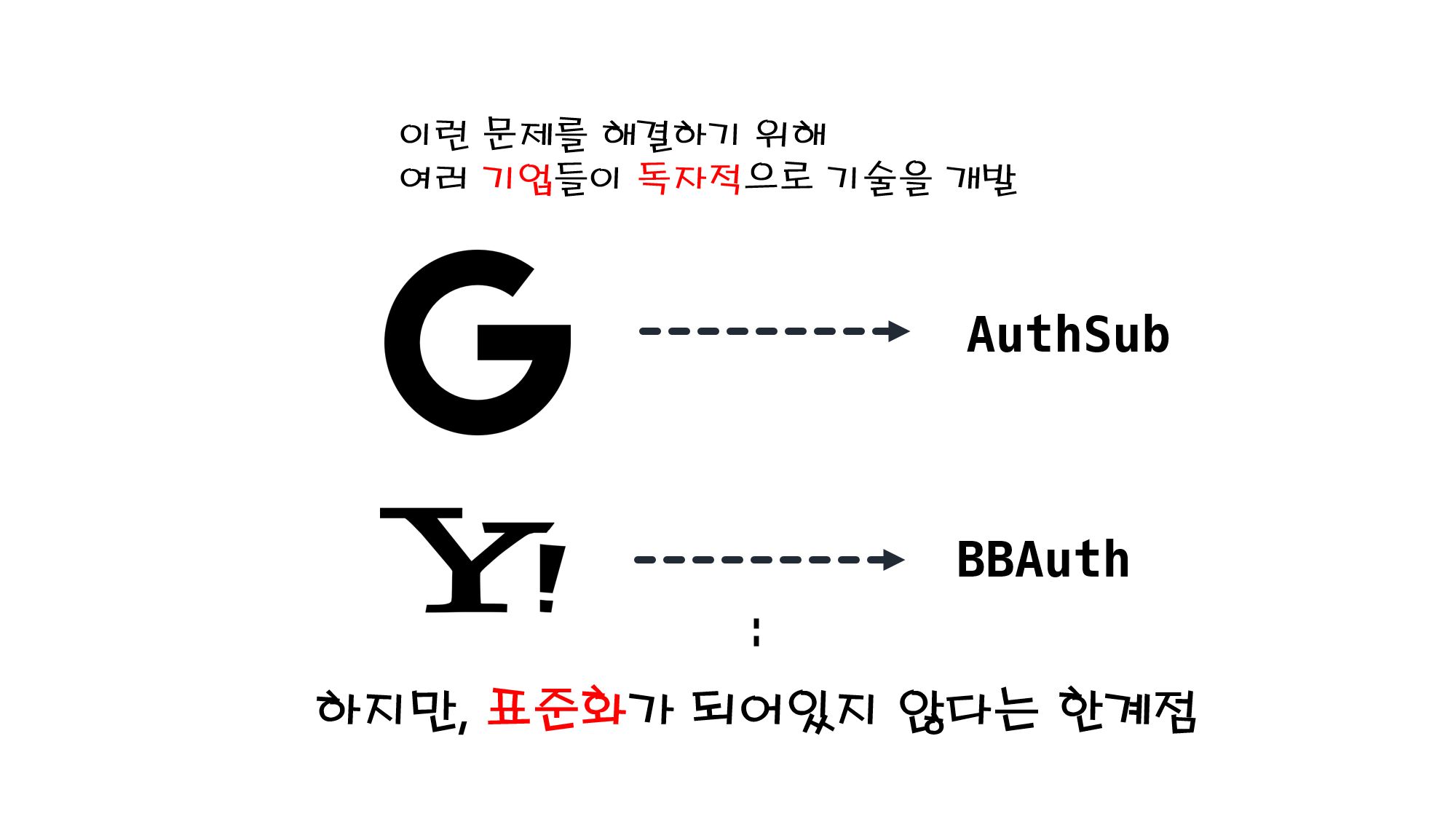
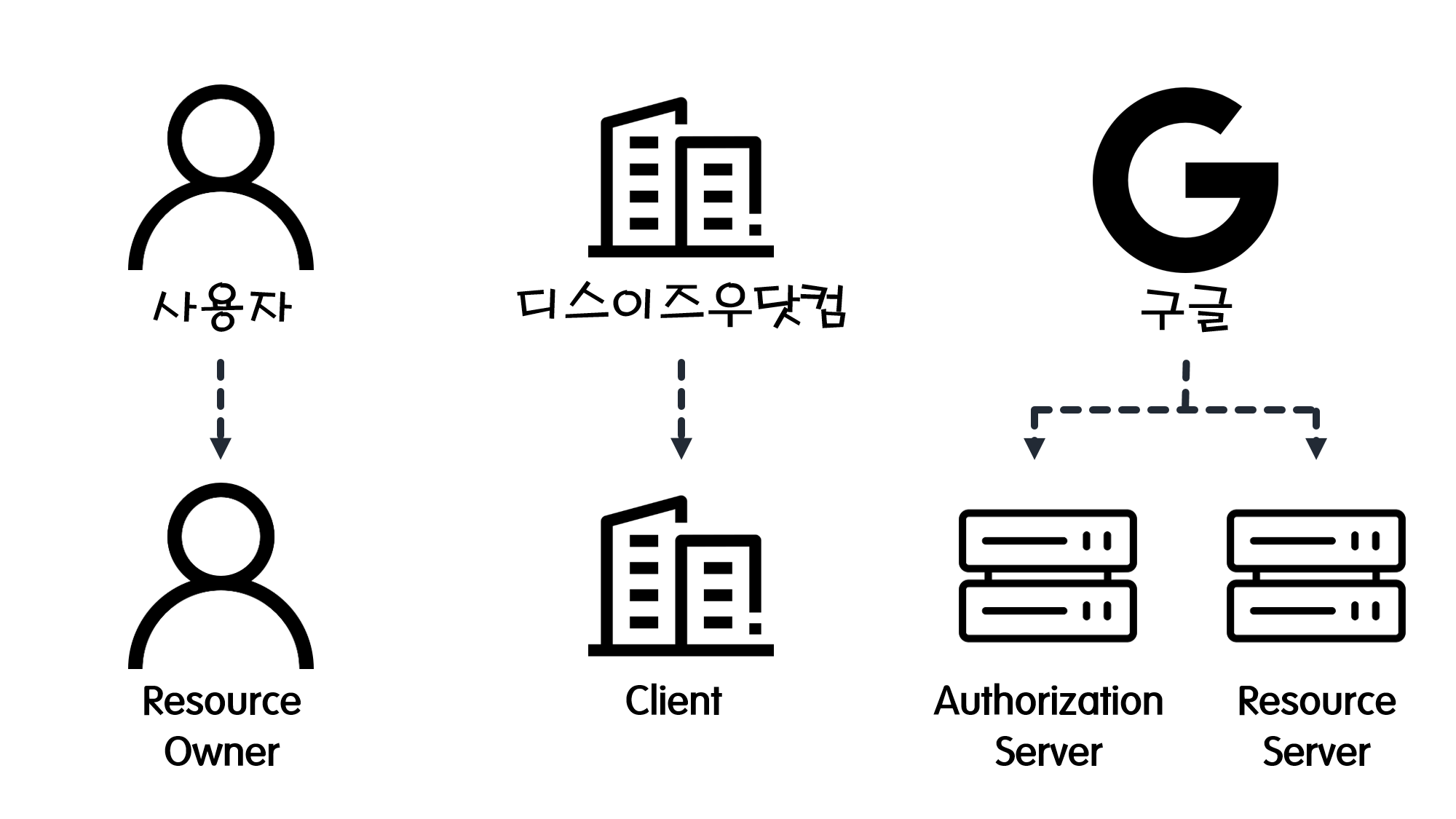
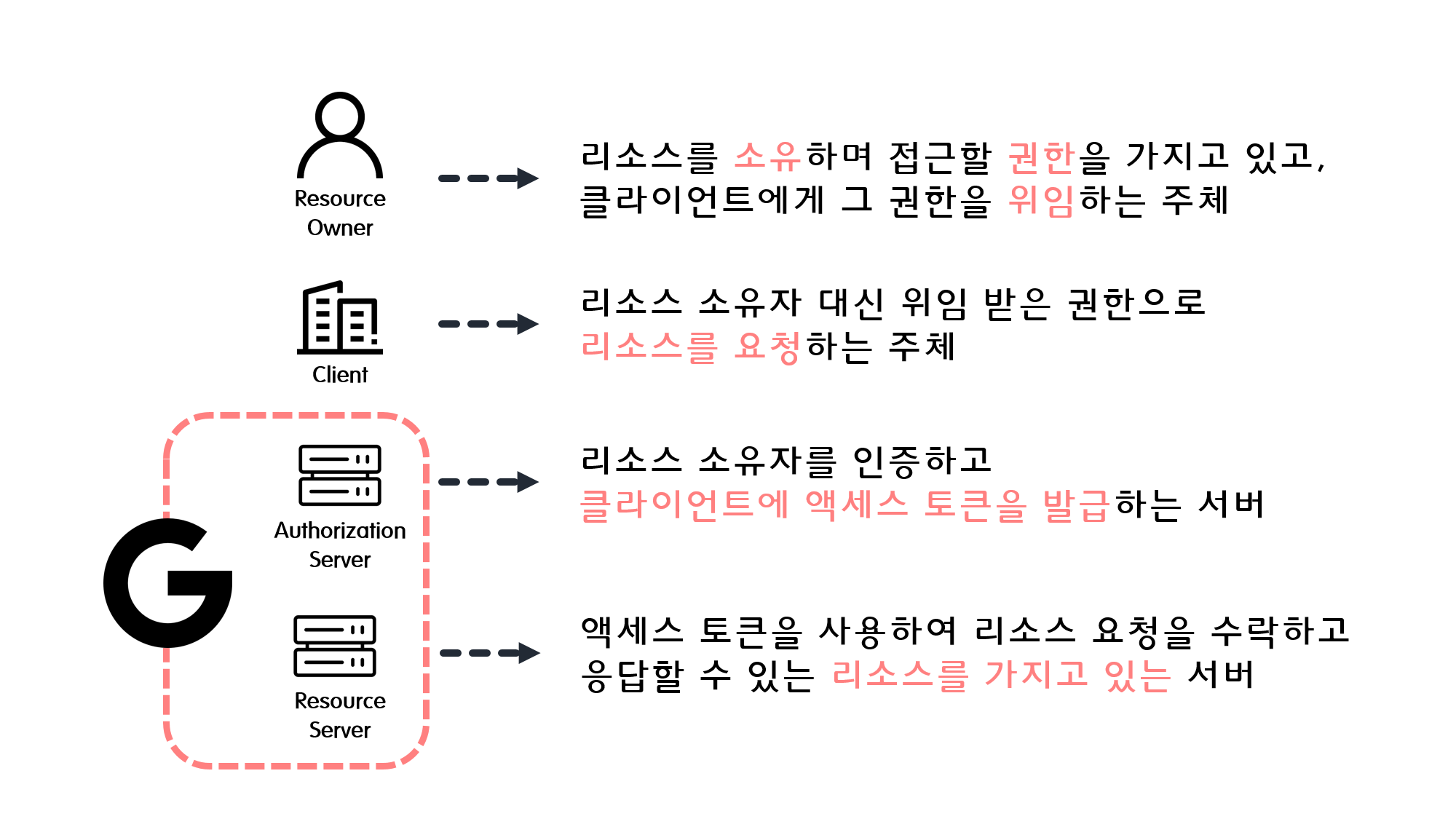
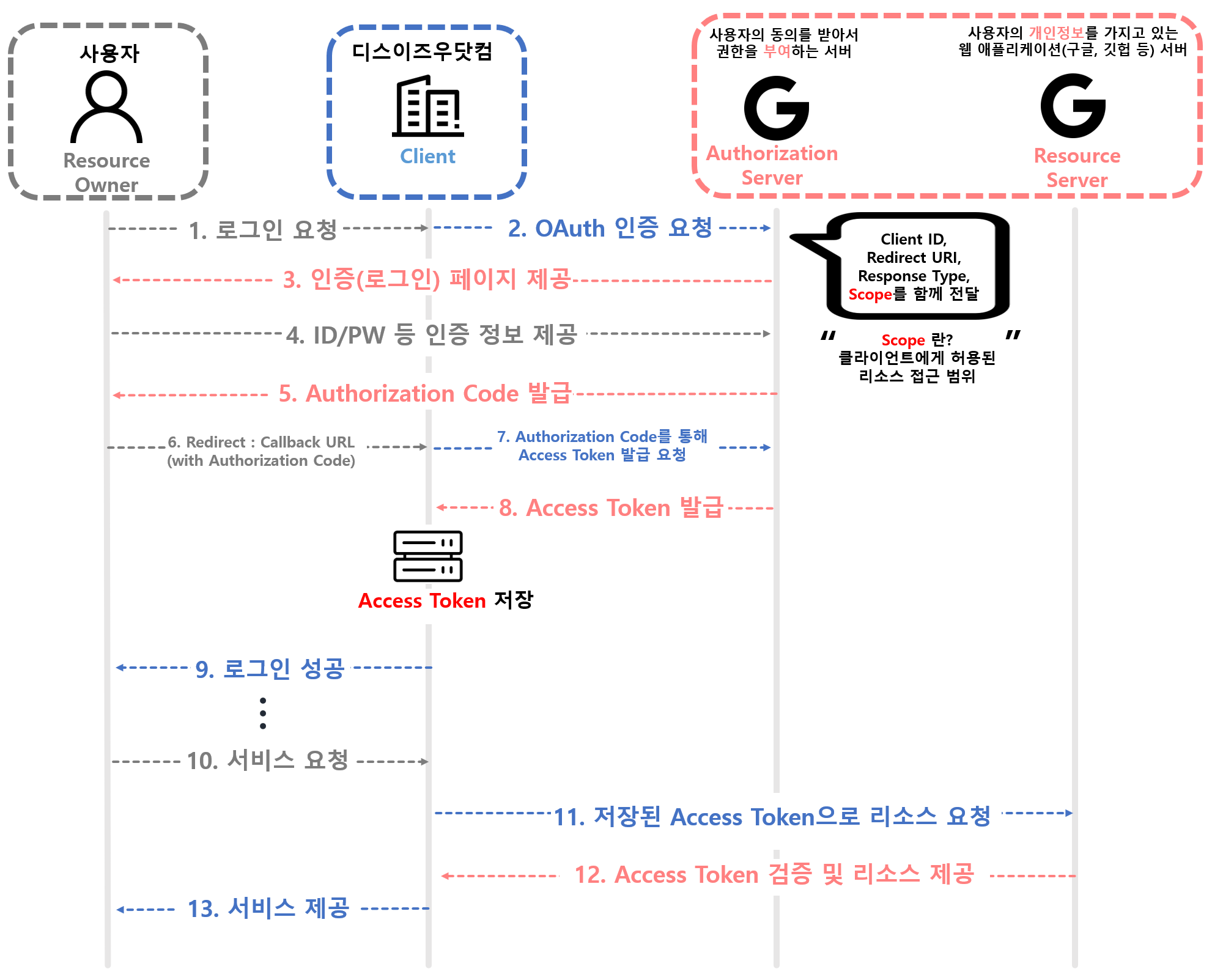
![[Security] OAuth 2.0](/assets/img/development/server/2023-01-26/oauth_cover.png)
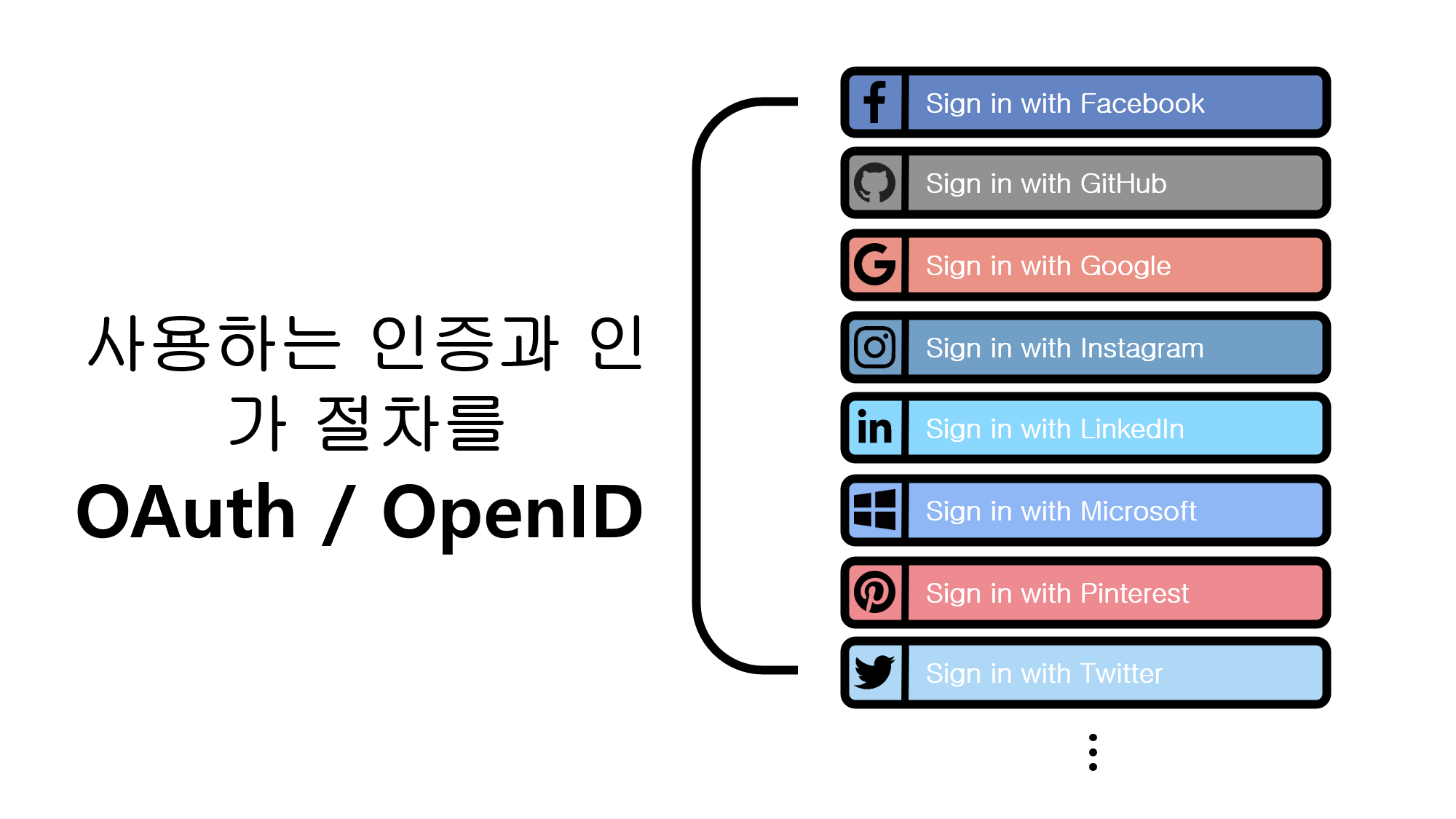
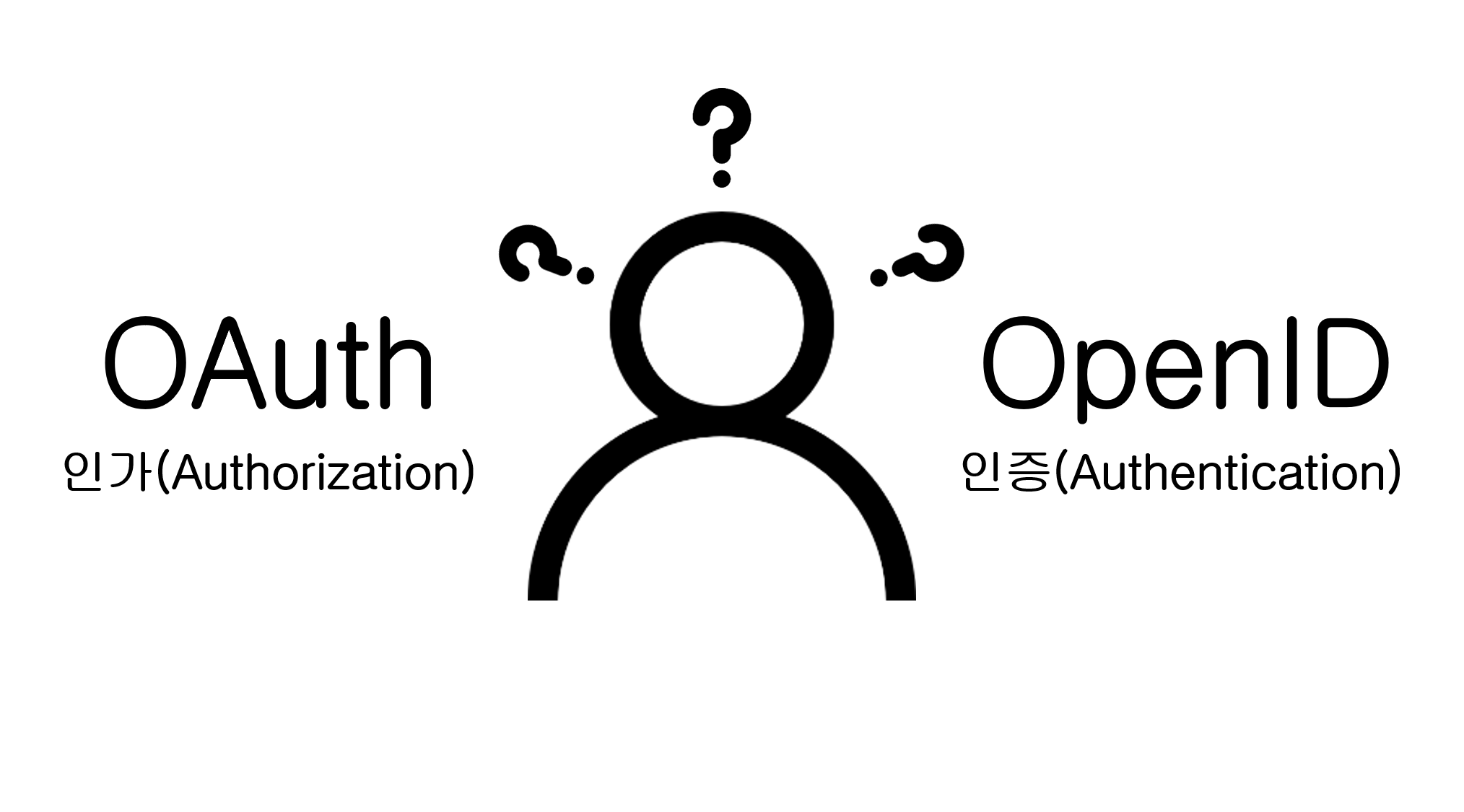
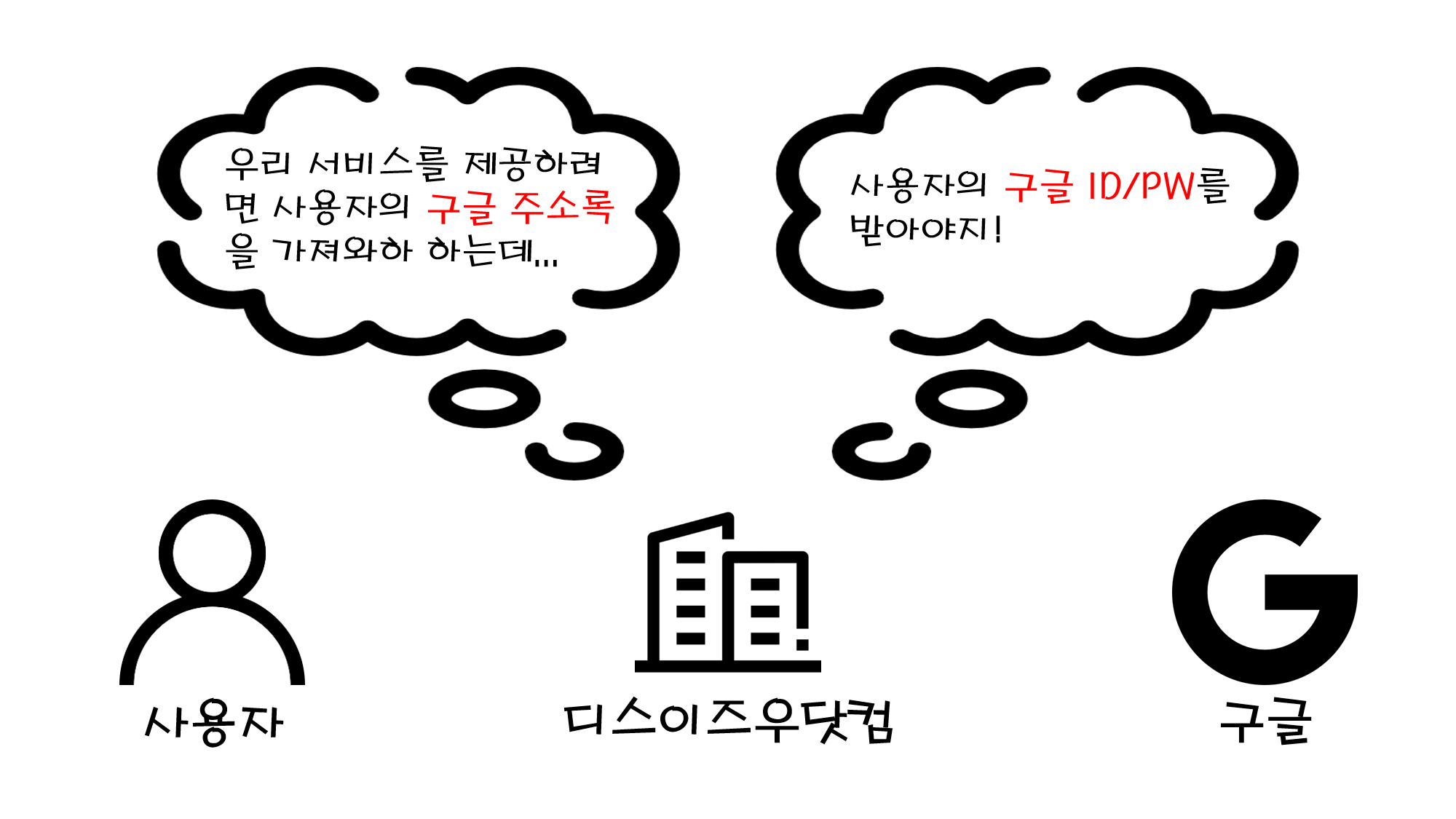


![[Routine] 첫 주차 시작!](/assets/img/daily/routine/2023/2023-01-22/2023-01-22-myroutine-1st.png)
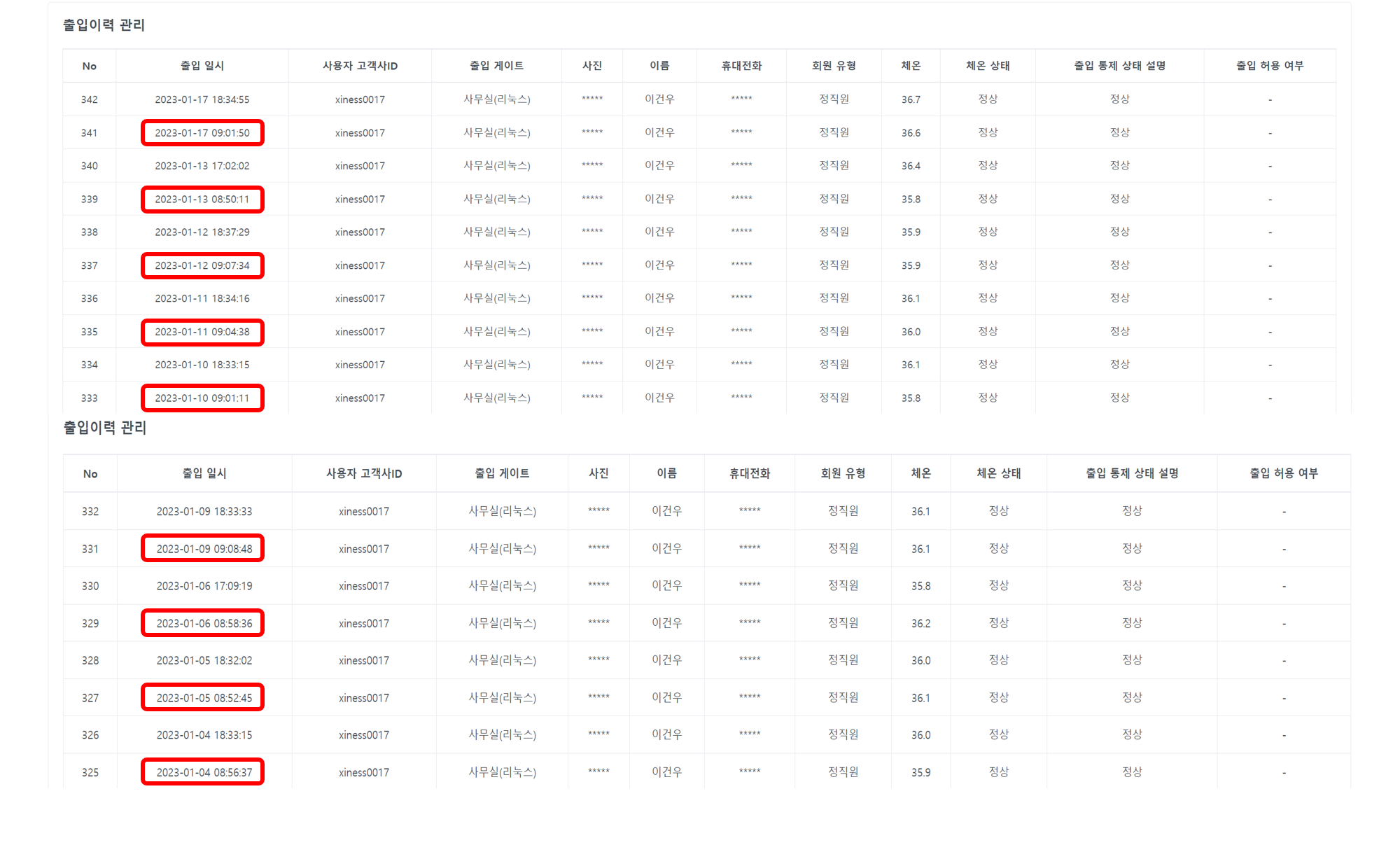



![[Security] 인증과 인가](/assets/img/development/server/2023-01-18/authentication_authorization_cover.png)

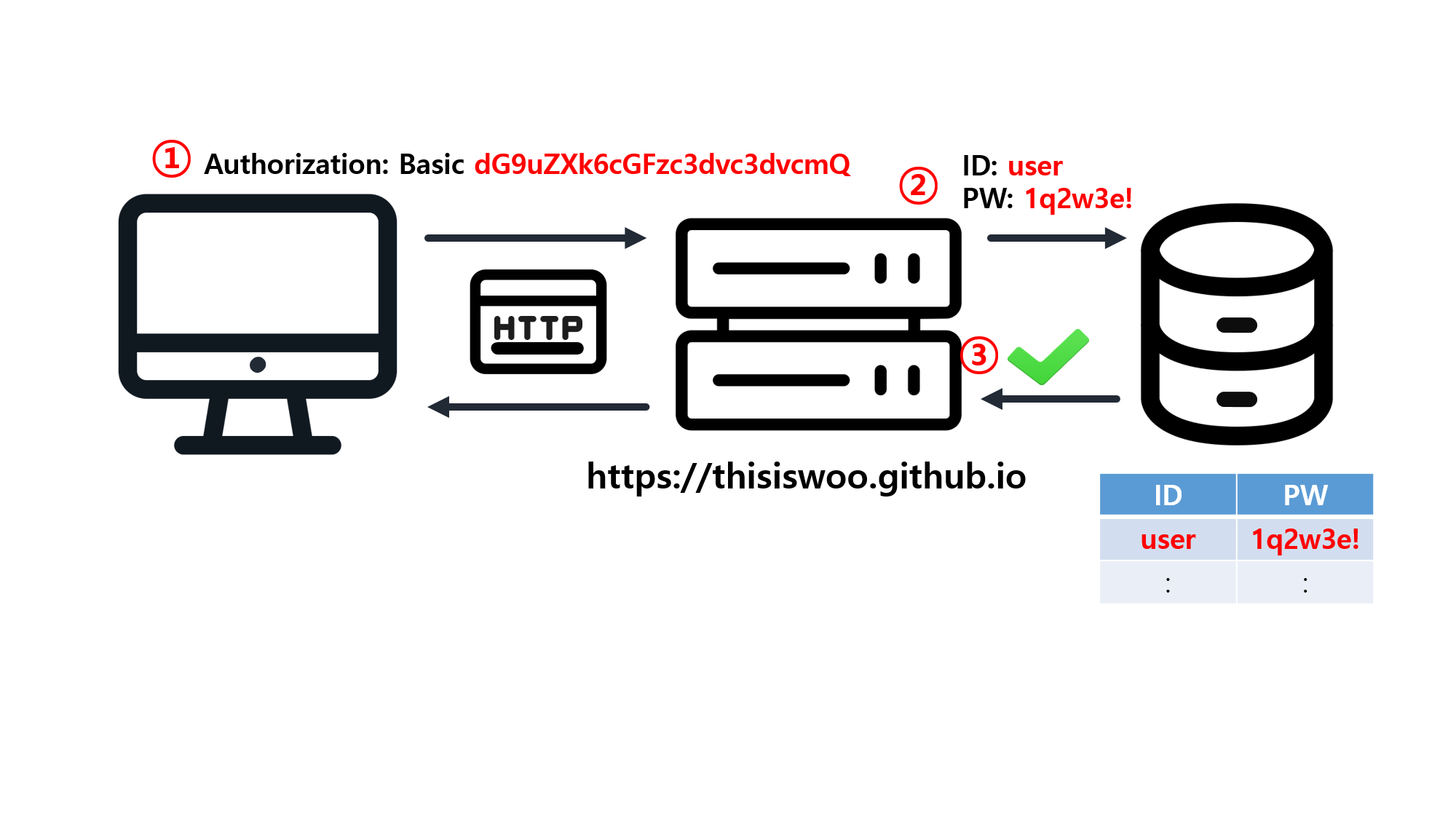
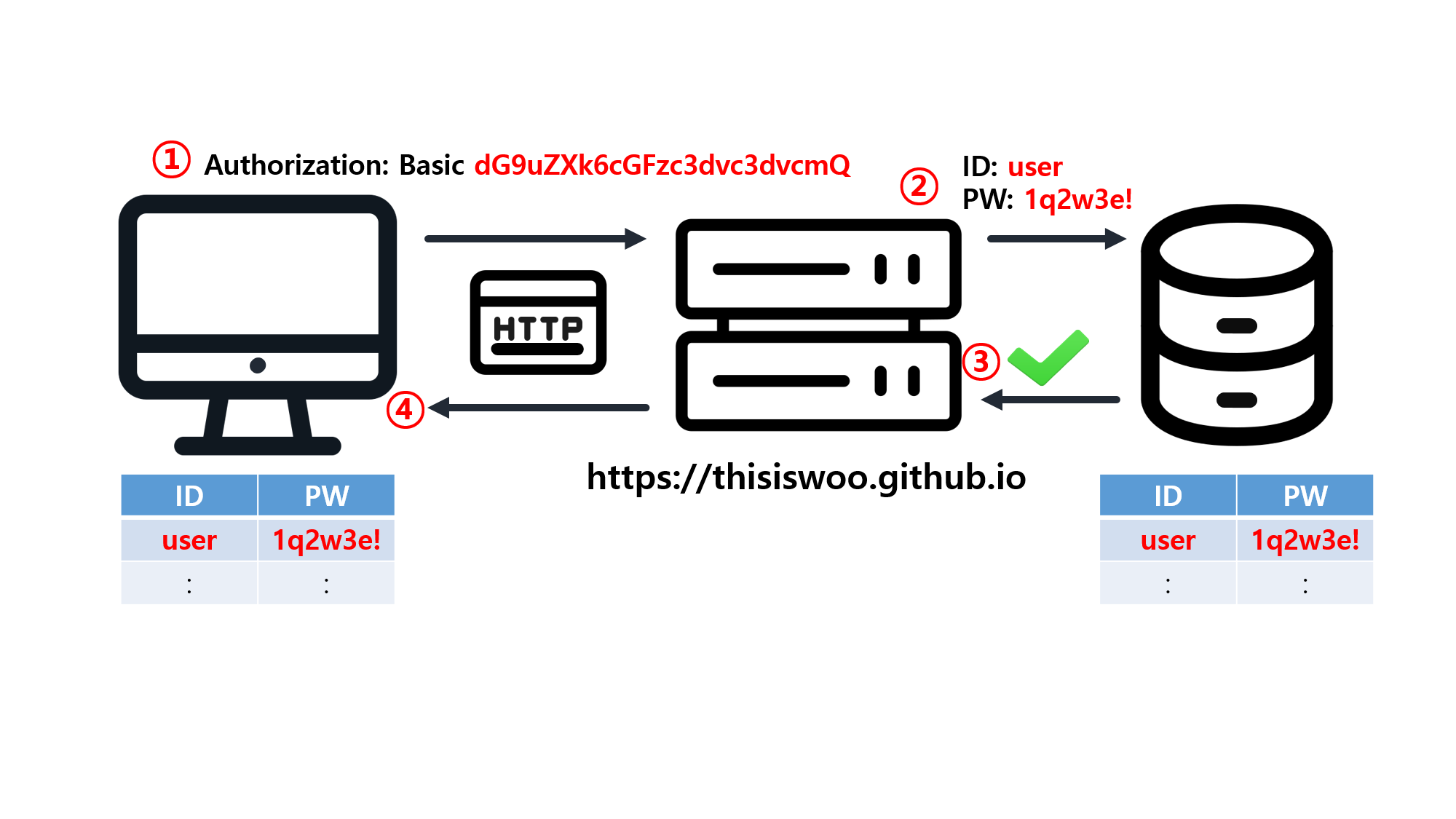
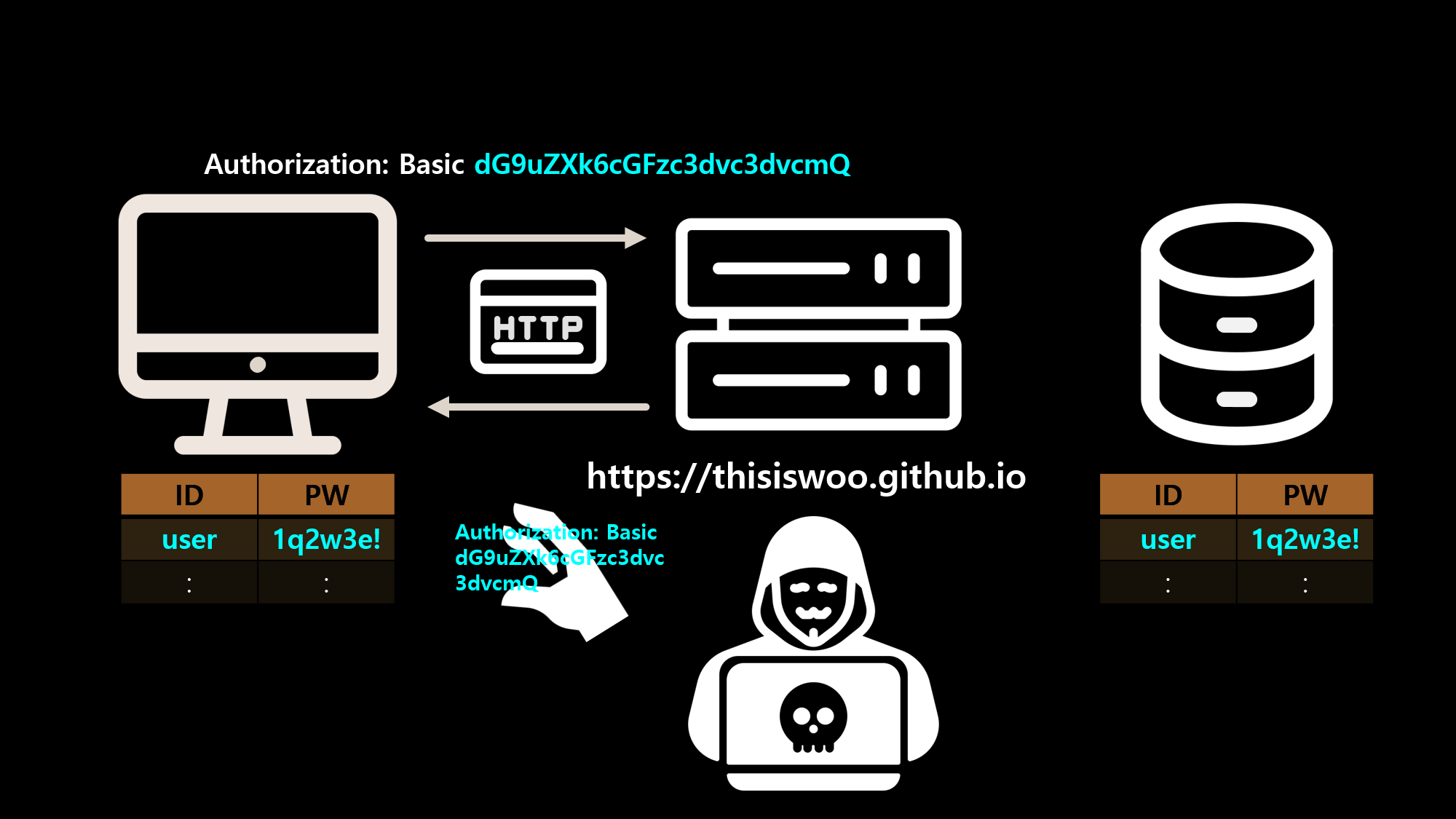
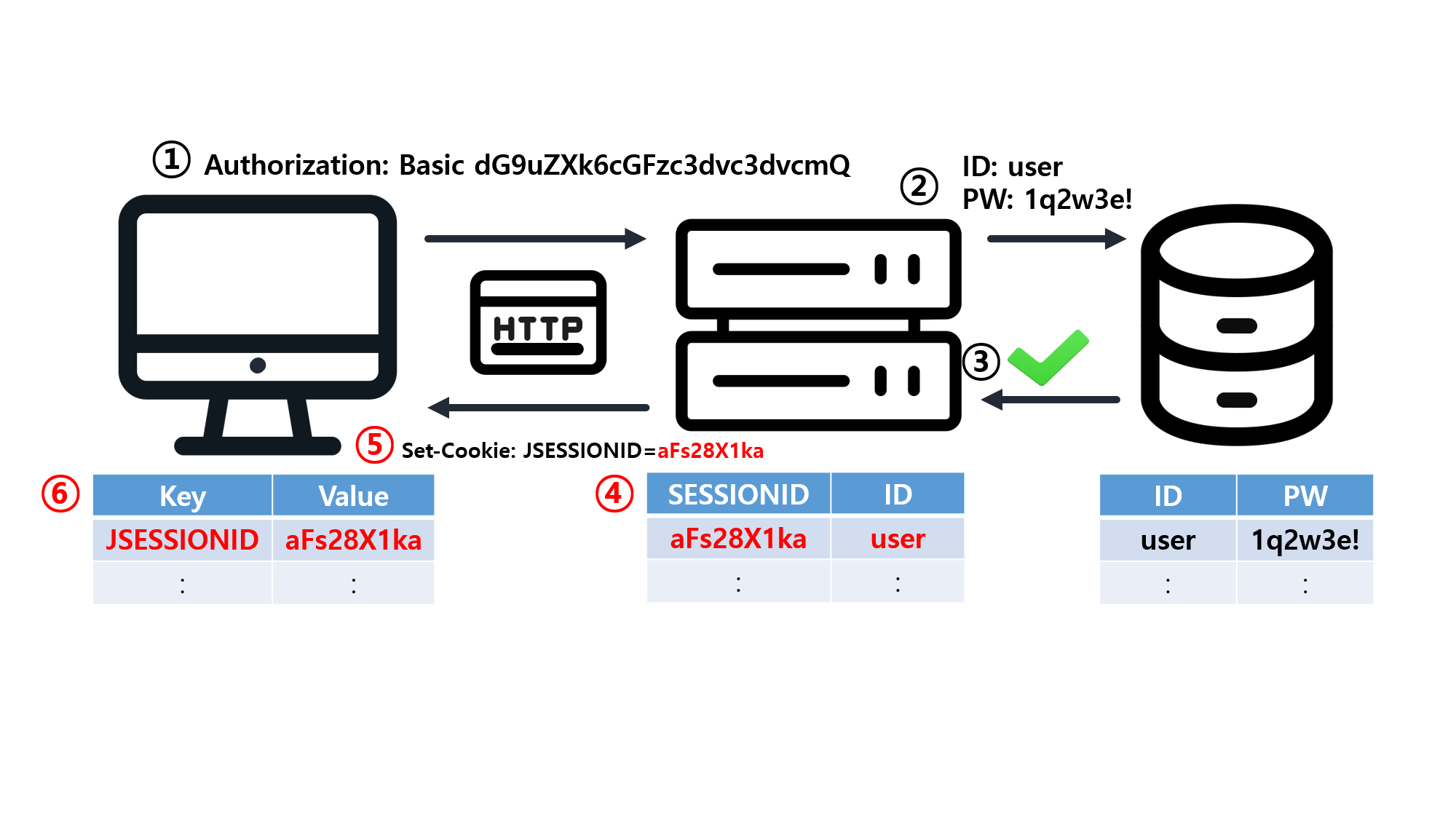
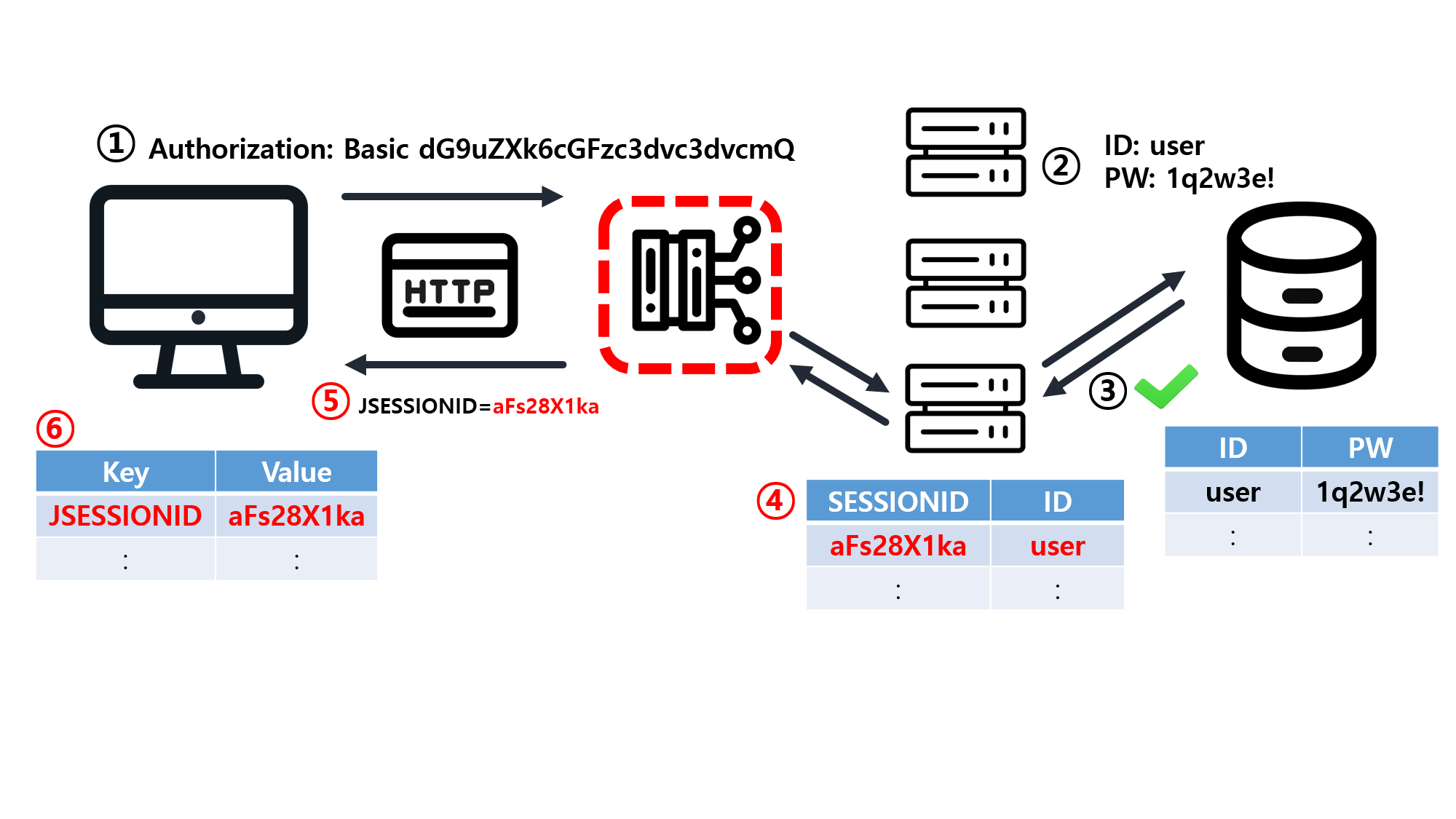
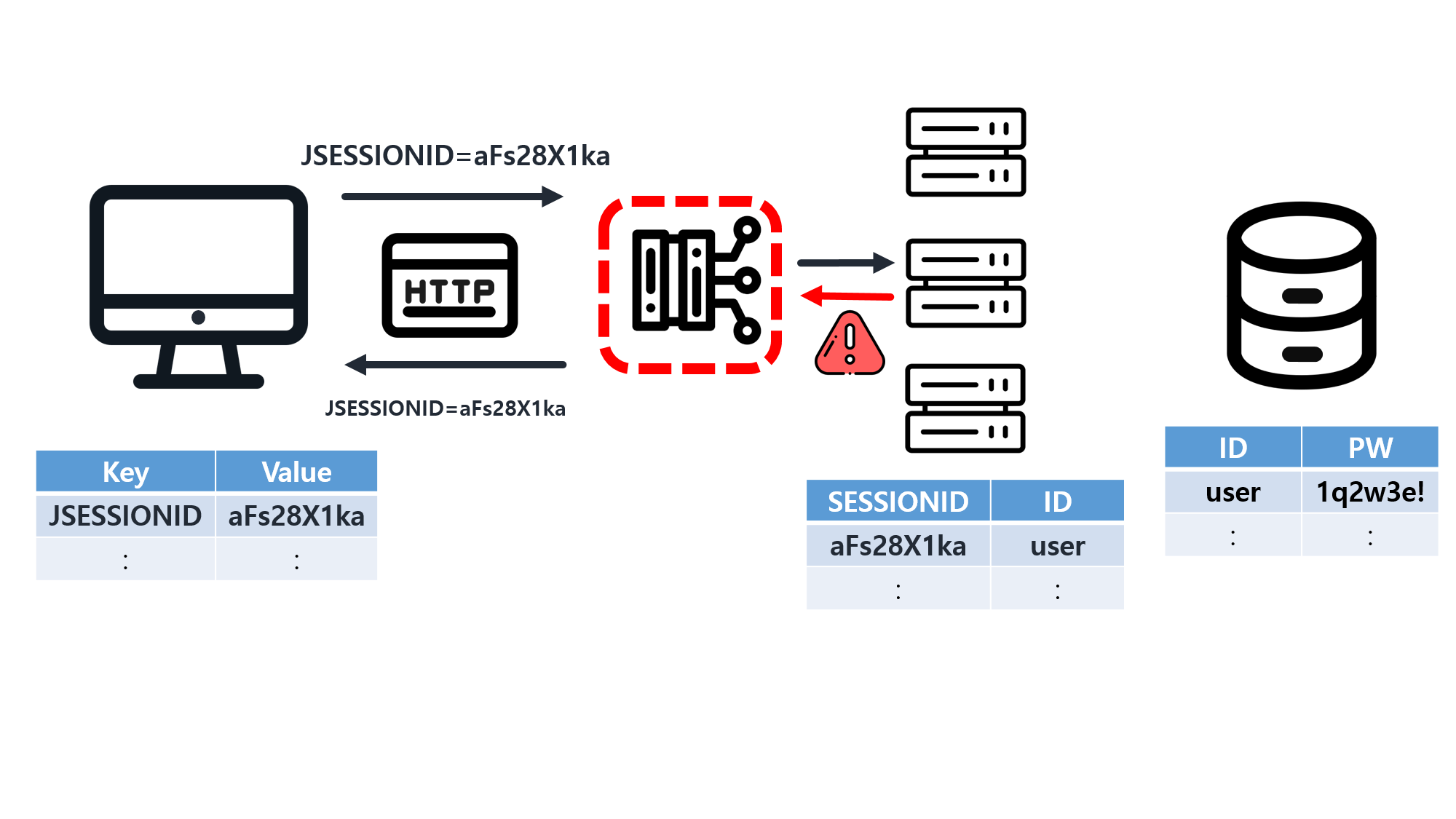
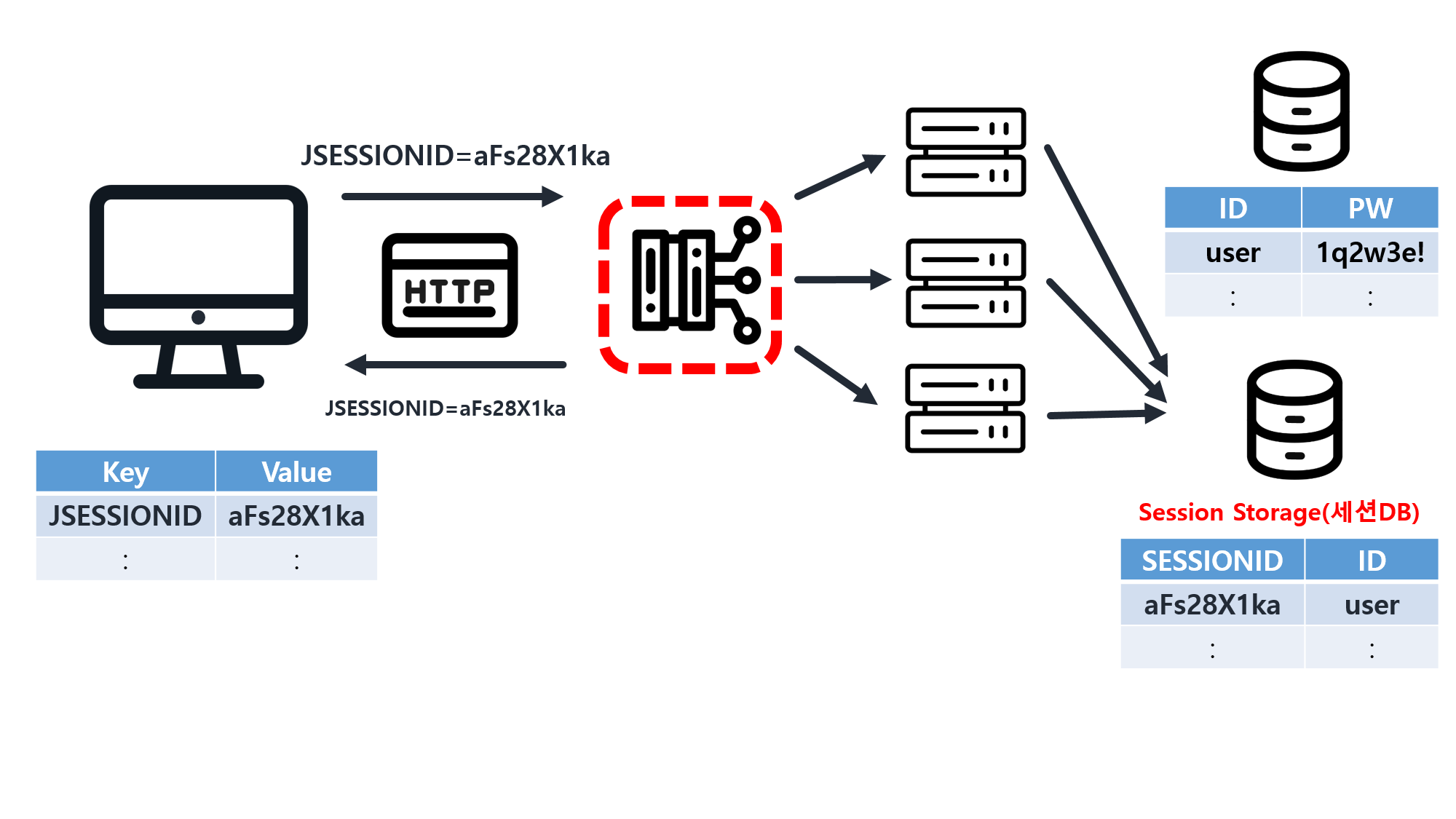
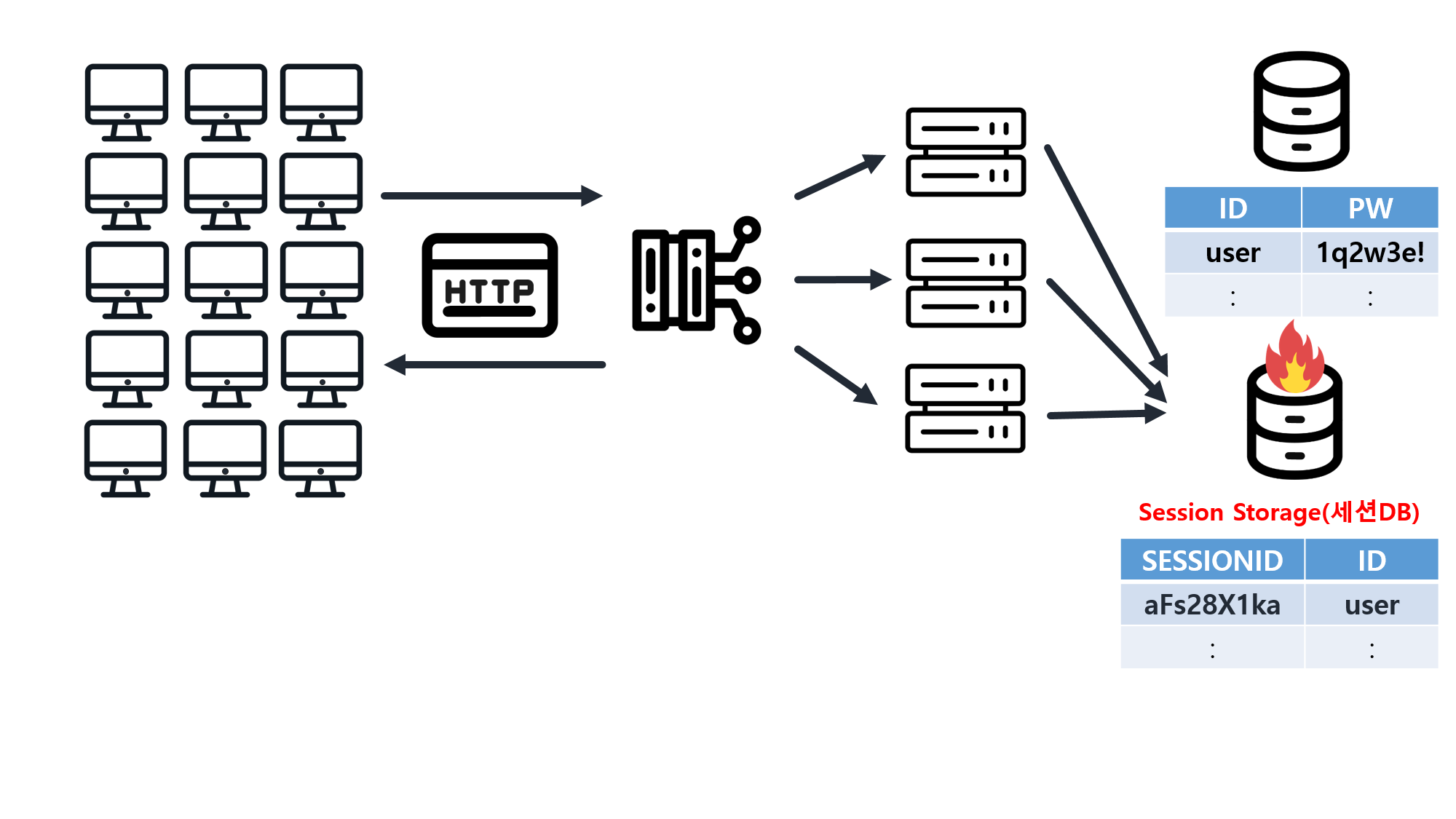
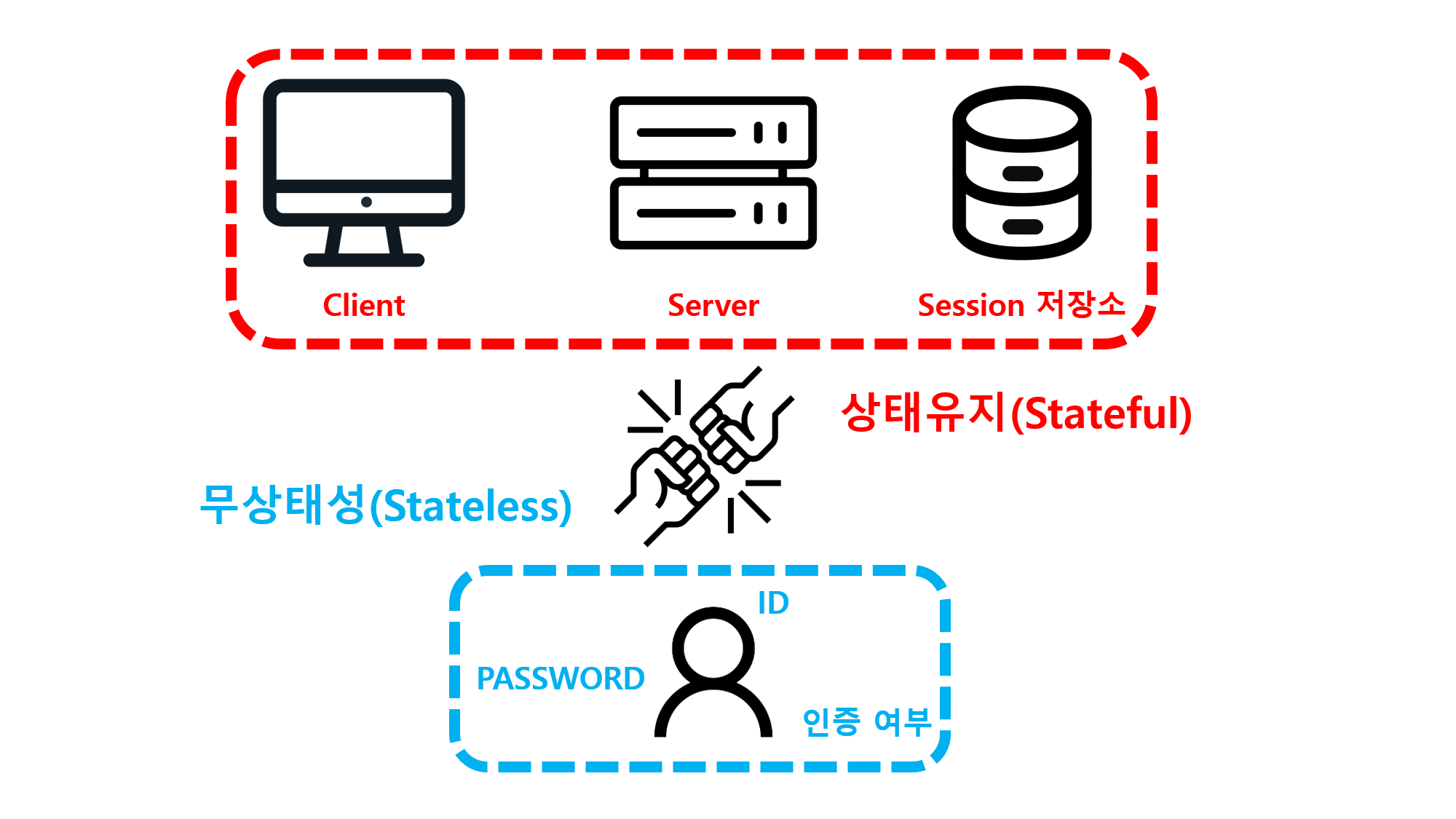
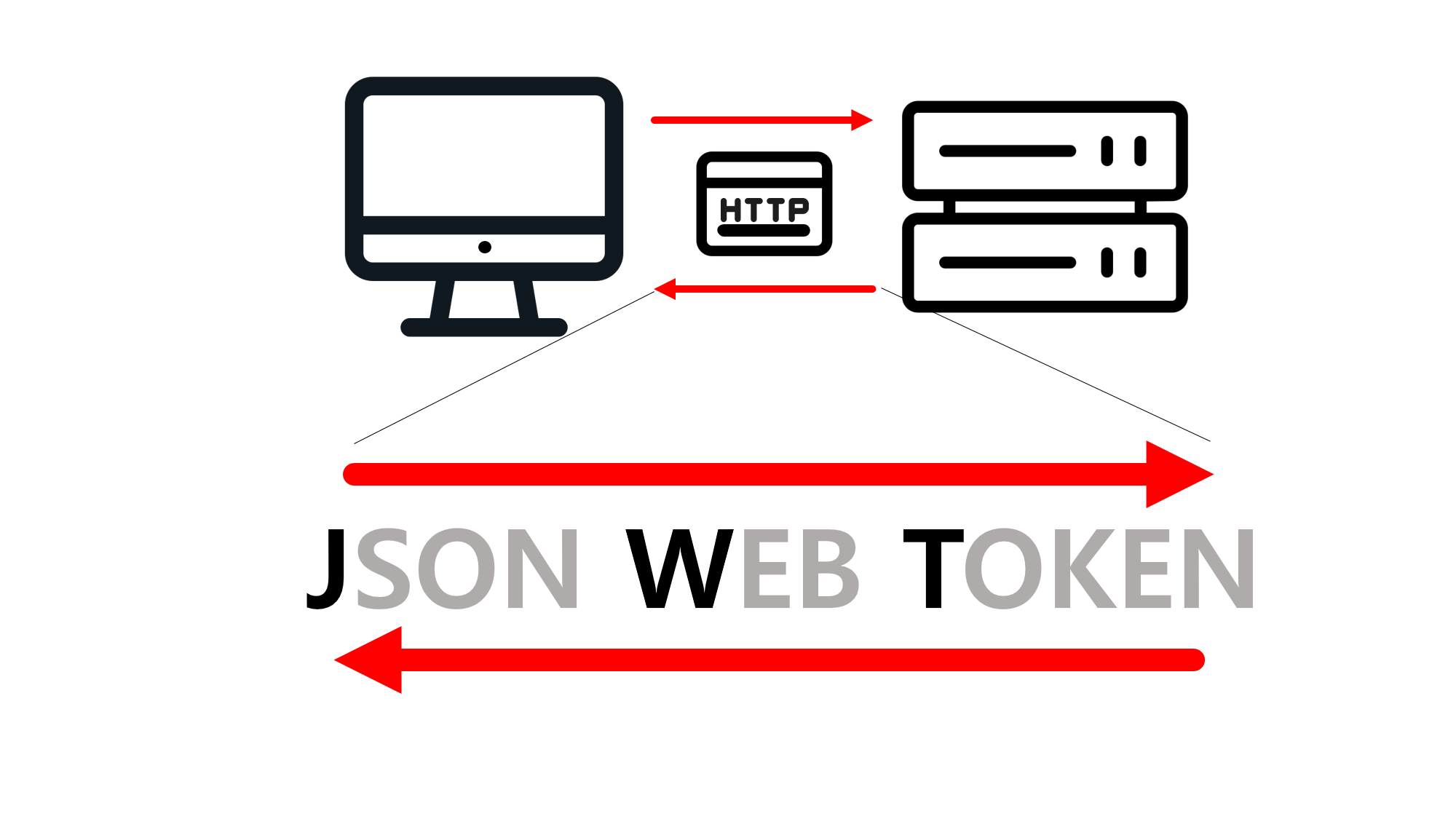
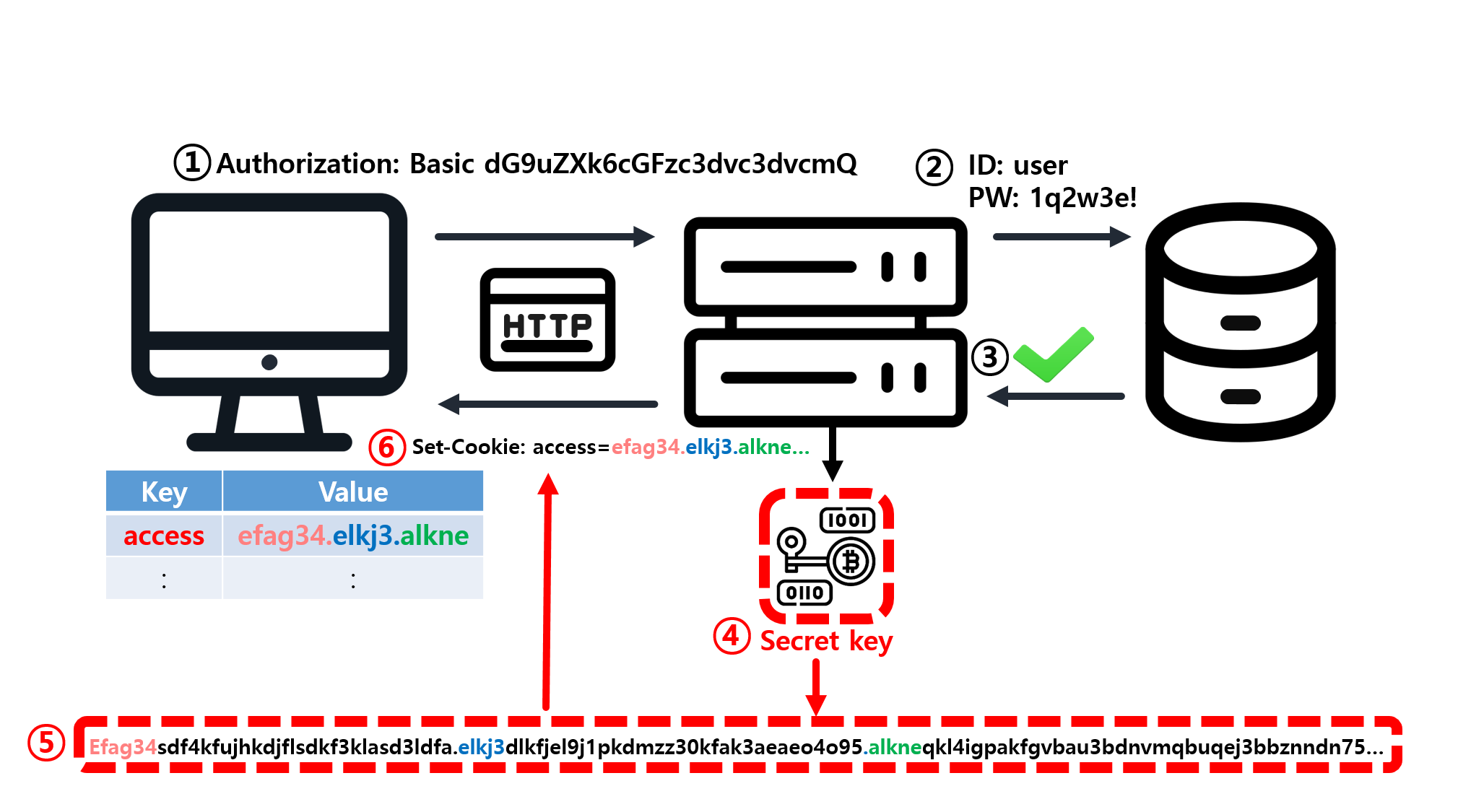
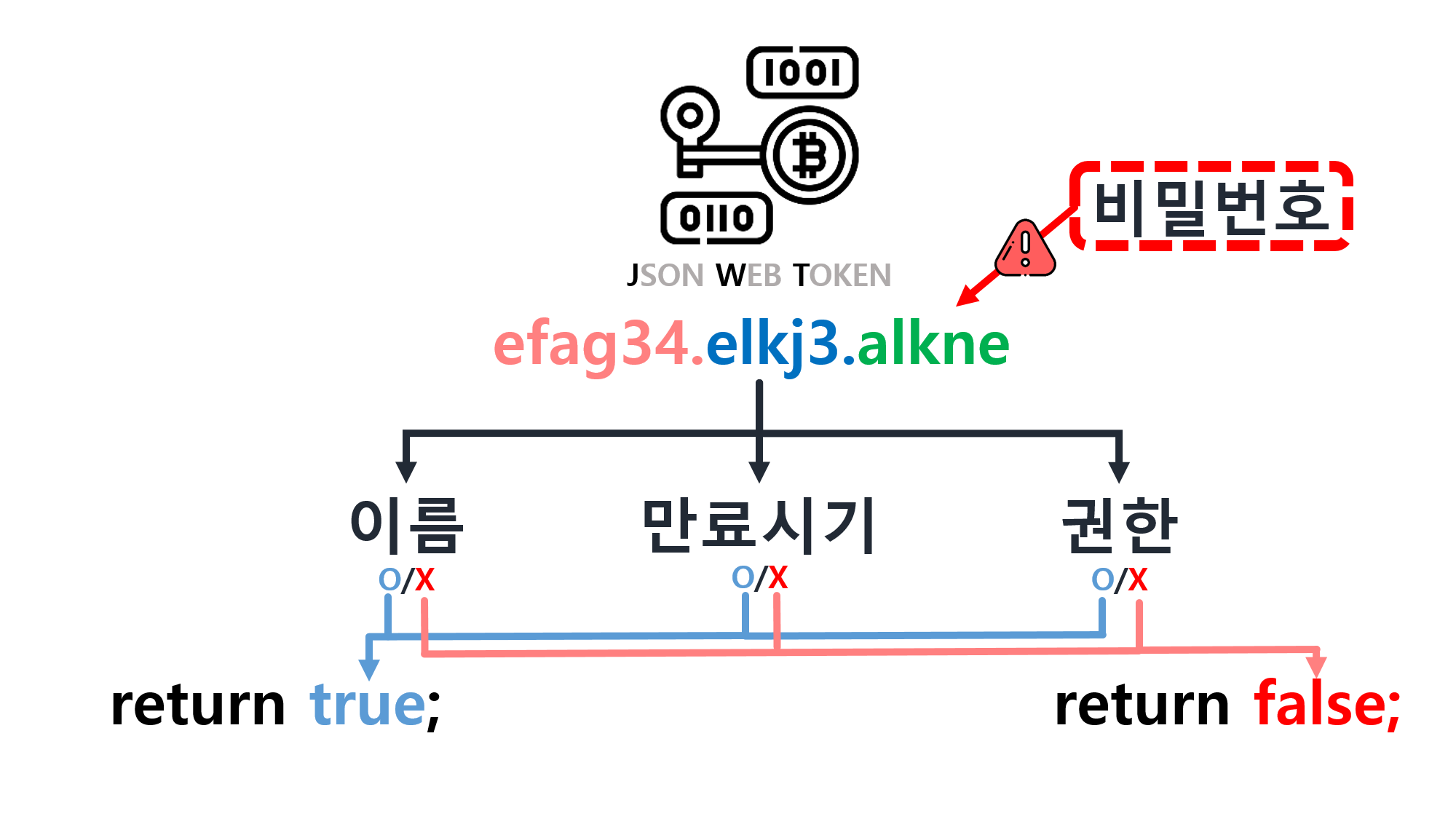
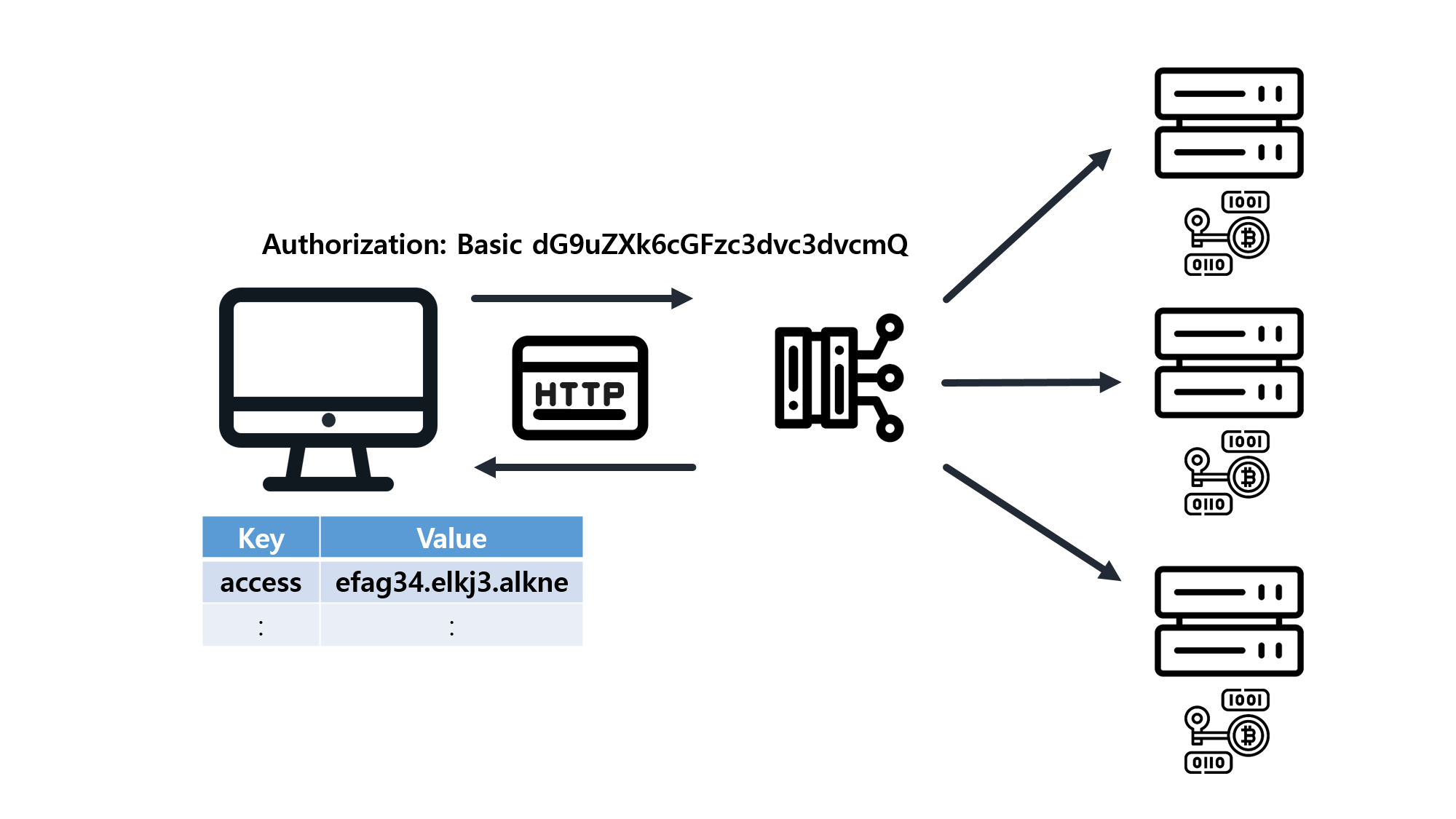
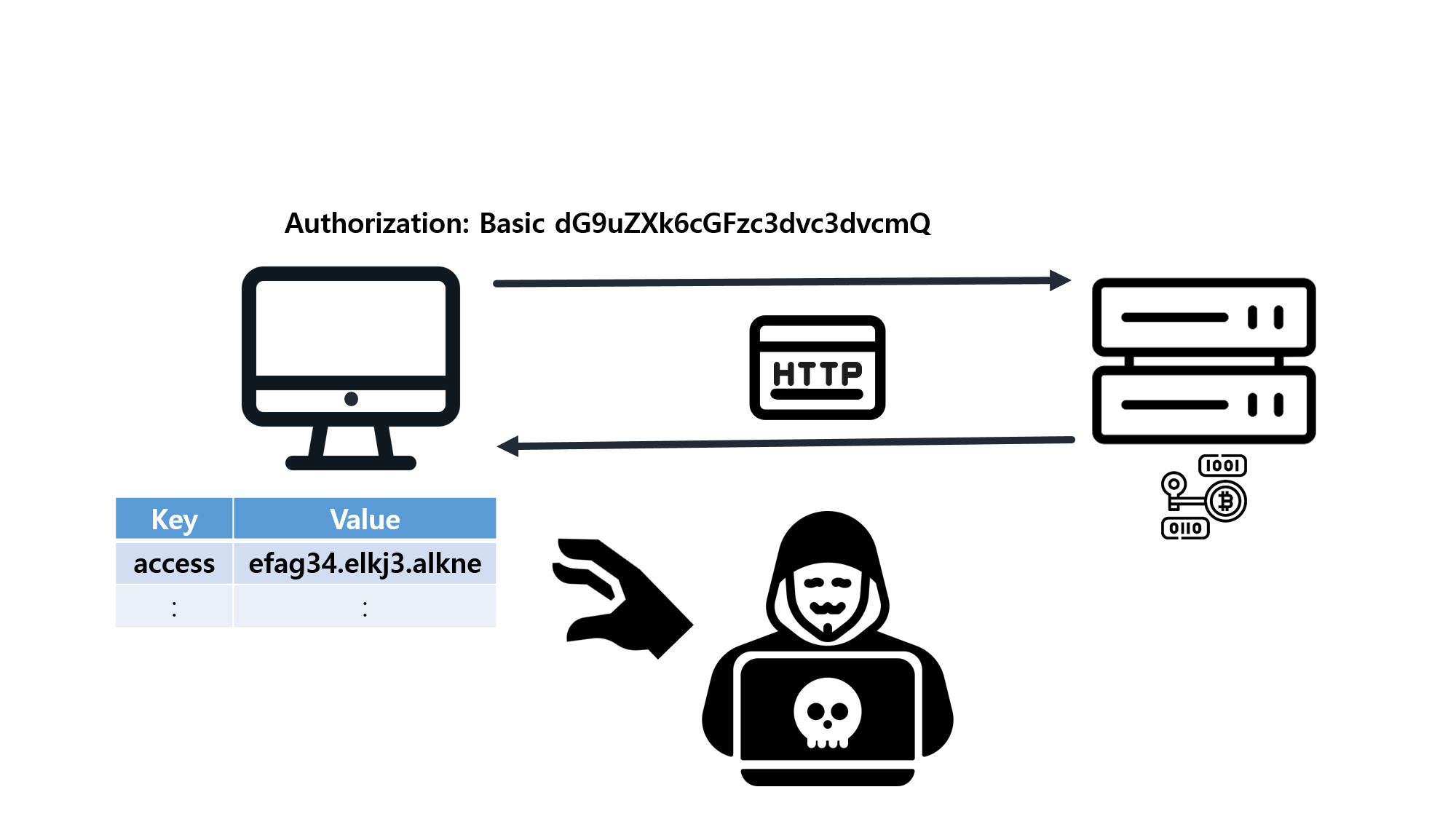
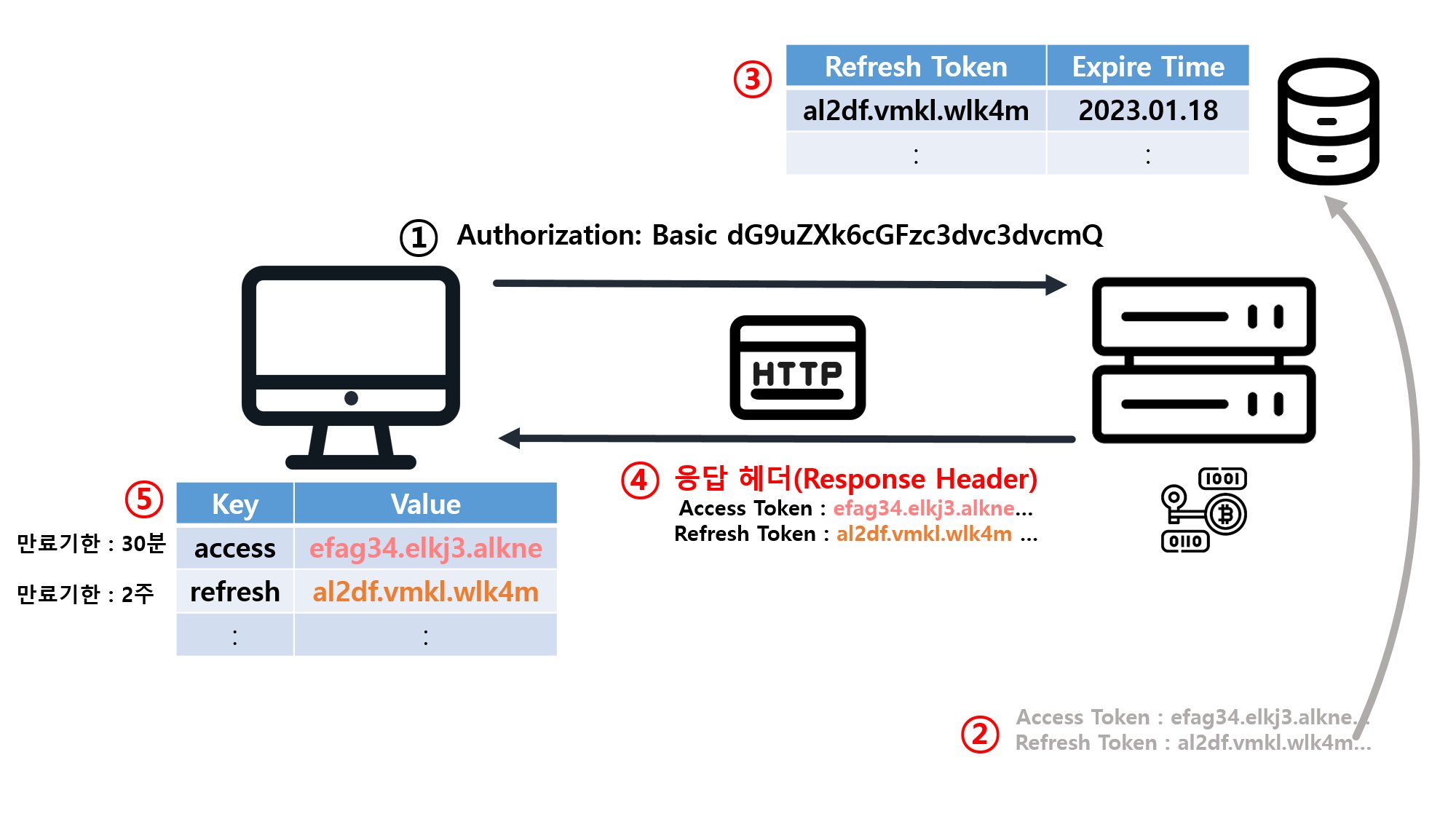
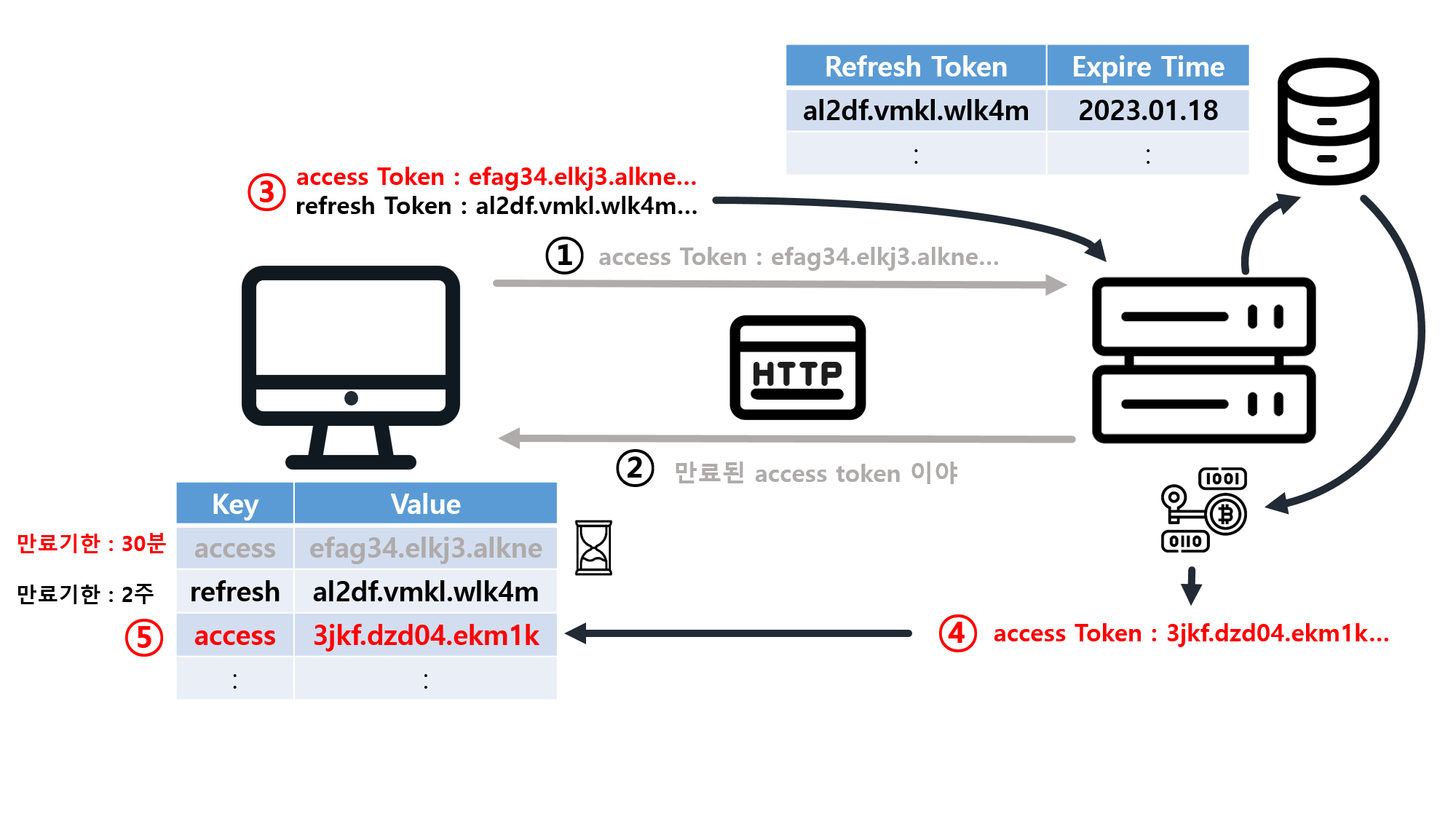
![[SQL] SQLD 핵심 요약 - [1과목] Part2. 데이터 모델과 성능](/assets/img/development/database/2023-01-09/sqld_core_summary_cover.png)
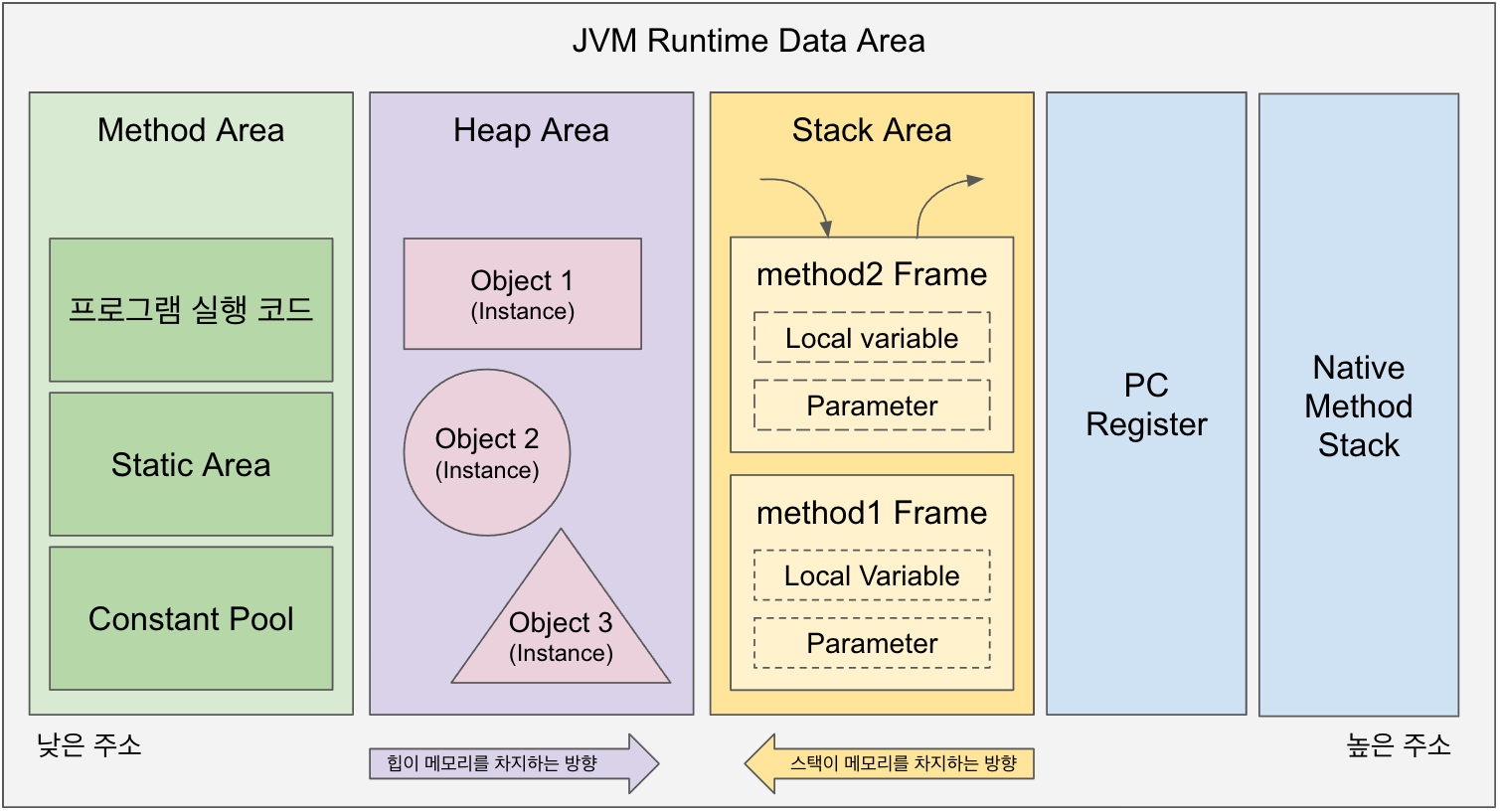
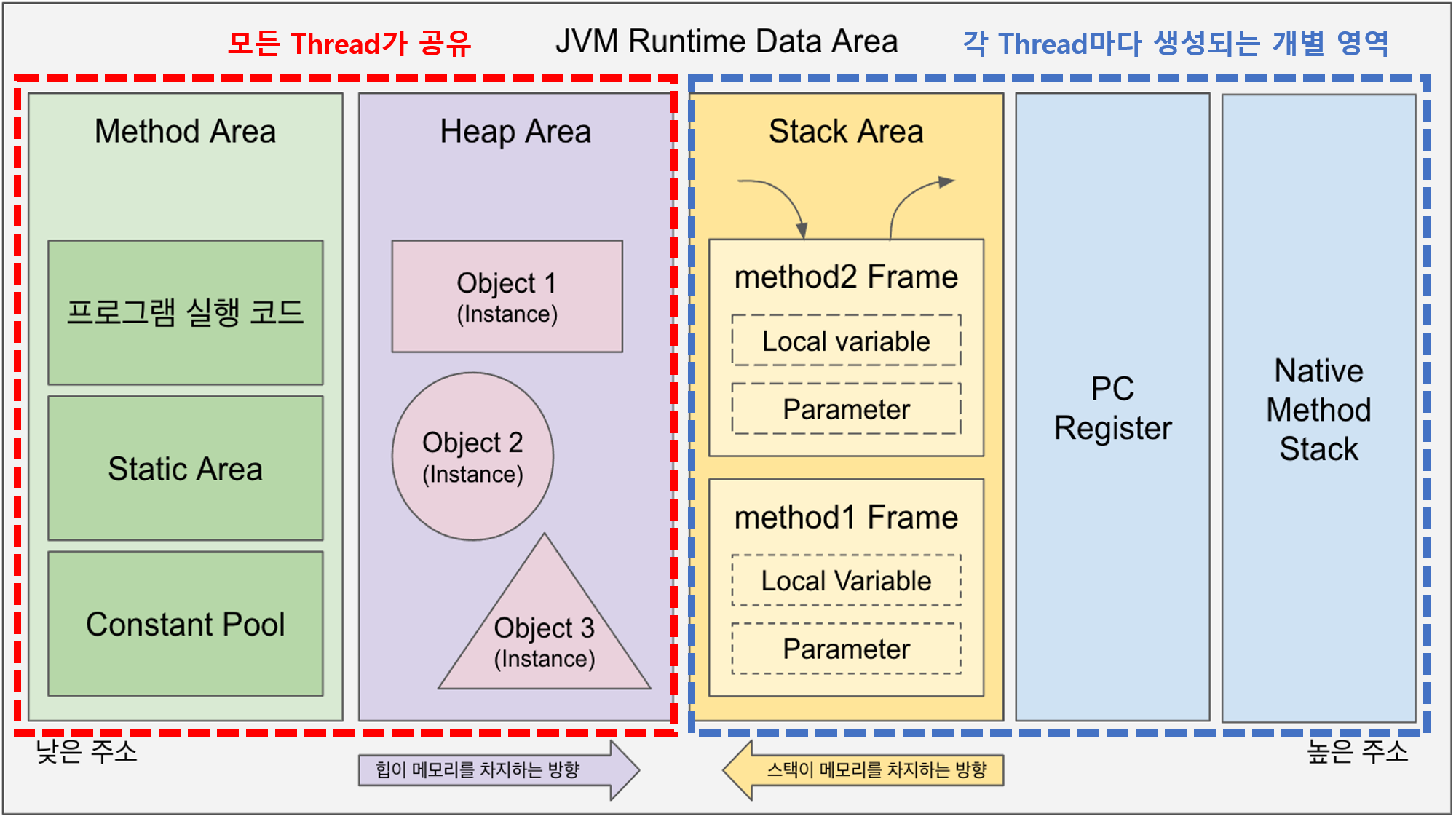
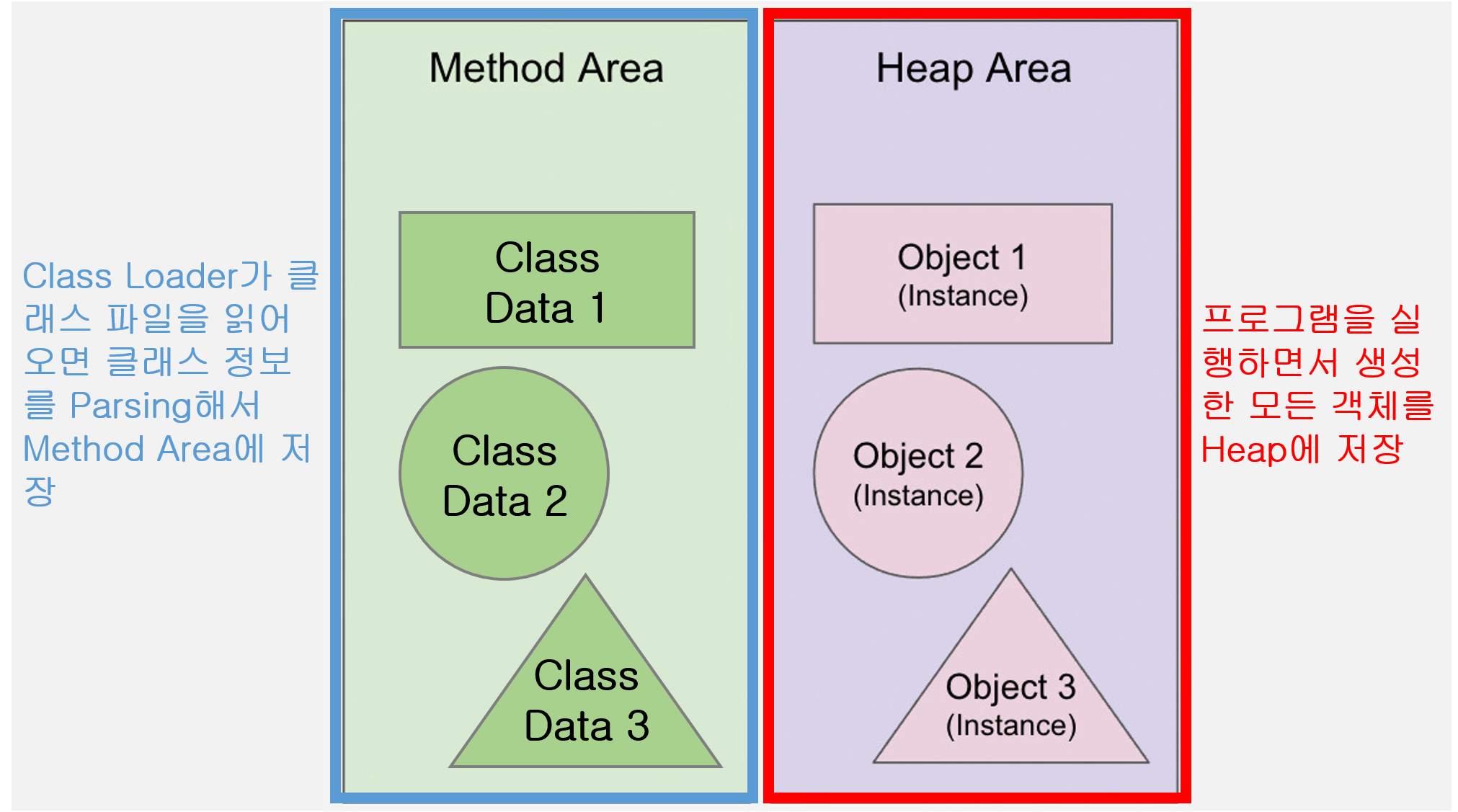
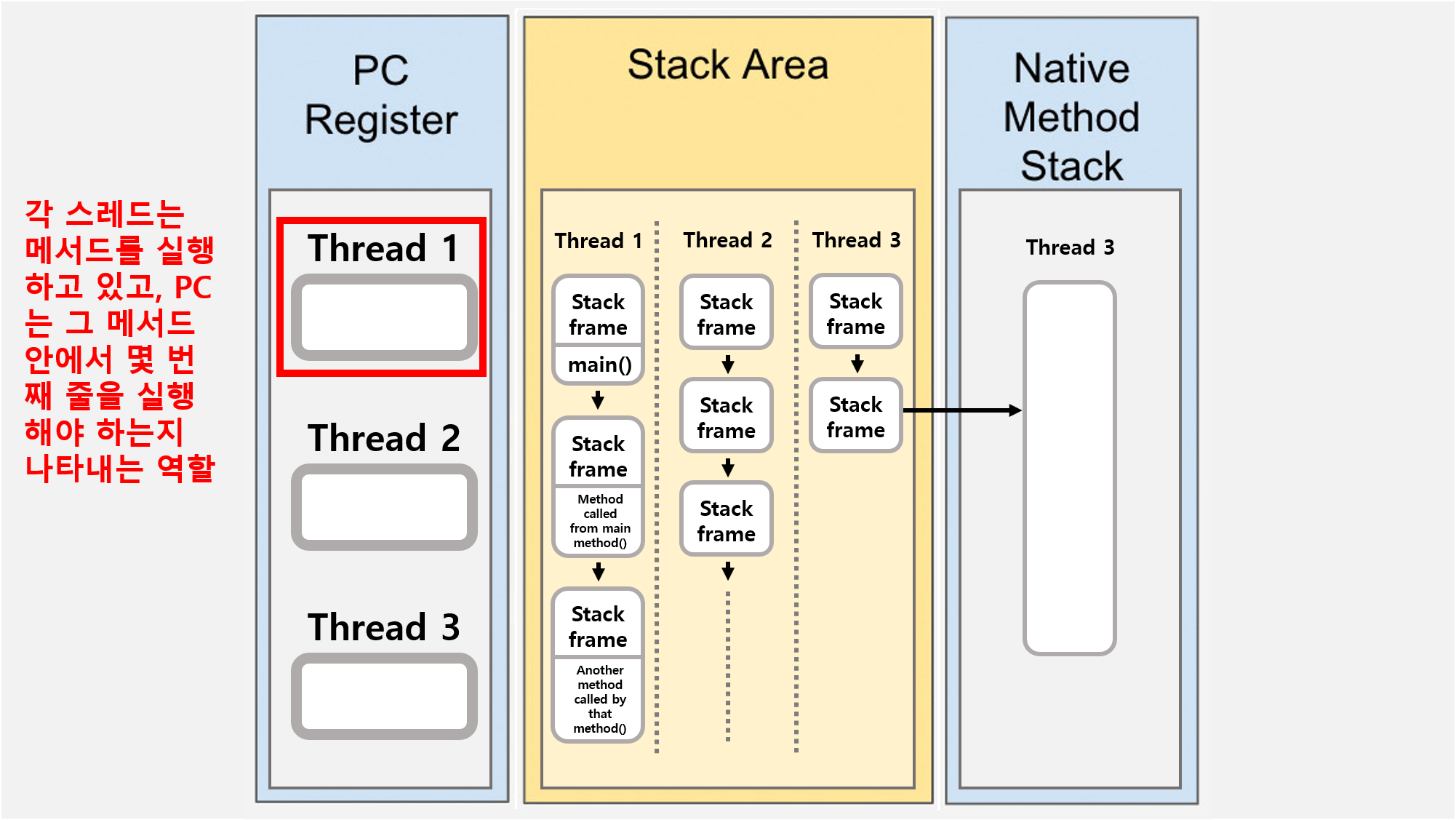
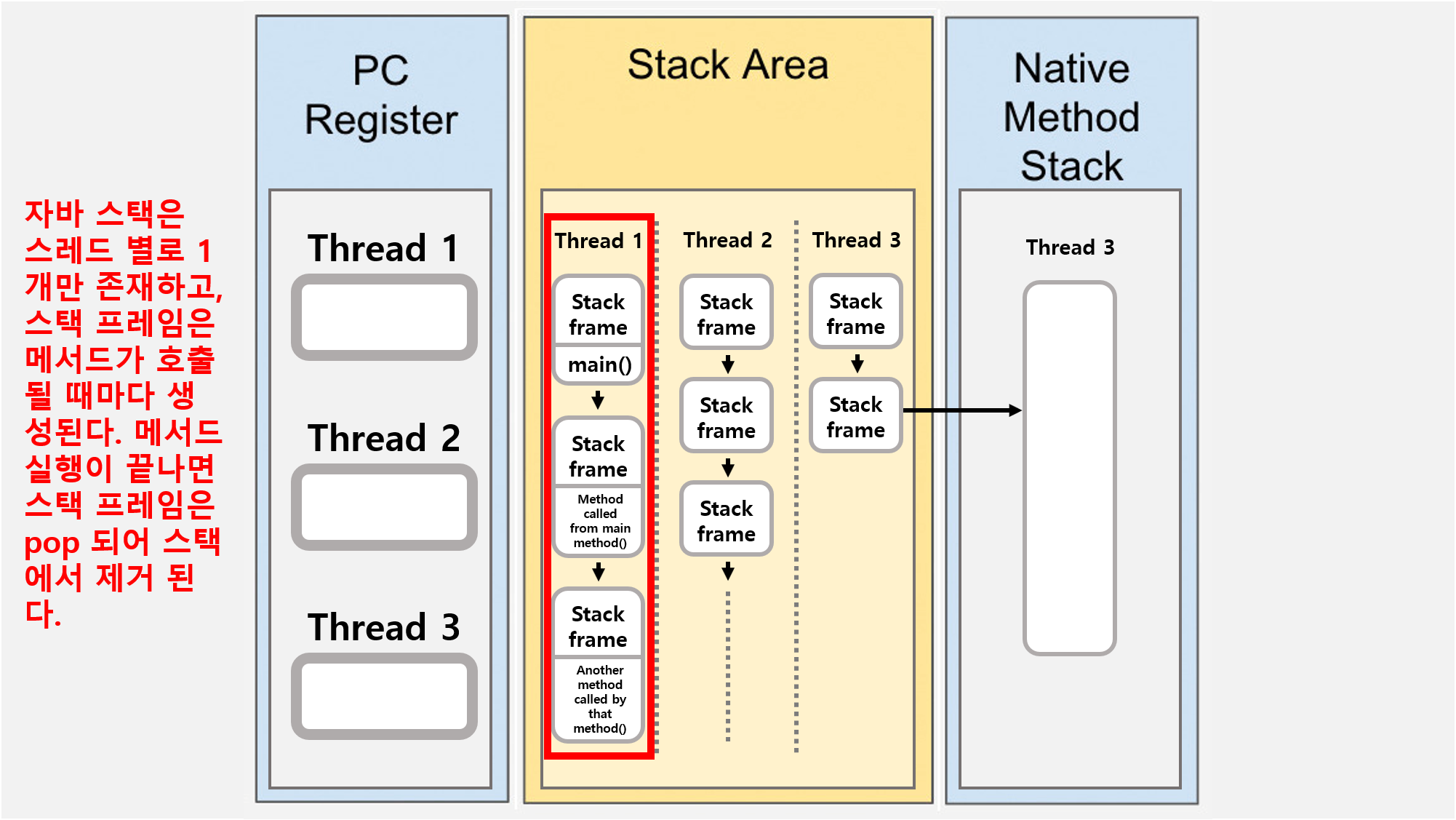
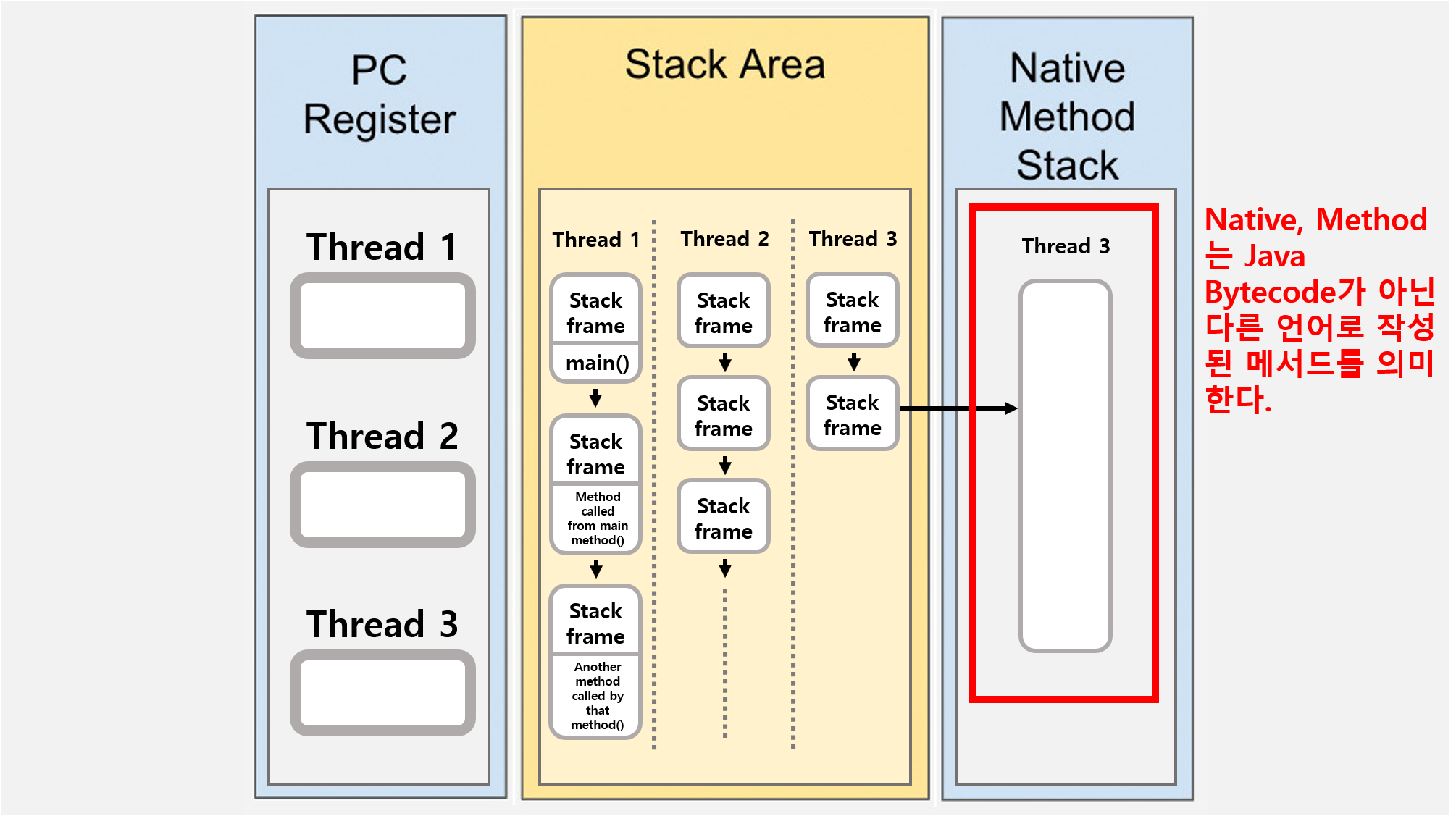
![[Java] JVM Stack & Heap](/assets/img/development/server/2023-01-02/jvm_stack_heap_cover.png)
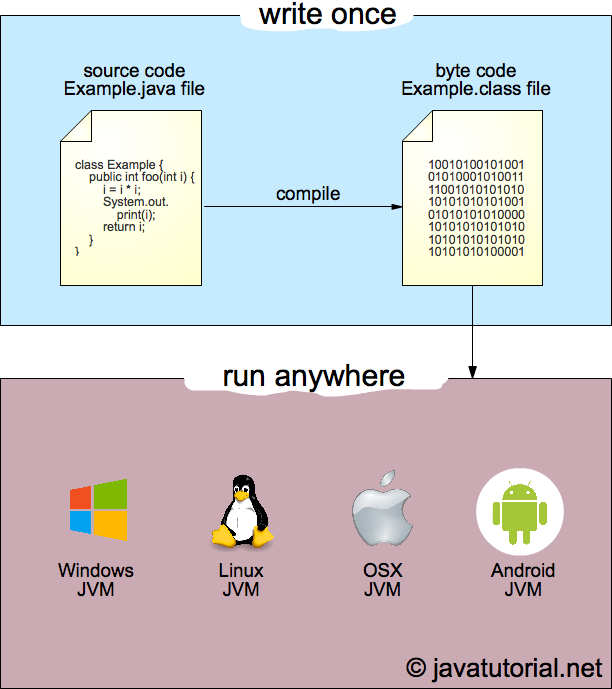
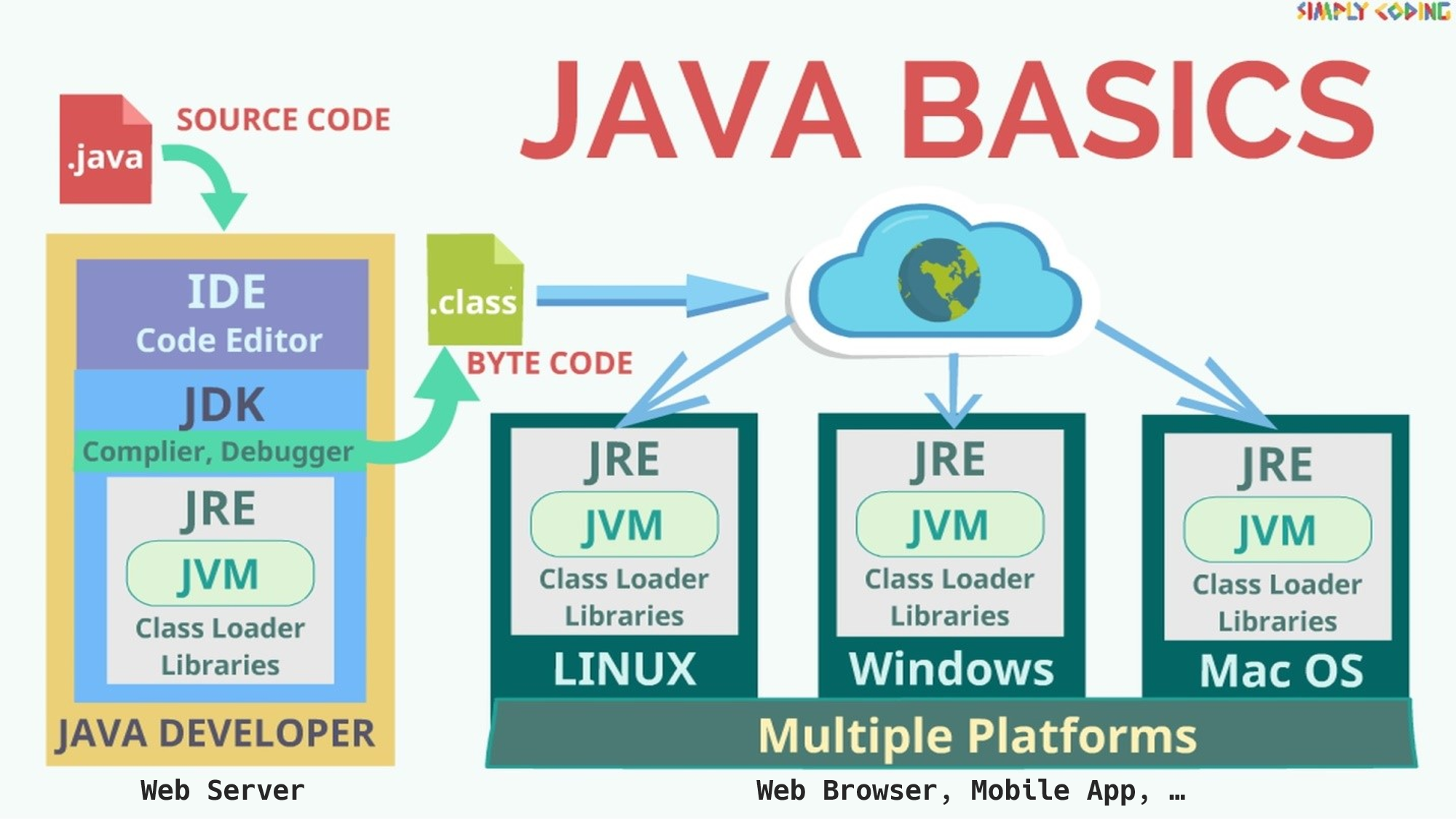
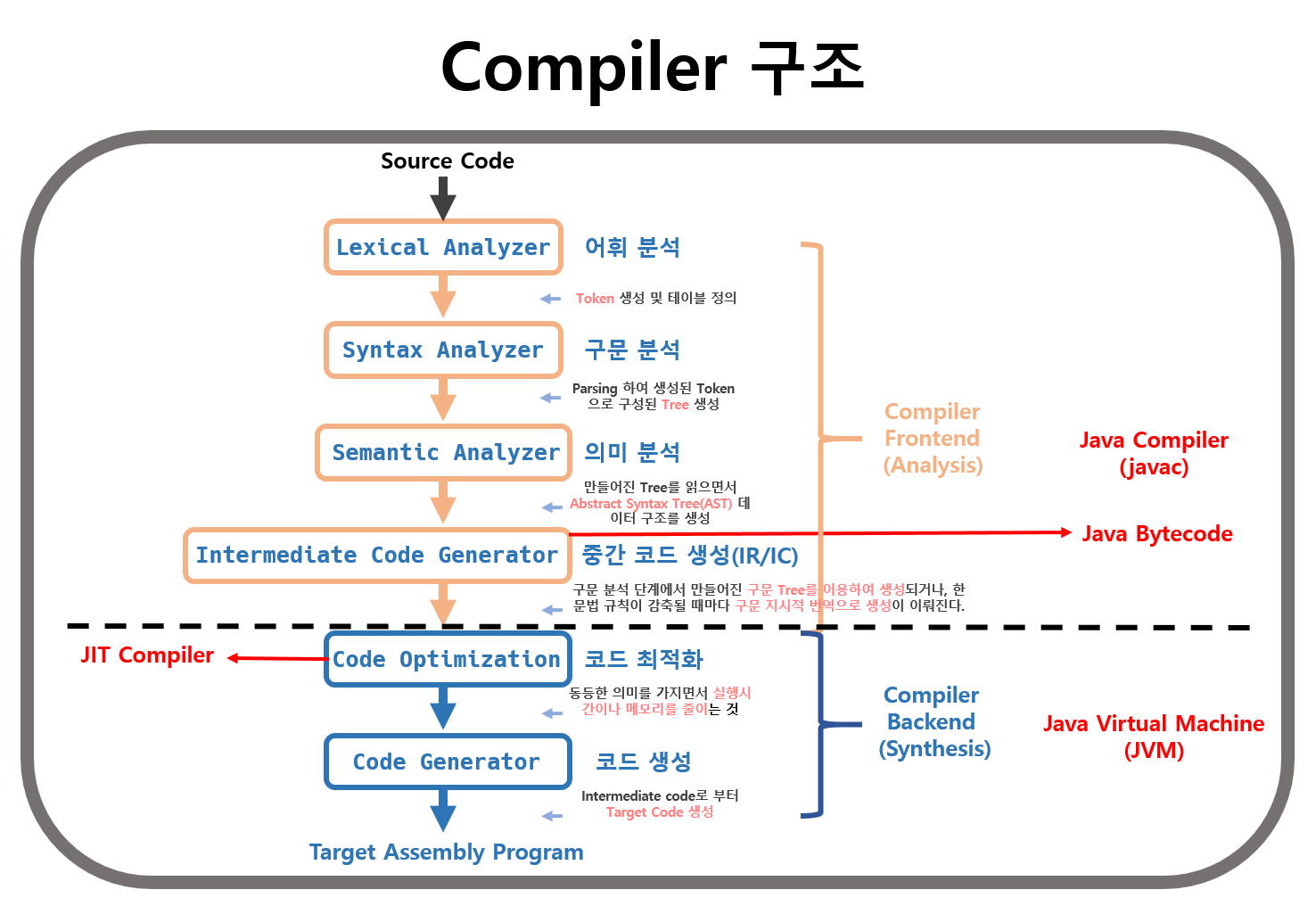
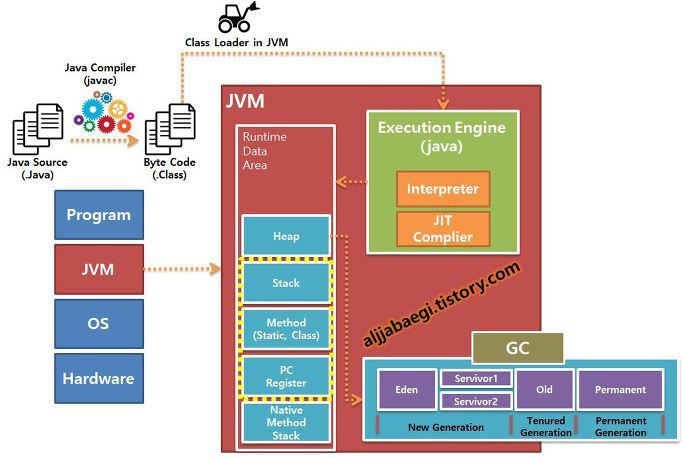
![[SQL] SQL과 NoSQL의 차이](/assets/img/development/database/2022-12-29/sql_vs_nosql_cover.png)